

%201%20(1).webp)

Enterprise‑Ready AI Gateway & Agentic Deployment Platform — Secure, Scalable, Governed.
On-prem, VPC, hybrid, or public cloud












Govern, Deploy, Scale & Trace Agentic AI in One Unified Platform
.svg)
Orchestrate Agentic AI with AI Gateway
Enable intelligent multi-step reasoning, tool usage, and memory with full control and visibility across your AI agents and workflows.
AI Gateway
Manage agent memory, tool orchestration, and action planning through a centralized protocol that supports complex, context-aware workflows.

MCP & Agents Registry
Maintain a structured, discoverable registry of tools and APIs accessible to agents, complete with schema validation and access control.
.webp)
Prompt Lifecycle Management
Version, manage, and monitor prompts to ensure high-quality, repeatable behavior across agents and use cases.
Deploy and Scale Any Agentic AI Workload
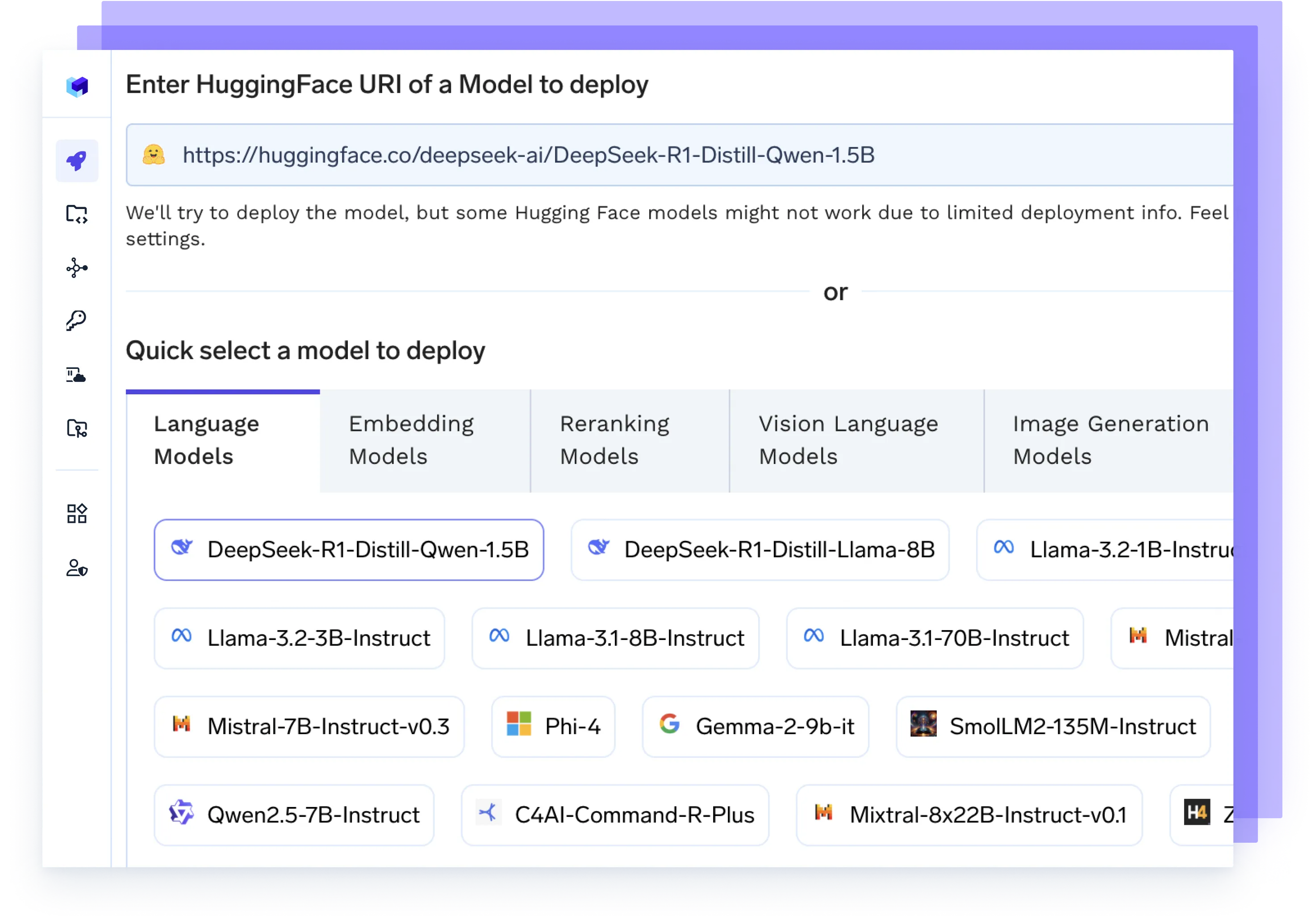
Host any AI Model
Run any LLM, embedding model, or custom models using high-performance backends like vLLM, TGI, or Triton — optimized for speed and scale.
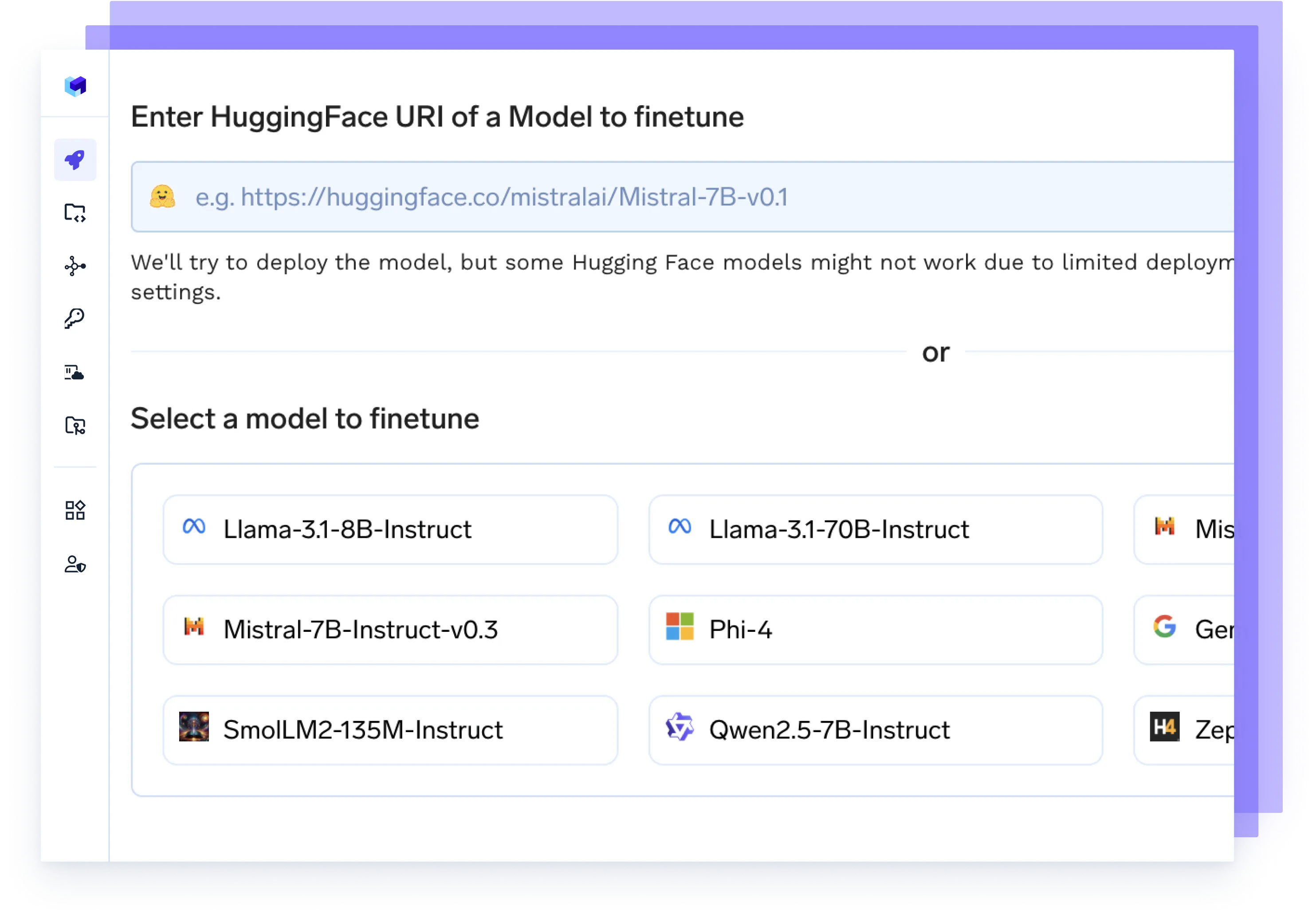
Finetune Any Model
Launch fine-tuning jobs on your data, track experiments, and deploy updated checkpoints directly to production — all in one flow.
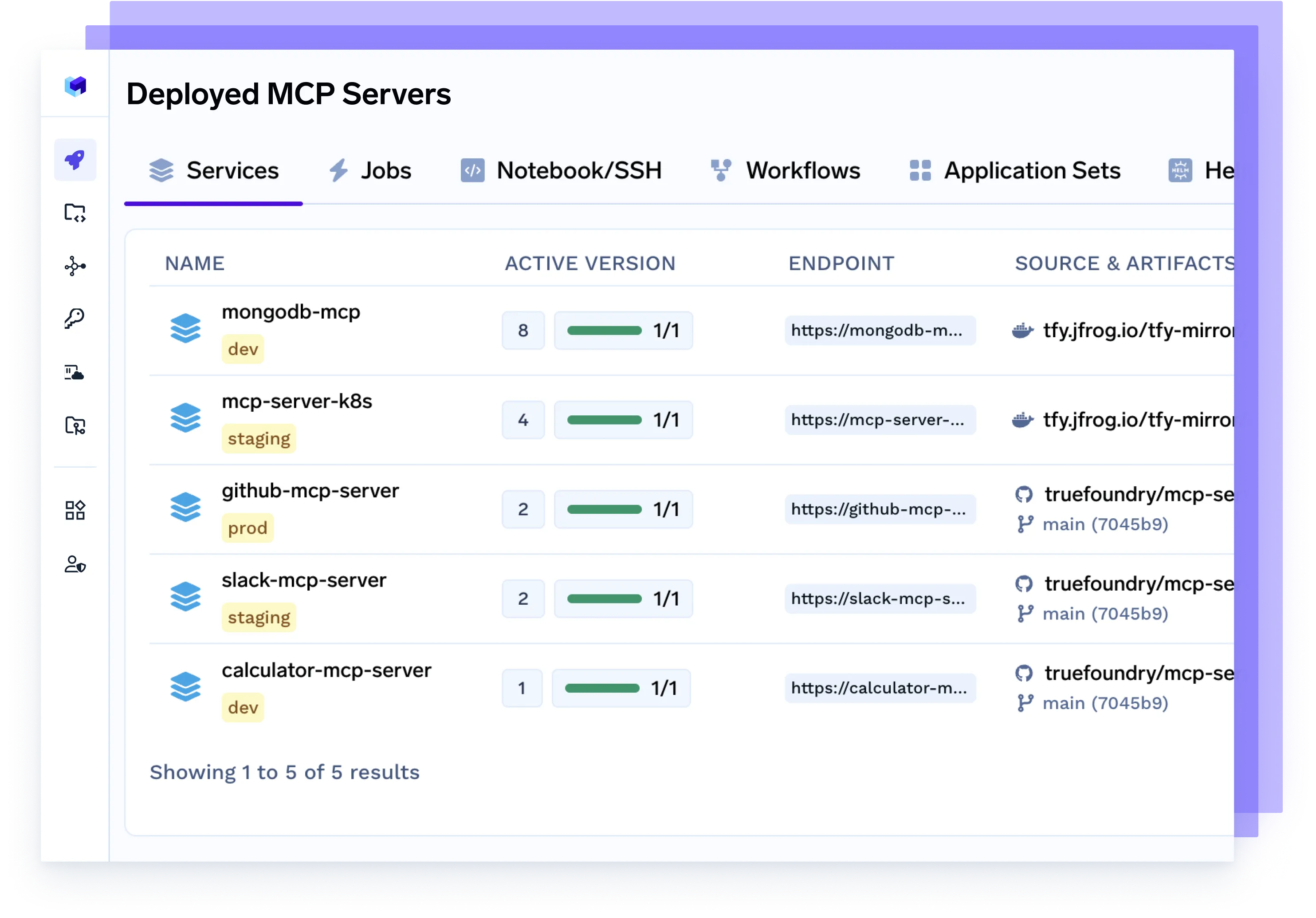
Deploy MCP Server
Provision dedicated Model Control Protocol (MCP) servers to manage agent traffic, scale model access, enforce rate limits, and isolate workloads by team or project.
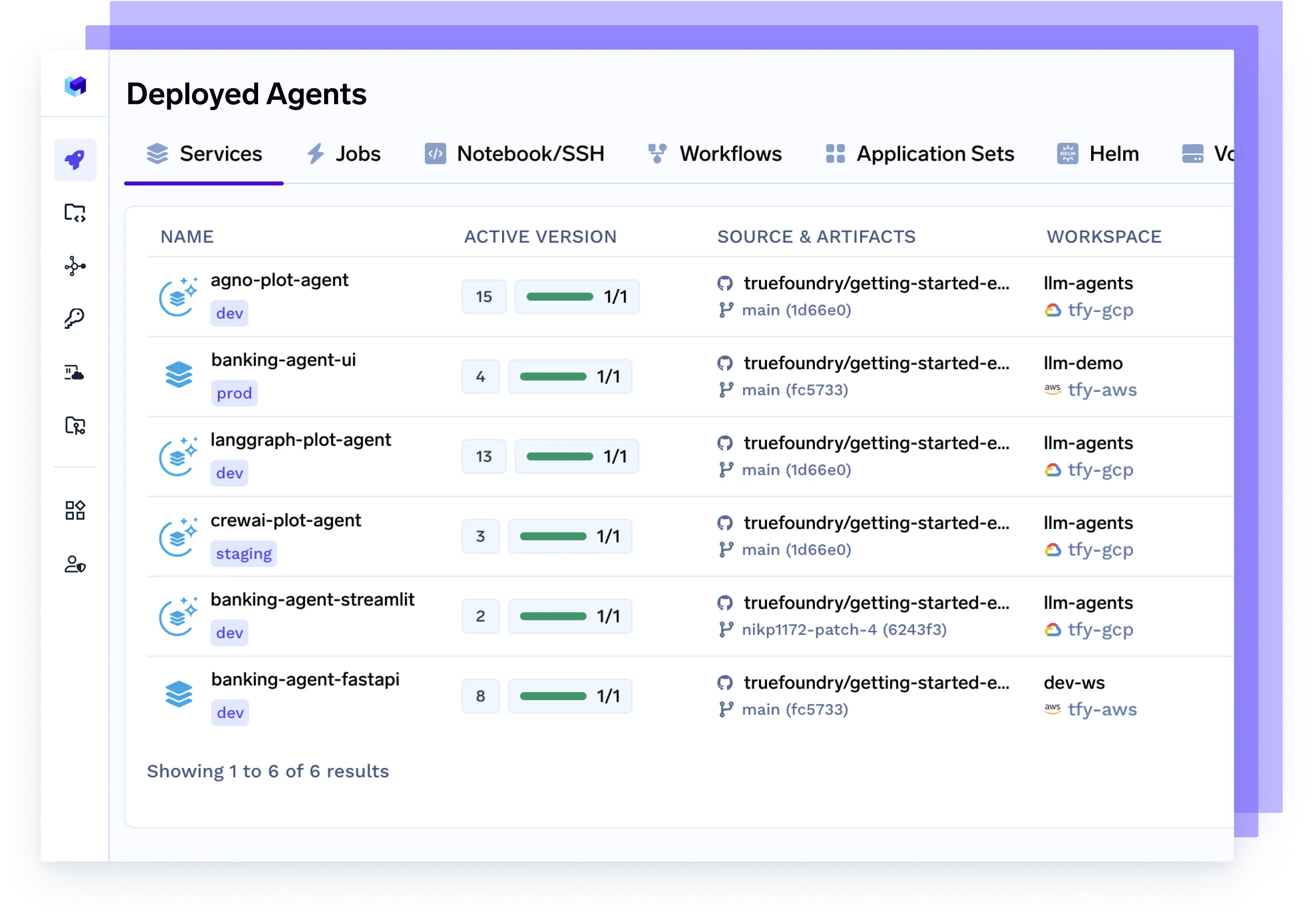
Deploy Any Agent, Any Framework
Seamlessly serve agents built with Langgraph, CrewAI, AutoGen, or your own orchestration — fully containerized, observable, and production-ready.
VPC, on-prem, air-gapped, or across multiple clouds.
No data leaves your domain. Enjoy complete sovereignty, isolation, and enterprise-grade compliance wherever TrueFoundry runs.


Enterprise-Ready
Your data and models are securely housed within your cloud / on-prem infrastructure


Compliance & Security
SOC 2, HIPAA, and GDPR standards to ensure robust data protectionGovernance & Access Control
SSO + Role-Based Access Control (RBAC) & Audit LoggingEnterprise Support & Reliability
24/7 support with SLA-backed response SLAs
Observe Agents and Underlying Infrastructure
Framework-agnostic tracing for everything from prompt execution to GPU performance.
Full Agent Observability
Trace every step from prompt to tool/model execution with metrics, latency, and outcomes
.webp)
Seamless Integration with Internal Tools
OpenTelemetry-compliant; plug into Grafana, Datadog, Prometheus, or your preferred observability stack




Infra Observability (GPU, CPU, Cluster)
Monitor resource usage across cloud/on-prem — including GPU memory, node health, and scaling behavior
.webp)
Govern and Enforce Compliance Across Enterprise-Grade AI
Establish trust and operational discipline with robust access controls, policy enforcement, and full-stack observability - natively integrated from day one.
.webp)
Granular Role-Based Access Control (RBAC)
Precisely control who can access models, environments, or APIs based on teams, roles, and functions.
.webp)
Immutable Audit Logging
Record all activity including model usage, user access, and configuration changes to ensure complete audit readiness.

Compliance-Ready Architecture
Built to meet the highest standards of security and compliance including SOC 2, HIPAA, and GDPR.
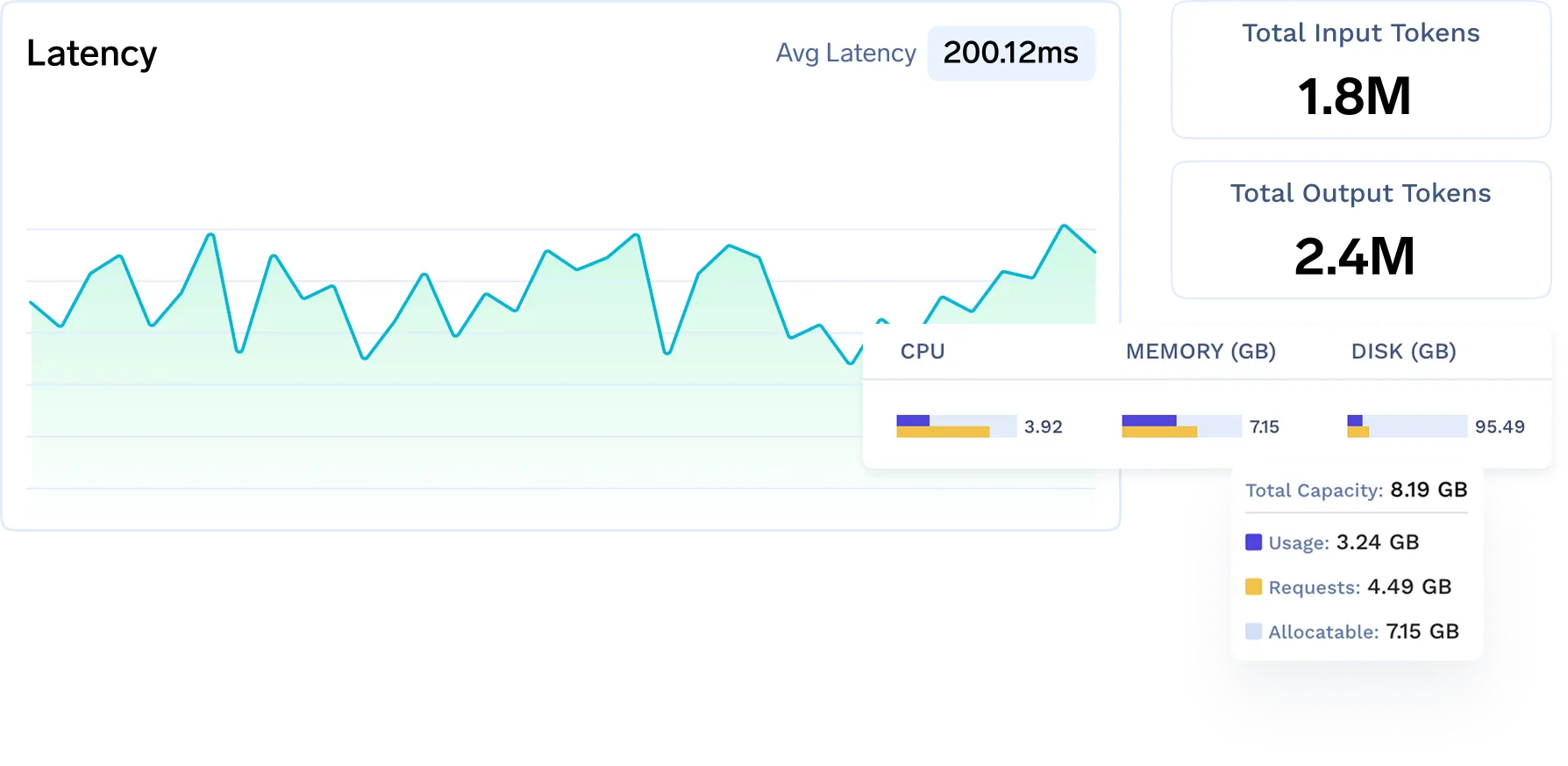
Unified Monitoring and Alerting
Track latency, throughput, token usage, costs, and GPU utilization across your AI stack via centralized dashboards and alerts.

Real-Time Policy Enforcement
Enforce policies related to data residency, usage quotas, rate limits, and cost control dynamically as workloads run.
We Envision an AI-Optimized & Management-Free AI Infrastructure
Automated Resource Optimization Without Operational Overhead

GPU Orchestration and Autoscaling
Automatically schedule and scale GPU workloads to match demand, optimizing performance without overprovisioning.
Fractional GPU Support
(MIG and Time Slicing)
Enable cost-effective sharing of GPU resources across multiple workloads using NVIDIA MIG and time slicing.
Real-Time Resource
Optimization
Continuously adjust CPU and memory allocations based on actual traffic and compute needs.
Automated Infrastructure Rightsizing
Detect and correct overprovisioned infrastructure to reduce cloud waste while maintaining SLAs and model performance.
Real Outcomes at TrueFoundry
Why Enterprises Choose TrueFoundry






3x
faster time to value with autonomous LLM agents
80%
higher GPU‑cluster utilization after automated agent optimization

Aaron Erickson
Founder, Applied AI Lab
TrueFoundry turned our GPU fleet into an autonomous, self‑optimizing engine - driving 80 % more utilization and saving us millions in idle compute.
5x
faster time to productionize internal AI/ML platform
50%
lower cloud spend after migrating workloads to TrueFoundry

Pratik Agrawal
Sr. Director, Data Science & AI Innovation
TrueFoundry helped us move from experimentation to production in record time. What would've taken over a year was done in months - with better dev adoption.
80%
reduction in time-to-production for models
35%
cloud cost savings compared to the previous SageMaker setup
.webp)
Vibhas Gejji
Staff ML Engineer
We cut DevOps burden and simplified production rollouts across teams. TrueFoundry accelerated ML delivery with infra that scales from experiments to robust services.
50%
faster RAG/Agent stack deployment
60%
reduction in maintenance overhead for RAG/agent pipelines
.webp)
Indroneel G.
Intelligent Process Leader
TrueFoundry helped us deploy a full RAG stack - including pipelines, vector DBs, APIs, and UI—twice as fast with full control over self-hosted infrastructure.
60%
faster AI deployments
~40-50%
Effective Cost reduction of across dev environments
.webp)
Nilav Ghosh
Senior Director, AI
With TrueFoundry, we reduced deployment timelines by over half and lowered infrastructure overhead through a unified MLOps interface—accelerating value delivery.
<2
weeks to migrate all production models
75%
reduction in data‑science coordination time, accelerating model updates and feature rollouts
.webp)
Rajat Bansal
CTO
We saved big on infra costs and cut DS coordination time by 75%. TrueFoundry boosted our model deployment velocity across teams.
Integrations
Framework-agnostic integrations for everything from low-code agent builders to GPU-level performance evaluation.


- © 2022 ENSEMBLE Technologies





Subscribe to our newsletter
The latest news, articles, and resources sent to your inbox
© 2025 All rights reserved.


