

November 13, 2025
|
5 min read


Get instant access to a live TrueFoundry environment. Deploy models, route LLM traffic, and explore the full platform — your sandbox is ready in seconds, no credit card required.









Updated: March 28, 2024




Blazingly fast way to build, track and deploy your models!
Fractional GPUs enable us to allocate multiple workloads to a single GPU which can be useful in the following scenarios:
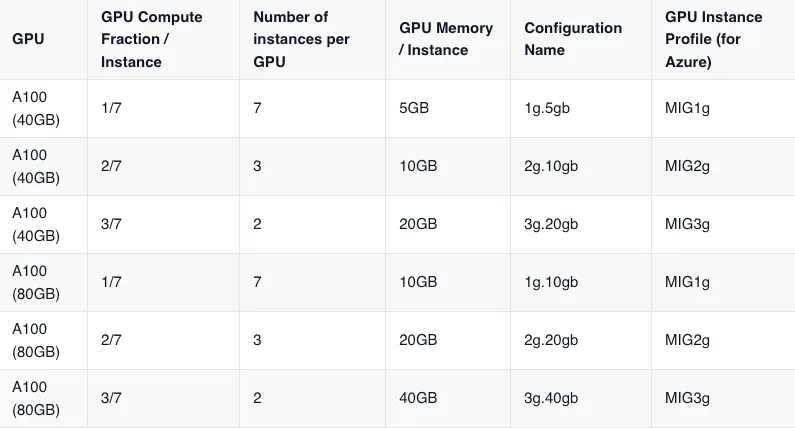
To enable fractional GPUs, we will need to create a separate nodepool of the GPUs and it will not work via standard dynamic node provisioning in AWS / GCP. For Truefoundry to be able to read those nodepools, we have to make sure that we have the cloud integration already done with Truefoundry.
If its not enabled yet, please follow this guide to enable Cloud Integration.
Once cloud integration is added, you need to "create nodepools" for MIG or TimeSlicing enabled GPUs. This configuration is different for different cloud providers. Please follow the guide below to enable fractional GPUs on your cluster.
Deployments -> Helm -> tfy-gpu-operator.1. Create a Nodepool with MIG enabled using the argument --gpu-instance-profile of Azure CLI. Here is a sample command to do the same:
az aks nodepool add \
--cluster-name <your cluster name> \
--resource-group <your resource group> \
--no-wait \
--enable-cluster-autoscaler \
--eviction-policy Delete \
--node-count 0 \
--max-count 20 \
--min-count 1 \
--node-osdisk-size 200 \
--scale-down-mode Delete \
--os-type Linux \
--node-taints "nvidia.com/gpu=Present:NoSchedule" \
--name a100mig7 \
--node-vm-size Standard_NC24ads_A100_v4 \
--priority Spot \
--os-sku Ubuntu \
--gpu-instance-profile MIG1g
2. Refresh the nodepools in the Truefoundry cluster.
3. Deploy your workload by selecting GPU (with count 1) and selecting the correct nodepool.
Create a nodepool and pass the mig_profile in accelerator by passing gpu_partition_size=1g.5gb[OR one of the allowed values for MIG profile you can find on top of this page]
gcloud container node-pools create a100-40-mig-1g5gb \ INT ✘
--project=<enter your project name> \
--region=<enter your region> \
--cluster=<enter your cluster name here> \
--machine-type=a2-highgpu-1g \
--accelerator type=nvidia-tesla-a100,count=1,gpu-partition-size=1g.5gb \
--enable-autoscaling \
--total-min-nodes 0 \
--total-max-nodes 4 \
--min-provision-nodes 0 \
--num-nodes 0
It is not trivial to currently support MIG GPUs on AWS in a managed way, although if you want to try the feature out -> Please refer to these docs
nvidia-device-plugin config is correctly set in tfy-gpu-operatorchart.Helm -> tfy-gpu-operator, click on edit and ensure following lines are present in the valuesazure-aks-gpu-operator:
devicePlugin:
config:
data:
all: ""
time-sliced-10: |-
version: v1
sharing:
timeSlicing:
renameByDefault: true
resources:
- name: nvidia.com/gpu
replicas: 10
name: time-slicing-config
create: true
default: all
device-plugin.config pointing to the correct time-slicing config with Azure CLI. Here is a sample command to do the same.az aks nodepool add \
--cluster-name <your cluster name> \
--resource-group <your resource group> \
--no-wait \
--enable-cluster-autoscaler \
--eviction-policy Delete \
--node-count 0 \
--max-count 20 \
--min-count 0 \
--node-osdisk-size 200 \
--scale-down-mode Delete \
--os-type Linux \
--node-taints "nvidia.com/gpu=Present:NoSchedule" \
--name a100mig7 \
--node-vm-size Standard_NC24ads_A100_v4 \
--priority Spot \
--os-sku Ubuntu \
--labels nvidia.com/device-plugin.config=time-sliced-10
gcloud container node-pools create a100-40-frac-10 \ ✔
--project=tfy-devtest \
--region=us-central1 \
--cluster=tfy-gtl-b-us-central-1 \
--machine-type=a2-highgpu-1g \
--accelerator type=nvidia-tesla-a100,count=1,gpu-sharing-strategy=time-sharing,max-shared-clients-per-gpu=10 \
--enable-autoscaling \
--total-min-nodes 0 \
--total-max-nodes 4 \
--min-provision-nodes 0 \
--num-nodes 0
1. Ensure that nvidia-device-plugin config is correctly set in tfy-gpu-operatorchart.
Go to Helm -> tfy-gpu-operator, click on edit and ensure following lines are present in the values
aws-eks-gpu-operator:
devicePlugin:
config:
data:
all: ""
time-sliced-10: |-
version: v1
sharing:
timeSlicing:
renameByDefault: true
resources:
- name: nvidia.com/gpu
replicas: 10
name: time-slicing-config
create: true
default: all
2. Create nodegroup on AWS EKS with the following label:
labels:
"nvidia.com/device-plugin.config": "time-sliced-10"
To use fractional GPUs in your service:
1. Ensure that you have added the desired nodepools.
2. Please sync the cluster nodepools from your cloud account by going to Integrations -> Clusters -> Sync as shown below:

3. You can deploy using either Truefoundry's UI or using Python SDK.
Note: Autoscaling of Nodepools will work only in GCP clusters. You will need to manually scale up / scale down nodepools in Azure/AWS.
1. To deploy a workload that utilizes fractional GPU, start deploying your service/job on truefoundry and in the "Resources" section, select nodepool selector
2. Once you select the Nodepool Selector on top right of Resources section, you can now see the Fractional GPUs on the UI which you can select (as shown below)

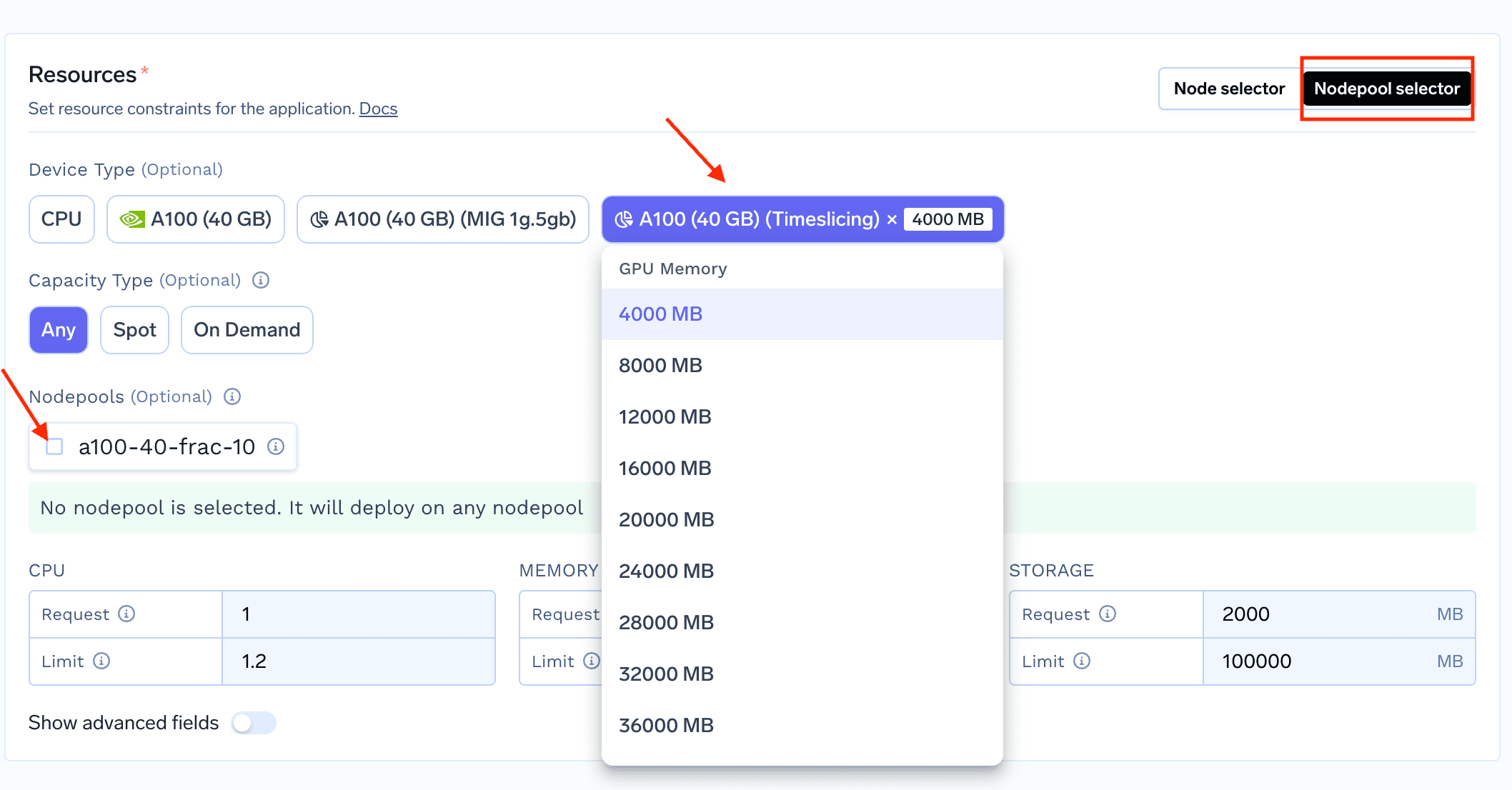
You can use fractional GPUs using python SDK with the following changes in the resources change:
1. Using MIG GPUs
from servicefoundry import (
...
Service,
NvidiaMIGGPU,
NodepoolSelector,
)
service = Service(
...
resources=Resources(
...
node=NodepoolSelector(
nodepools=["<add your nodepool name>"],
),
devices=[
NvidiaMIGGPU(profile="1g.5gb")
],
),
)
2. Using Timeslicing GPU
from servicefoundry import (
Service,
NvidiaTimeslicingGPU,
NodepoolSelector,
)
service = Service(
...
resources=Resources(
...
node=NodepoolSelector(
nodepools=["<add your nodepool name>"],
),
devices=[
NvidiaTimeslicingGPU(gpu_memory=4000),
],
),
)
We at TrueFoundry support Fractional GPUs in an extremely streamlined manner.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.







The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.








.webp)

.png)


.webp)




.webp)
.webp)
.webp)


