November 5, 2025
|
5 min read

Updated: December 12, 2024
.webp)
Blazingly fast way to build, track and deploy your models!
The world of artificial intelligence (AI) is rapidly evolving, moving beyond isolated models to interconnected systems that collaboratively solve complex, multi-faceted problems.A Compound AI system is defined as a system that addresses AI tasks using multiple interacting components, which can include various AI models, data retrieval mechanisms, and external tools. These components work collaboratively to achieve specific goals, allowing for a more nuanced and effective approach to problem-solving.
Common examples of compound systems include:
This design principle, championed by institutions like the Berkeley AI Research (BAIR) lab, emphasizes the importance of system architecture in tackling complex AI tasks. Rather than relying solely on large, monolithic models, compound AI systems leverage various specialized components to enhance performance, flexibility, and adaptability.
A recent video from Stanford outlined the evolution of scaling in AI across different eras, focusing on how the emphasis has shifted from model-centric development to system-level integration
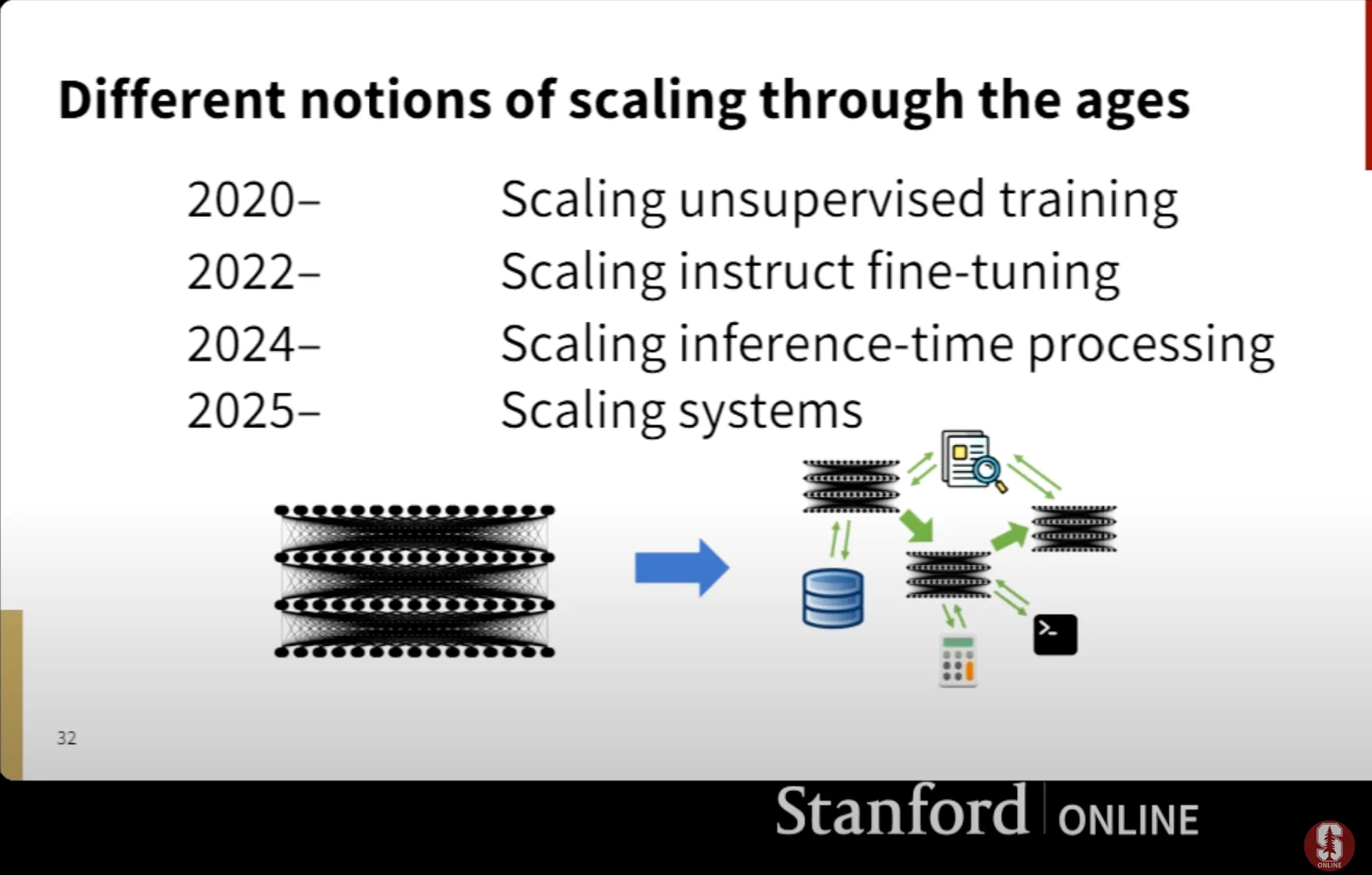
Scaling Unsupervised Training (2020–) - This began with the release of GPT-3, which demonstrated the power of large-scale unsupervised training.Unsupervised training involves exposing models to vast amounts of unstructured data, such as text from the internet, to allow them to generalize patterns without specific task labels.
Scaling Instruct Fine-Tuning (2022–) - This era was characterized by the introduction of applications like ChatGPT, which utilized instruction tuning and fine-tuning techniques. Instruct fine-tuning involves providing input-output pairs (e.g., question-answer datasets) to adjust pre-trained models for specific skills.
Scaling Inference-Time Processing (2024–) - This refers to innovations aimed at optimizing the real-time use of AI models during inference. It focuses on enhancing efficiency, response times, and adaptability with multi-step reasoning, "chain-of-thought" prompting, memory optimization, etc
Scaling Systems (2025–) - Moving beyond large language models (LLMs) to compound systems, transitioning from standalone models to integrated systems combining models, tools, APIs, and infrastructure.
Infrastructure challenges
Compound AI systems require the seamless ability to shift between GPUs, CPUs, and other specialized hardware based on the specific needs of each component. For instance, a vision model may demand GPU acceleration, while a database query might rely on CPU efficiency. Determining the optimal resource configurations for each workload and dynamically adapting infrastructure as needs evolve is critical. Regularly monitoring and fine-tuning infrastructure ensures the system operates efficiently and cost-effectively, even as workloads or model requirements change.
Ensuring compound AI systems scale efficiently requires implementing auto-scaling mechanisms that dynamically allocate resources based on workload demands. This involves monitoring system usage, such as CPU, GPU, memory, and network bandwidth, to predict and respond to changes in real time.
Prohibitive costs
Running multiple AI models simultaneously, particularly in real-time, leads to high compute, storage, and cloud costs. Establishing an infrastructure that enables the detection of resource inefficiencies and supports seamless switching between configurations is essential. Leveraging strategies such as spot compute, fractional GPUs, and auto-scaling ensures cost-effectiveness while maintaining optimal performance.
Integrating with existing infrastructure
Modern infrastructures are often composed of highly distributed architectures, multi-cloud environments, and specialized tools tailored for specific workflows. These setups, while advanced, introduce complexities when adding new AI components that must work harmoniously within an already intricate ecosystem.
Faster Experimentation
Faster experimentation is a critical enabler for the success of compound AI systems, allowing teams to iterate quickly, test new ideas, and optimize performance.
Modular architecture allows teams to swap models, adjust pipelines, or integrate new algorithms with minimal disruption.Automation also plays a significant role, with tools like CI/CD pipelines ensuring seamless deployment and testing of updated components.
Read our detailed blog on how to integrate TrueFoundry with MongoDB.
Accelerate Time-to-Market with MongoDB Atlas
MongoDB’s native vector search capabilities simplify the implementation of sophisticated Retrieval-Augmented Generation (RAG) workflows by embedding vector search within an operational database. This eliminates the need for separate vector databases, reducing infrastructure complexity and enabling faster deployment.
Iterate Quickly with Flexibility
MongoDB’s document-based data model is inherently flexible, making it ideal for storing multimodal data types like text, images, and vector embeddings. Developers can onboard new data types without downtime or schema redesign, enabling faster tuning, optimization, and iteration for GenAI-powered applications.
Enterprise-Ready Scalability and Security
MongoDB Atlas provides enterprise-grade fault tolerance, horizontal scaling, and secure-by-default features such as queryable encryption. Its fully managed, serverless architecture supports elastic scaling and consumption-based pricing, ensuring cost-effective operations for even the most demanding workloads.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.






.webp)
.webp)
.webp)
.webp)
.webp)





.webp)
.webp)