

April 17, 2025
|
5 min read


Get instant access to a live TrueFoundry environment. Deploy models, route LLM traffic, and explore the full platform — your sandbox is ready in seconds, no credit card required.









Updated: March 25, 2025




Blazingly fast way to build, track and deploy your models!
When it comes to building, training, and deploying machine learning models at scale, Amazon SageMaker has long been a go-to platform. But in 2026, the MLOps landscape has evolved—and let’s be honest, SageMaker isn’t always the perfect fit for every team or use case. Maybe it's the cost, perhaps it's the learning curve, or maybe you just want something more flexible. Whatever the reason, exploring alternatives can open up new possibilities. So if you're wondering what other tools are out there that can rival or even outperform SageMaker, you’re in the right place. Let’s dive into your top options.

Amazon SageMaker is a fully managed service from AWS that helps developers and data scientists build, train, and deploy machine learning (ML) models quickly and at scale. It was introduced to simplify the often messy, time-consuming ML pipeline and make it more accessible—even for teams without deep ML or DevOps expertise. Think of SageMaker as a one-stop shop for all things ML. It takes care of the heavy lifting involved in model development—from spinning up infrastructure to managing experiments, training at scale, deploying APIs, and even monitoring models in production. Whether you're working on a simple classification task or deploying a massive deep learning model, SageMaker offers a modular, plug-and-play approach to get you from idea to production.
Here’s a quick rundown of what it includes:

Alright, so now that we know what SageMaker is, let’s talk about how it actually works behind the scenes. At its core, SageMaker simplifies the machine learning lifecycle by breaking it down into three main stages: Build, Train, and Deploy—with plenty of helpful features tucked into each.
Build
It all starts in the "build" phase. SageMaker gives you a bunch of tools to prep your data, explore it, and build your models. You can launch Jupyter notebooks directly from the SageMaker console (no local setup needed), and connect them to data stored in S3. Whether you’re using built-in algorithms or writing your own in TensorFlow, PyTorch, or Scikit-learn, you get a fully managed environment ready to go.
It also supports integration with SageMaker Data Wrangler, which helps clean and transform data with a low-code interface. Basically, the build phase is your ML playground—minus the setup headaches.
Train
Once your model code is ready, it’s time to train it. Here’s where SageMaker really shines. You can run training jobs on powerful, scalable compute instances—CPU or GPU—without provisioning anything manually. You define your job configuration (like instance type and count), kick off the training, and SageMaker handles the rest.
Even cooler? SageMaker supports automated model tuning, where it tests different hyperparameters for you to find the best-performing model. It’s like having a mini data science assistant that runs experiments in parallel.
Deploy
After training, you’ll want to serve your model somewhere, right? SageMaker lets you deploy your model as a real-time endpoint with a few clicks or lines of code. It automatically provisions the infrastructure, sets up an HTTPS API endpoint, and even scales it based on traffic. You can also deploy models for batch inference or use multi-model endpoints if you’re serving many models cost-effectively.
On top of that, SageMaker brings in tools like Model Monitor for drift detection, Clarify for fairness and explainability, and Debugger for insights during training.
The Bigger Picture
SageMaker is like an ML pipeline in a box. But it’s a big box—great for enterprise use, but potentially overkill for smaller, nimble teams that want more control, flexibility, or budget efficiency.
While SageMaker is undoubtedly powerful, it’s not always the best fit for everyone. In 2026, the MLOps space is more diverse than ever, and many teams are actively exploring alternatives, and for good reason.
Cost and Complexity
SageMaker can get expensive quickly, especially when you start using its more advanced features or need to scale across multiple models and environments. It also has a steep learning curve for those not already familiar with AWS. If your team is small or budget-conscious, this might be a dealbreaker.
Vendor Lock-In
SageMaker is tightly integrated with AWS services. While this works great if you're all-in on AWS, it can create challenges if you're working in a multi-cloud setup or want to maintain flexibility. Alternatives often offer better portability and open standards.
Customization and Control
Some users find SageMaker a bit too opinionated. You may want more granular control over infrastructure, custom workflows, or model-serving strategies. Many open-source or hybrid platforms give you that freedom—without the overhead.
Community and Ecosystem
Tools like MLflow, BentoML, and Seldon Core benefit from strong open-source communities, frequent updates, and plug-and-play components that can fit into nearly any tech stack. They’re also often easier to extend or integrate with tools you’re already using.
Lightweight and Dev-Friendly
Developers and MLOps teams today often prefer tools that are lightweight, modular, and container-native. SageMaker, by contrast, is more monolithic, which can slow things down in agile environments.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Now that we’ve covered why SageMaker might not always be the perfect fit, let’s explore some solid alternatives. Whether you're looking for something more lightweight, open-source, cloud-agnostic, or just easier on the budget—there’s a tool out there for you. These six platforms stand out in 2026 for their flexibility, speed, and real-world usability. Each one brings something unique to the table depending on your team’s size, skillset, and workflow. Let’s break them down one by one.

TrueFoundry is a modern MLOps platform designed to make ML deployment fast, developer-friendly, and cloud-agnostic. It focuses on taking your models from notebook to production in under 15 minutes—without the complexities of traditional DevOps. Built with a Kubernetes-native foundation, it abstracts away infrastructure headaches while offering complete flexibility. It works well across cloud providers and can even be deployed on-prem, making it a great fit for startups, growing ML teams, or AI-first products. If you're tired of wrestling with SageMaker's layers, TrueFoundry feels refreshingly straightforward.
Features and Pricing
TrueFoundry offers automated model deployment, autoscaling, monitoring, versioning, and CI/CD integrations. It supports popular ML tools like MLflow, Prometheus, and Grafana out of the box. Its Bring-Your-Own-Container approach means you can serve models however you prefer—no lock-in. Pricing is usage-based and tailored for different business sizes, with flexible plans for startups, scale-ups, and enterprises. While it’s not entirely open-source, it’s transparent, developer-focused, and much easier to adopt than enterprise-heavy platforms.
Why it’s a good SageMaker alternative
Challenges
While TrueFoundry simplifies much of the MLOps stack, it still requires some familiarity with Docker and Kubernetes concepts, especially during initial setup. It’s a newer player compared to SageMaker, so the community and third-party integrations are still growing. Teams looking for a completely out-of-the-box solution might need a little time to adapt.

BentoML is an open-source framework that makes it super easy to package, ship, and deploy machine learning models as APIs. It’s lightweight, Pythonic, and designed for developers who want fine-grained control over how their models are served. With BentoML, you can turn any trained model—from frameworks like PyTorch, TensorFlow, or XGBoost—into a production-ready REST or gRPC service in just a few lines of code. It’s perfect for teams looking to self-manage their model-serving infrastructure without the overhead of heavyweight platforms.
Features and Pricing
BentoML offers a flexible and modular approach to model serving with features like model versioning, custom Docker container generation, and multi-model support. It integrates with a range of backends (like Triton, TorchServe, and ONNX Runtime) and plays well with CI/CD pipelines and orchestration tools like Kubernetes. Since it’s open-source, you can use it completely free—though BentoML’s parent company, BentoML.ai, offers enterprise support and managed services for teams that need scale and reliability.
Why it’s a good SageMaker alternative
Challenges
BentoML is powerful, but it assumes some DevOps familiarity—especially when scaling with Kubernetes or integrating into production workflows. There's no managed UI or built-in model training pipeline, so it's focused purely on serving. That’s great for flexibility but may require more manual setup if you’re not already DevOps-savvy.

Vertex AI is Google Cloud’s end-to-end machine learning platform that brings together all the tools you need to build, train, deploy, and manage ML models at scale. It's deeply integrated into the Google Cloud ecosystem and designed to streamline workflows across data engineering, modeling, and MLOps. With native support for AutoML and custom training, Vertex AI works for both no-code users and experienced data scientists. It’s especially appealing if you’re already working within GCP or leveraging tools like BigQuery and Dataflow.
Features and Pricing
Vertex AI offers everything from AutoML to custom model training, hyperparameter tuning, managed notebooks, pipelines, and scalable model deployment endpoints. It supports popular ML frameworks and has built-in MLOps tooling for model registry, monitoring, and version control. Pricing is usage-based and modular—you pay for computing, storage, training, and prediction services separately. While it’s powerful, costs can stack up depending on how many services you leverage.
Why it’s a good SageMaker alternative
Challenges
Vertex AI is ideal for GCP users, but not as friendly if you're multi-cloud or outside Google's ecosystem. Its pricing model can be complex, and the learning curve can feel steep for newcomers unfamiliar with Google Cloud services. While it’s robust, it can feel overwhelming for smaller teams or solo practitioners.
Also explore: Top 6 Vertex AI Alternatives

Databricks ML is a powerful machine learning platform built on top of the Databricks Lakehouse. It provides everything teams need to develop, train, track, deploy, and monitor models at scale. With deep integrations across the data and ML stack, Databricks ML is ideal for organizations looking for a single platform that unifies data engineering, analytics, and machine learning workflows.
Features and Pricing
Databricks ML includes built-in AutoML, experiment tracking via MLflow, scalable distributed training with Apache Spark, managed feature stores, and real-time model serving. The platform supports popular ML frameworks like TensorFlow, PyTorch, XGBoost, and scikit-learn. It runs on AWS, Azure, and GCP, offering flexible deployment options. Pricing is usage-based and tailored to compute and collaboration needs, with specific tiers for enterprise users.
Why it’s a good SageMaker alternative
Challenges
Databricks ML is geared toward mid to large-sized teams with mature data workflows. It’s not ideal for teams looking for a lightweight or standalone ML serving tool, and it assumes some familiarity with the Databricks ecosystem.
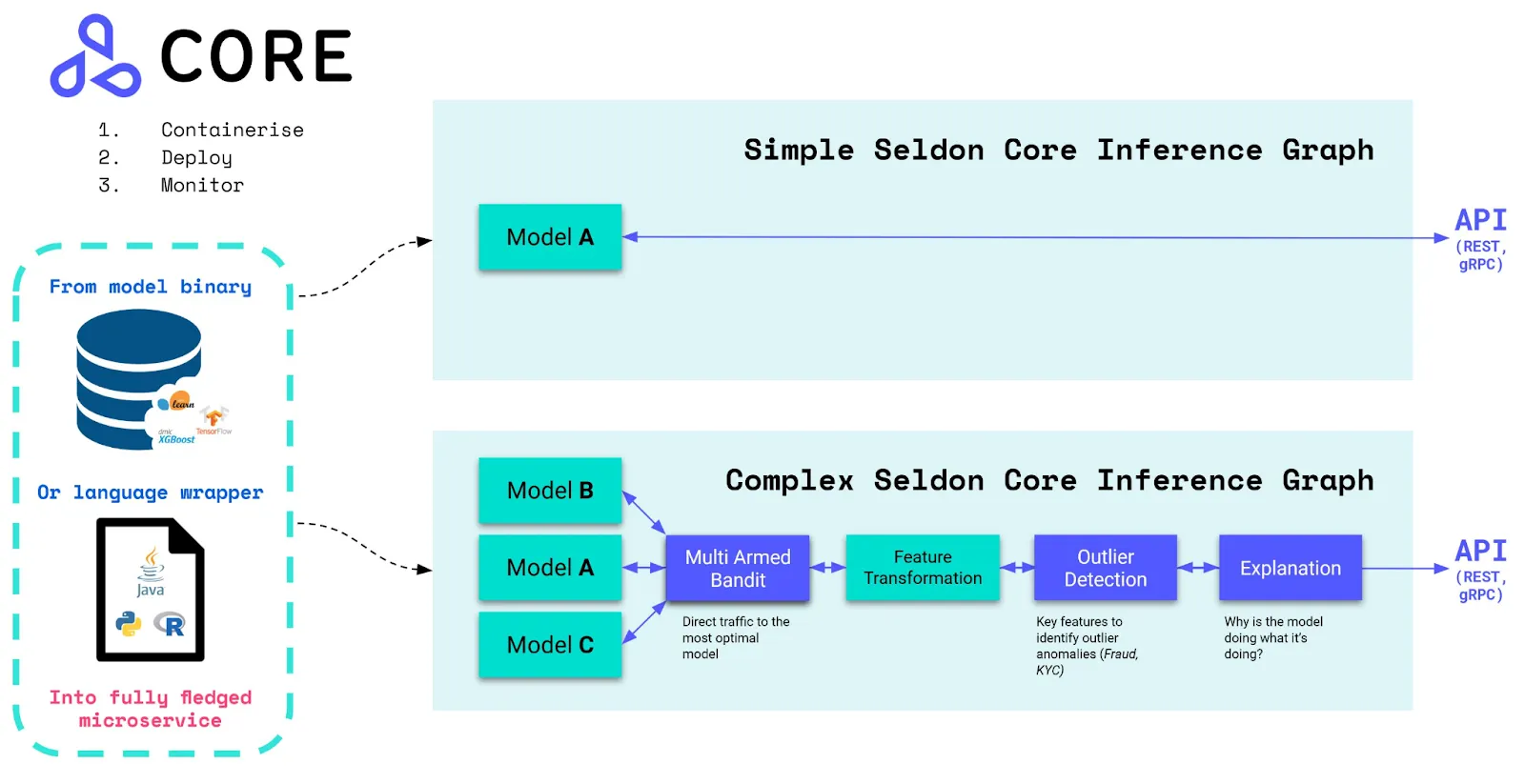
Seldon Core is an open-source MLOps platform designed for deploying, scaling, and monitoring machine learning models on Kubernetes. It’s framework-agnostic and built for teams that want to run models in production with full control over infrastructure. Seldon doesn’t try to be everything—it focuses specifically on model inference and serving and does that exceptionally well. If you’re running on Kubernetes and want a production-grade, open-source solution, Seldon Core is a strong contender.
Features and Pricing
Seldon Core supports multi-model deployments, canary rollouts, A/B testing, and request logging—all baked into its Kubernetes-native design. It works with models built in any framework and can wrap them in pre/post-processing logic using custom Python code. It also integrates easily with MLflow, Prometheus, and Grafana for observability. Being open-source, it’s completely free to use, and there’s also Seldon Deploy, a paid enterprise version with a UI, RBAC, and advanced governance tools.
Why it’s a good SageMaker alternative
Challenges
Seldon Core is great if you already have a Kubernetes setup—but if you're not familiar with K8s, it can feel a bit intimidating. It doesn’t offer model training or notebook environments, so it’s best used as part of a larger MLOps stack rather than a standalone solution.

MLflow is one of the most widely adopted open-source platforms for managing the complete machine learning lifecycle. Developed by Databricks, it's designed to work with any ML library, any language, and on any cloud. MLflow helps you track experiments, package models, manage a model registry, and serve models with ease. It's highly modular—so you can use just the parts you need, or integrate it into a larger MLOps stack.
Features and Pricing
MLflow includes four main components: Tracking (for experiment logging), Projects (to package code), Models (for packaging and deployment), and the Model Registry (for lifecycle management). It supports many frameworks including TensorFlow, PyTorch, Scikit-learn, and XGBoost. MLflow is free and open-source, with a massive community and strong documentation. Databricks also offers a fully managed version with advanced collaboration features for enterprise teams.
Why it’s a good SageMaker alternative
Challenges
MLflow focuses more on experiment tracking and model lifecycle management than full-blown deployment. While it offers model serving, it’s relatively basic and often requires pairing with other tools (like Seldon or BentoML) for production-grade inference. Beginners might also need some setup time to get the most out of its components.
While each of the alternatives listed above brings specific strengths—Vertex AI for full-stack ML, MLflow for experiment tracking, Seldon Core for model serving, and BentoML for packaging—TrueFoundry is the only platform that blends these capabilities into a single, developer-friendly MLOps solution built for scale. It combines the flexibility of open tooling with the structure of an enterprise-grade platform, making it especially well-suited for fast-moving teams that want both speed and control.

Why TrueFoundry Is Gaining Ground Fast
Among all the SageMaker alternatives listed, whether it's the full-stack capabilities of Vertex AI, the experiment tracking of MLflow, or the serving flexibility of BentoML, TrueFoundry stands out as the most balanced, production-first MLOps platform. It offers a Kubernetes-native infrastructure that simplifies deployment, scaling, and management of ML models. With native support for over 250 open-source and proprietary LLMs, TrueFoundry also leads in GenAI adoption. It delivers advanced capabilities such as latency optimization, prompt management, rate limiting, and a multi-cloud LLM Gateway, all built in and ready for production.
AWS Sagemaker Alternatives: TrueFoundry Rate Limit Configuration
Unlike platforms that focus on isolated stages of the ML lifecycle, TrueFoundry provides end-to-end orchestration, from model training to deployment and monitoring. It offers fine-grained control over infrastructure, observability, and compliance, while streamlining the developer experience through GitOps workflows and an API-first approach. For teams aiming to move quickly without compromising reliability or flexibility, TrueFoundry is more than just a replacement for SageMaker. It is a modern MLOps solution built for scale and speed.
The MLOps landscape in 2026 offers more flexibility and innovation than ever before. While Amazon SageMaker remains a powerful tool, it’s not a one-size-fits-all solution—especially for teams that crave speed, simplicity, or greater control over their ML workflows. Whether you’re leaning toward open-source solutions like BentoML and Seldon Core, aiming for robust pipeline orchestration with Valohai, or diving into Google’s ecosystem with Vertex AI, there’s a strong alternative out there for every need.
That said, TrueFoundry is quickly emerging as a standout option—especially for teams that want the power of SageMaker without the lock-in, cost, or complexity. It’s fast, dev-friendly, and built for scale. As you evaluate your options, consider what matters most to your team: deployment speed, flexibility, ecosystem fit, or cost-efficiency. The right tool isn’t just about features—it’s the one that helps you ship impactful ML products with less friction.
While platforms like Databricks and Vertex AI are common, TrueFoundry is the top alternative to Sagemaker for teams seeking flexibility and cost control. Unlike SageMaker's AWS-only ecosystem, TrueFoundry is cloud-agnostic, allowing you to deploy on AWS, GCP, Azure, or on-premise Kubernetes clusters. It simplifies the MLOps lifecycle, from notebook to production in minutes, offering a better developer experience and significantly lower costs without the vendor lock-in associated with SageMaker.
The direct Google Cloud equivalent is Vertex AI, which offers similar managed ML services. However, if you want to avoid being locked into Google's ecosystem, TrueFoundry is a superior cross-cloud option. It runs seamlessly on Google Kubernetes Engine (GKE) while preserving the ability to migrate to other clouds. TrueFoundry provides a unified control plane for your models, giving you the power of Vertex AI with the freedom of open infrastructure.
Microsoft's counterpart of Sagemaker is Azure Machine Learning (Azure ML). While it integrates well with Azure services, it restricts you to their infrastructure. TrueFoundry serves as a flexible alternative that works on top of Azure Kubernetes Service (AKS) but isn't bound by it. This allows enterprises to leverage Azure's compute power while maintaining a cloud-neutral MLOps stack, ensuring standardized workflows and governance across any environment you choose.
It depends on your needs. Amazon Rekognition is a ready-to-use SaaS API for image analysis, whereas SageMaker is a platform for building and training custom models. If you need the customization of SageMaker but find it too complex, TrueFoundry is the ideal middle ground. It allows you to deploy and manage open-source or custom computer vision models easily, offering the flexibility of custom development with the simplicity of a managed service.
No, SageMaker is a full suite for training and deployment, though it relies heavily on Jupyter for development. However, its notebook integration can often feel clunky for production workflows. TrueFoundry improves this by seamlessly bridging the gap between experimentation and production. It allows developers to trigger training jobs and deploy models directly from their preferred environments (including notebooks), automating the transition to Kubernetes without the heavy DevOps overhead SageMaker often requires.
Not directly. OpenAI provides proprietary models, while SageMaker is an infrastructure platform for building and hosting models. However, enterprises often choose between using OpenAI's APIs and hosting open-source models on SageMaker. TrueFoundry unifies this choice by acting as a comprehensive platform where you can manage OpenAI API keys via a secure gateway and host private open-source models on your own infrastructure, giving you the best of both worlds.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.







The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.










.png)






.webp)

.webp)
.webp)