












LLMOps for Model Serving & Inference
.webp)
- Deploy any open-source LLM within your LLMOps pipeline using pre-configured, performance-tuned setups
- Seamlessly integrate with Hugging Face, private registries, or any model hub—fully managed within your LLMOps platform
- Leverage industry-leading model servers like vLLM and SGLang for low-latency, high-throughput inference
- Enable GPU autoscaling, auto shutdown, and intelligent resource provisioning across your LLMOps infrastructure.
.webp)
Serve any LLM with high-performance model servers like vLLM and SGLang, powered by GPU auto-scaling and cost-efficient LLMOps infrastructure.
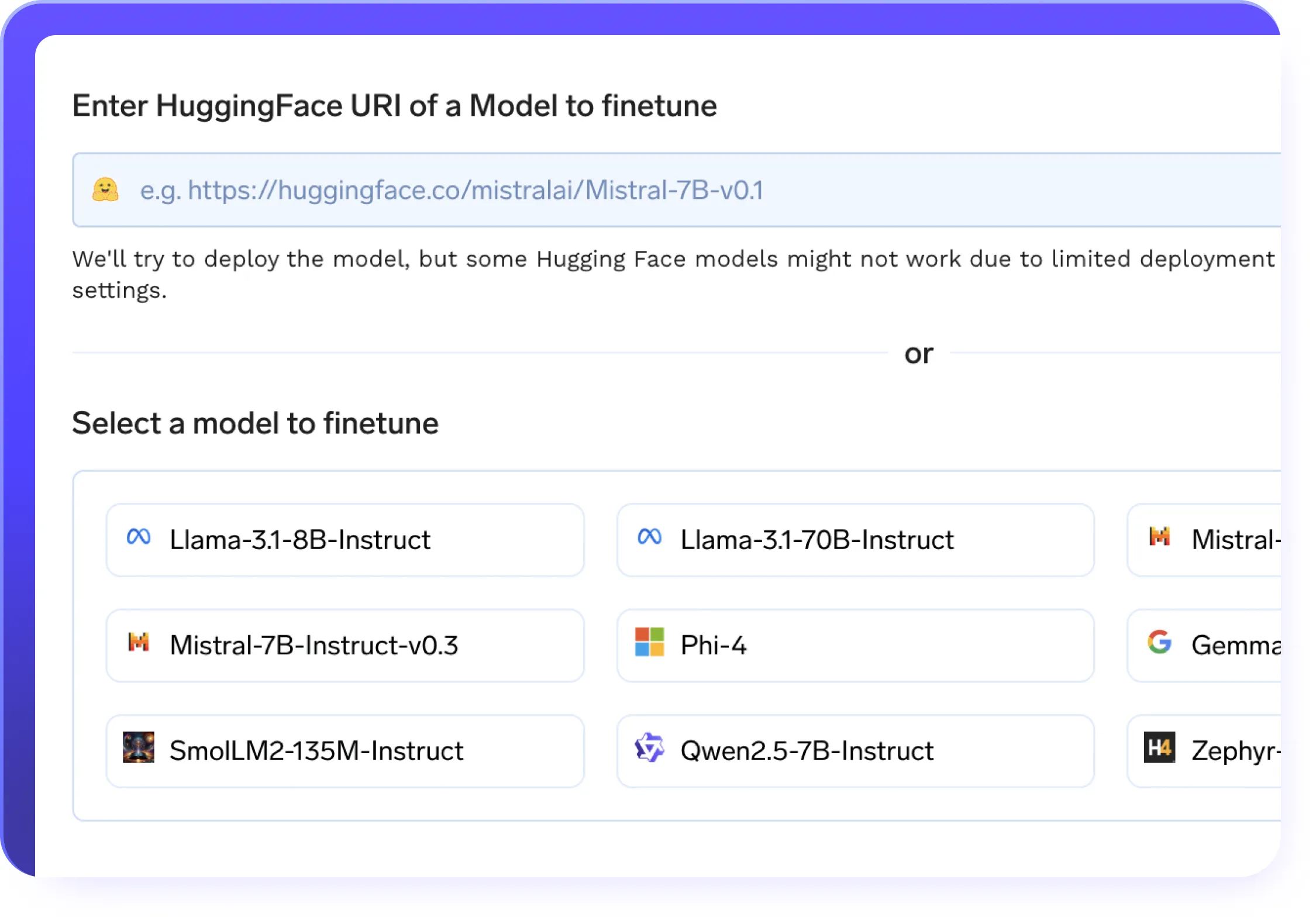
Efficient Finetuning
- No-code & full-code fine-tuning support on custom datasets
- LoRA & QLoRA for efficient low-rank adaptation
- Resume training seamlessly with checkpointing support across your LLMOps pipelines
- One-click deployment of fine-tuned models with best-in-class model servers
- Automated training pipelines with built-in experiment tracking baked into your LLMops workflows
- Distributed training support for faster, large-scale model optimization
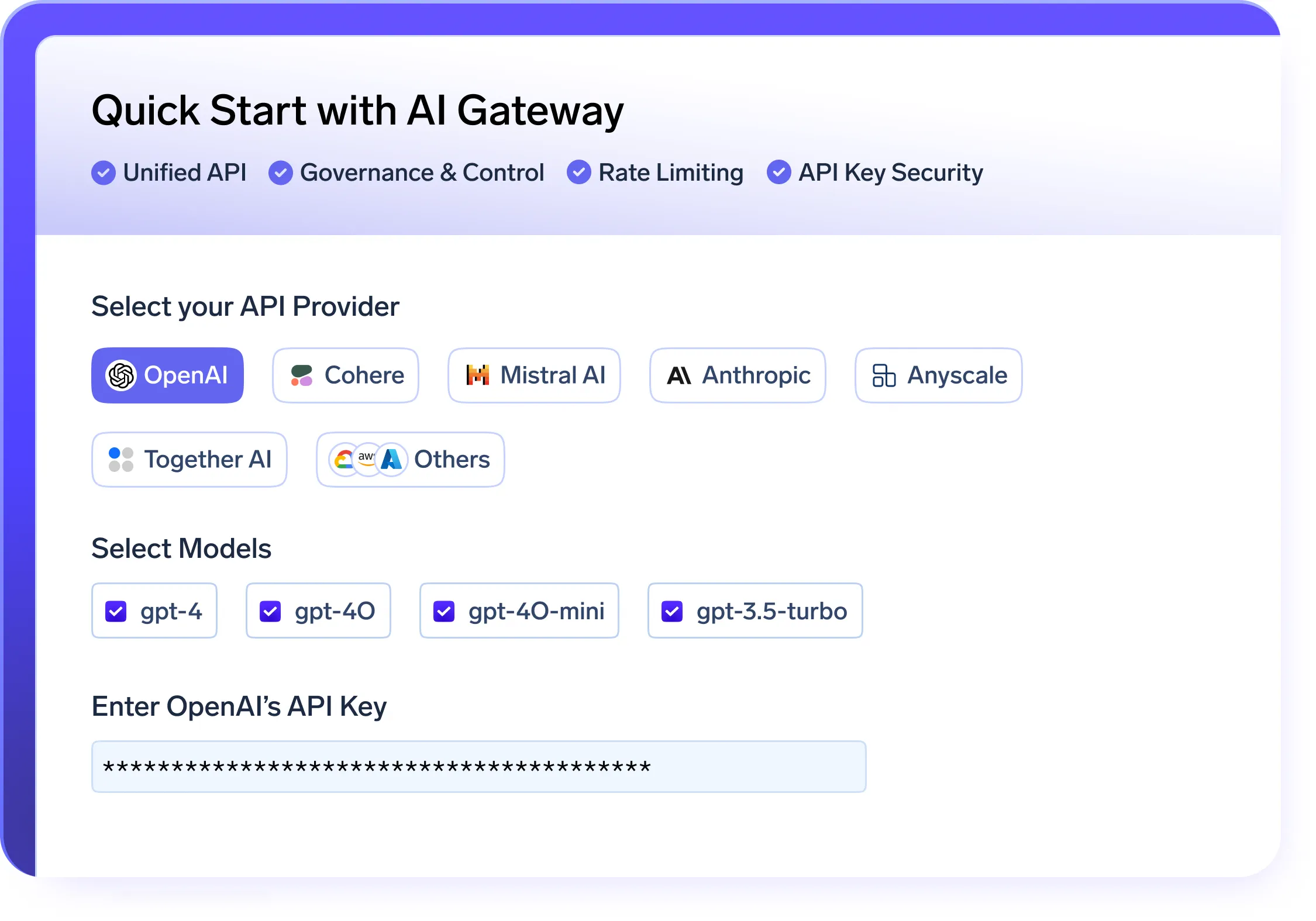
Govern AI usage with an AI Gateway that unifies model access, enforces quotas, and ensures observability and safety.
Secure and Scalable AI Gateway
- A unified API layer to serve and manage models across OpenAI, LLaMA, Gemini, and other providers
- Built-in quota management and access control to enforce secure, governed model usage within your LLMOps platform
- Real-time metrics for usage, cost, and performance to improve LLMOps observability
- Intelligent fallback and automatic retries to ensure reliability across your LLMOps pipelines
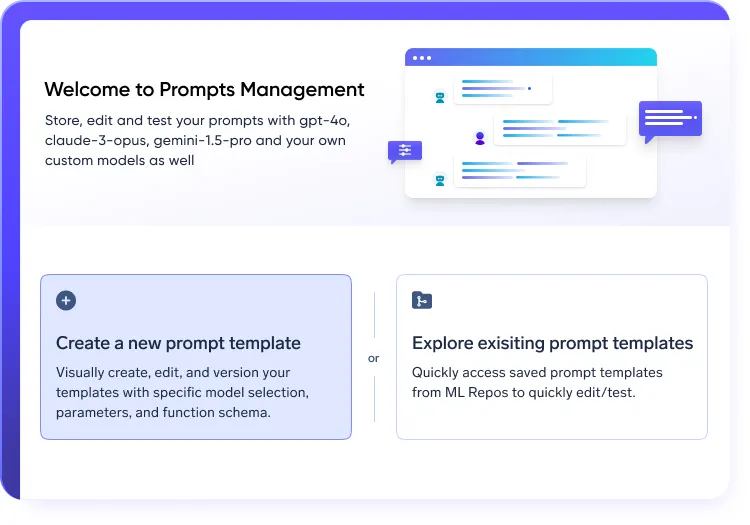
Structured prompt workflows in LLMOps stack
- Experiment and iterate using version-controlled prompt engineering
- Run A/B tests across models to optimize performance
- Maintain full traceability of prompt changes within your LLMOps platform
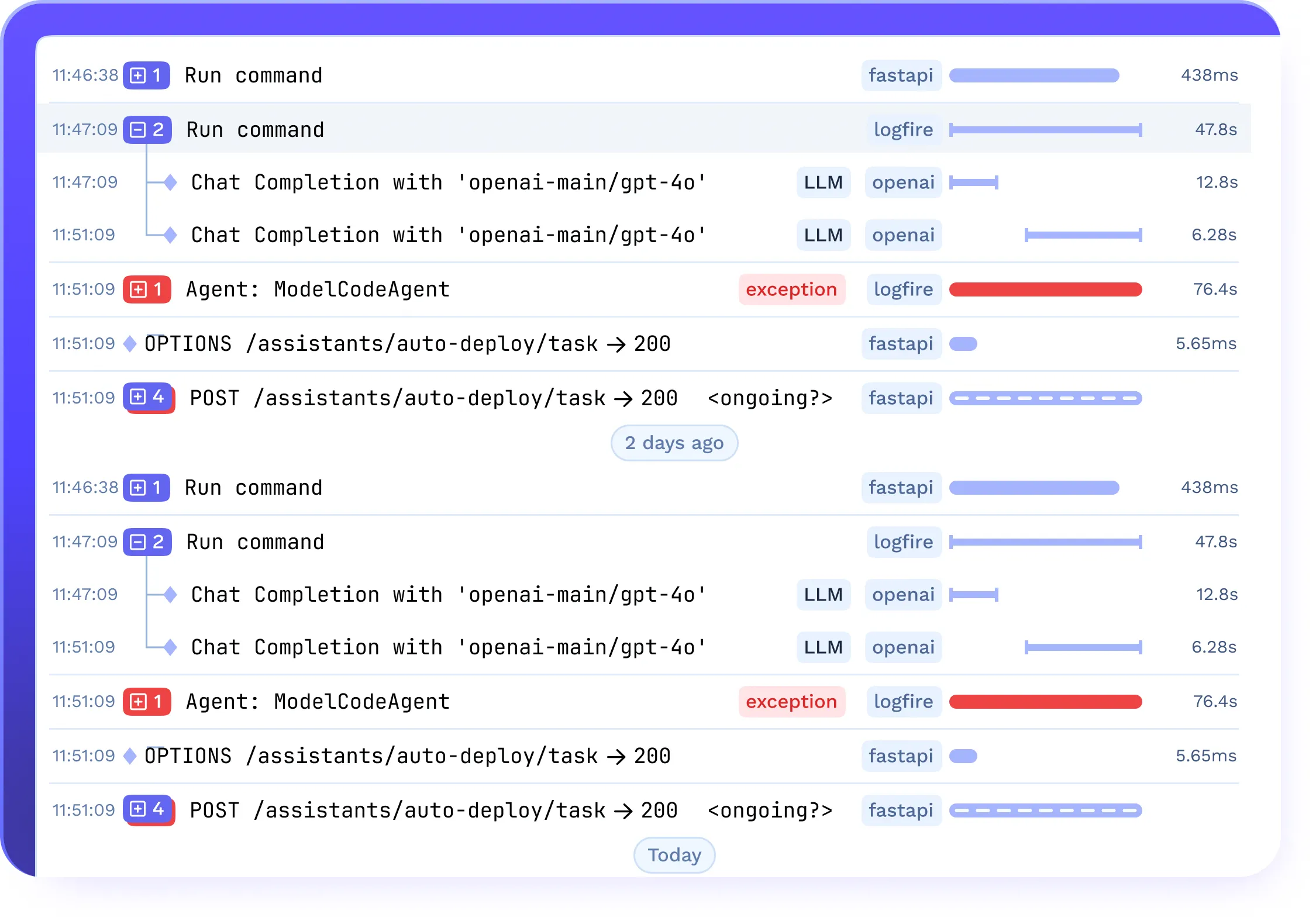
Tracing & Guardrails for LLMOps Workflows
- Capture full traces of prompts, responses, token usage, and latency
- Monitor performance, completion rates, and anomalies
- Integrate with guardrails for PII detection and content moderation in LLMOps pipelines
One click RAG deployment
- Deploys all RAG components in a single click, including VectorDB, embedding models, frontend, and backend
- Configurable infrastructure to optimize storage, retrieval, and query processing
- Handle growing document bases with cloud-native LLMOps scalability
Manage agent lifecycles - from deployment to observability - across any framework, powered by your LLMOps platform.
LLMOps for AI Agent Lifecycle Management
- Run and scale agents across any framework using your LLMOps infrastructure
- Support for LangChain, AutoGen, CrewAI, and custom agents
- Framework-agnostic agent orchestration with built-in LLMOps monitoring
- Support for multi-agent orchestration, enabling agents to interact, share context, and execute tasks autonomously
.webp)
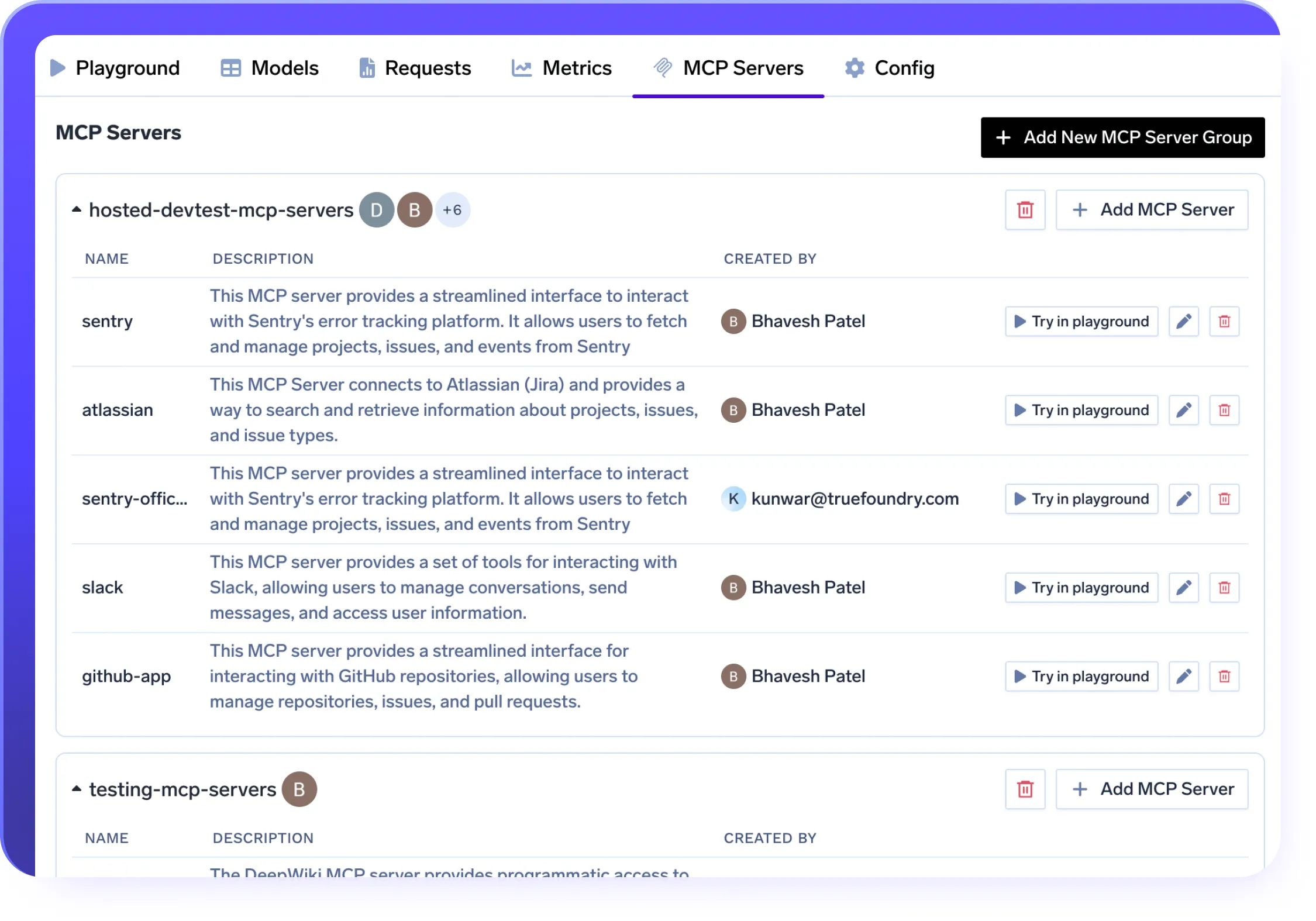
MCP Server Integration in Your LLMOps Stack
- Securely connect LLMs to tools like Slack, GitHub, and Confluence using the MCP protocol
- Deploy MCP Servers in VPC, on-prem, or air-gapped setups with full data control
- Enable prompt-native tool use without wrappers—fully integrated into your LLMOps stack
- Govern access with RBAC, OAuth2, and trace every call with built-in observability
Enterprise-Ready
Deploy a secure AI gateway that keeps your data and models within your cloud / on-prem infrastructure.


Compliance & Security
SOC 2, HIPAA, and GDPR standards to ensure robust data protectionGovernance & Access Control
SSO + Role-Based Access Control (RBAC) & Audit LoggingEnterprise Support & Reliability
24/7 support with SLA-backed response SLAs
Deploy TrueFoundry in any environment
VPC, on-prem, air-gapped, or across multiple clouds.
No data leaves your domain. Enjoy complete sovereignty, isolation, and enterprise-grade compliance wherever TrueFoundry runs

Frequently asked questions
What is LLMOps and why does it matter?
LLMOps (Large Language Model Operations) refers to the practice of managing the full
lifecycle of large language models—from training and fine-tuning to deployment, inference,
monitoring, and governance. LLMOps helps organizations bring GenAI applications into
production reliably and at scale. TrueFoundry provides a production-grade LLMOps platform
that simplifies and accelerates this entire process.
lifecycle of large language models—from training and fine-tuning to deployment, inference,
monitoring, and governance. LLMOps helps organizations bring GenAI applications into
production reliably and at scale. TrueFoundry provides a production-grade LLMOps platform
that simplifies and accelerates this entire process.
How is LLMOps different from traditional MLOps?
While MLOps supports a wide range of ML models, LLMOps is purpose-built for GenAI and
large language models. It includes capabilities like model server orchestration, prompt
management, token-level observability, agent frameworks, and secure API access.
TrueFoundry’s LLMOps platform handles these GenAI-specific workflows natively—unlike
generic MLOps tools.
large language models. It includes capabilities like model server orchestration, prompt
management, token-level observability, agent frameworks, and secure API access.
TrueFoundry’s LLMOps platform handles these GenAI-specific workflows natively—unlike
generic MLOps tools.
Why should I invest in a dedicated LLMOps platform like TrueFoundry?
A dedicated LLMOps platform eliminates the need to stitch together infrastructure, monitoring, and evaluation tools. TrueFoundry enables secure deployment, prompt experimentation, observability, and cost optimization in one platform. This allows teams to move from prototype to production faster while maintaining enterprise governance and reliability.
What are the core features of TrueFoundry’s LLMOps platform?
TrueFoundry’s LLMOps platform integrates version control, B testing, and prompt tuning for every foundation model. Key components of LLMOps include automated hyperparameter tuning and data quality monitoring. These features support complex AI applications by optimizing computational resources and ensuring consistent LLM performance across all data sets.
Can I deploy TrueFoundry’s LLMOps platform on my infrastructure?
Yes. TrueFoundry supports deployment in your VPC, private cloud, or on-premise environment. This ensures full control over sensitive data, compliance with internal security policies, and seamless integration with existing infrastructure while maintaining enterprise-grade scalability and performance.
How does LLMOps improve observability and debugging?
This LLMOps platform enhances model performance through performance metrics and real-time data analysis. Engineers use gisting evaluation and bilingual evaluation understudy metrics to debug ML models. By tracking human feedback and model operations, you gain deep visibility into how artificial intelligence behaves in live production environments.
Is TrueFoundry’s LLMOps platform secure and compliant?
Our enterprise LLMOps platform prioritizes enterprise AI security through RBAC and SOC 2 compliance. We ensure data quality and protect sensitive data using multi-tenant isolation. By integrating continuous integration and strict data preparation protocols, the platform maintains a secure environment for deploying any large language models.
Which models and frameworks are supported in TrueFoundry’s LLMOps platform?
TrueFoundry’s LLMOps platform supports language models like Mistral and LLaMA, alongside traditional ML models. It is framework-agnostic, integrating with hugging face transformers and data science tools. Whether you are using a foundation model or custom AI systems, our platform facilitates seamless model deployment and scaling.
Can I use TrueFoundry’s LLMOps platform to manage multiple teams and projects?
Yes, TrueFoundry’s enterprise LLMOps platform is designed for multi-tenancy, allowing data engineering teams to manage distinct projects. You can monitor computational resources, track costs, and organize data collection for specific tasks. This structure improves the user experience for large organizations scaling their generative AI and data science initiatives.
How fast can I start using TrueFoundry for LLMOps?
You can launch our LLMOps platform in minutes using prebuilt prompt templates and AI development workflows. The platform accelerates data preparation and customer support automation. With automated model operations, your team can quickly move from initial data collection to high-performing production environments with minimal friction.

GenAI infra- simple, faster, cheaper
Trusted by 30+ enterprises and Fortune 500 companies








