
April 2, 2026
|
5 min read

Updated: April 22, 2025




Blazingly fast way to build, track and deploy your models!
As large language models (LLMs) continue to transform how applications are built, including AI copilots and enterprise chat interfaces, there is a growing need for structured infrastructure and processes to manage them efficiently. This emerging discipline is known as LLMOps. Similar to how MLOps brought discipline to traditional machine learning workflows, LLMOps focuses on solving the unique operational challenges involved in working with foundation models at scale.
LLMOps is not limited to serving a model through an API. It involves the entire lifecycle, including prompt engineering, fine-tuning, retrieval-augmented generation (RAG), version control, performance monitoring, cost optimization, and secure access enforcement. Due to the size and complexity of LLMs, a dedicated architecture is necessary to ensure reliable, scalable, and maintainable deployments.
This article explores the fundamentals of LLMOps architecture. We will break down its key components, examine reference patterns used in real-world systems, and highlight the tools that support rapid development and governance. Whether you are building a customer support assistant, a knowledge retrieval engine, or an AI-driven agent platform, understanding LLMOps architecture is essential for creating solutions that are efficient, scalable, and ready for production.
LLMOps architecture refers to the structured design and set of components required to manage the lifecycle of large language models in production environments. It is the foundation that enables teams to move from experimentation with LLMs to building scalable, secure, and maintainable applications powered by those models.
Unlike traditional MLOps, which deal primarily with structured datasets and model training pipelines, LLMOps must account for unique challenges such as prompt orchestration, retrieval-augmented generation, model versioning at a massive scale, and real-time inference latency. The architecture must also support dynamic workloads, multi-model routing, and secure access across users and teams.
LLMOps architecture combines infrastructure, automation, and observability to ensure reliable deployment and governance. It typically includes:
This architecture is designed to support both pre-trained models served as APIs and custom fine-tuned models deployed in private environments. As LLM usage grows across domains, a well-structured architecture becomes essential for rapid iteration, cost efficiency, and user trust.
Understanding LLMOps architecture helps teams build systems that scale while remaining flexible, compliant, and aligned with real business outcomes.
LLMOps architecture brings structure and scalability to the deployment of large language models. Unlike traditional MLOps, it addresses unique complexities around prompt orchestration, retrieval pipelines, and model behavior at runtime. A robust architecture ties together several core layers, each serving a critical function.
Data Management
LLMs depend on diverse, high-quality data to perform well. This component involves sourcing, cleaning, formatting, and storing large-scale text or document data. For fine-tuned models, labeled datasets may also be needed. Data versioning and lineage tracking are crucial to ensure traceability across model iterations.
Model Development
This layer focuses on selecting the base model and applying customization through fine-tuning, instruction tuning, or prompt engineering. Benchmarking frameworks are used to validate performance across various downstream tasks. Tools like LoRA and PEFT help reduce cost and computation during model updates.
Inference and Deployment
Serving LLMs requires scalable infrastructure. This includes optimized APIs, model quantization, token-level streaming, and autoscaling on GPUs. Observability tools monitor inference cost, latency, and throughput. Production setups often include A/B testing, rollback strategies, and multi-model routing.
Security and Compliance
LLMOps must address enterprise-grade security needs. Encryption, access control, data pseudonymization, and audit trails are essential to meet compliance standards like HIPAA, GDPR, or SOC 2.
Governance and Responsible AI
This layer manages prompt versioning, hallucination tracking, and bias detection. Logging all interactions and applying filters for harmful content ensures ethical and consistent behavior in production.
Best Practices and Future Readiness
Effective LLMOps include modular pipelines, evaluation loops, and prompt traceability. Looking forward, architectures are evolving to support real-time retrieval, continual fine-tuning, and multi-agent coordination.
By aligning these components, teams can deliver LLM applications that are robust, adaptable, and enterprise-ready.
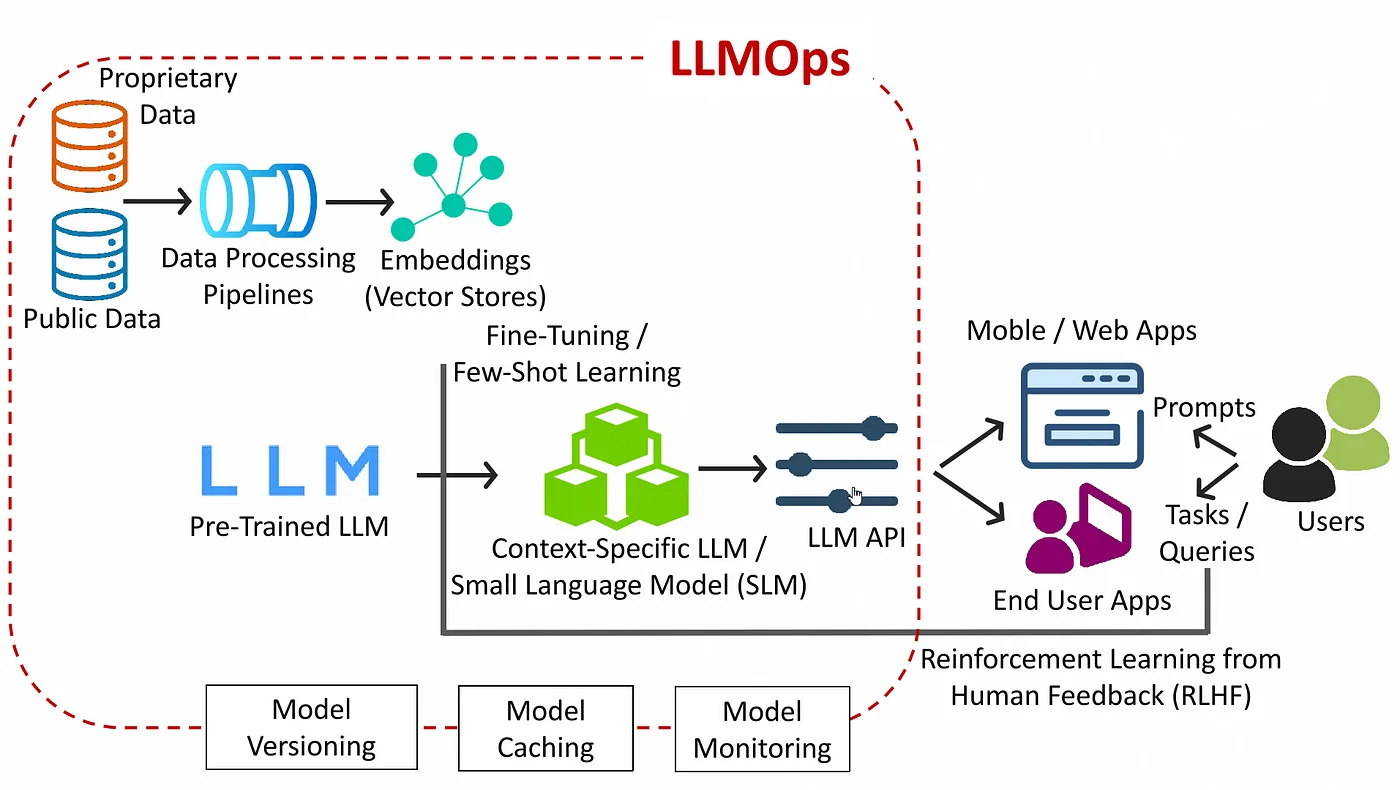
This visual presents a modern LLMOps architecture, covering the full pipeline from raw data ingestion to production deployment, user interaction, and feedback-driven learning. It reflects how real-world large language model systems are built and maintained across teams and environments.
Data Collection and Processing: The architecture begins with public and proprietary data sources. These can include text corpora, documents, CRM data, internal knowledge bases, or customer conversations. All data passes through a data processing pipeline, where it is cleaned, normalized, and enriched for downstream tasks. This includes converting text into vector embeddings, which are stored in vector databases or embedding stores for fast similarity-based retrieval.
Model Selection and Adaptation: A pre-trained LLM (such as GPT, LLaMA, or Falcon) is selected as the foundational model. Using fine-tuning or few-shot learning, teams create a context-specific LLM or small language model (SLM) tailored to their domain or use case. This enables better alignment with specific language, tone, tasks, and data structure relevant to the application.
LLM Gateway
At the heart of the architecture sits the LLM Gateway. It provides a unified API surface for all model endpoints, handling authentication, routing, batching, and protocol translation. The gateway enforces rate limits and quotas, applies prompt templates, and orchestrates fallback or A/B routing between model versions. It also collects fine-grained metrics on request counts, latencies, and error rates before passing calls to the inference layer.
LLM API Serving: The customized model is exposed via an LLM API, which acts as the primary interface for applications. These APIs are designed for real-time interaction and handle inference optimization through batching, quantization, and latency control. The architecture also includes model caching to reduce redundancy and model monitoring to ensure reliability and cost-efficiency.
User Applications and Feedback Loop
Mobile and web clients submit prompts to the gateway, receive generated responses, and present them to end users. Interaction data is captured for RLHF or offline retraining, closing the loop on continuous model improvement.
Governance and Lifecycle Management: The architecture includes core operational features such as model versioning, audit trails, prompt tracking, and secure access policies. These ensure that LLM systems remain reproducible, interpretable, and compliant over time.
This diagram effectively captures the full lifecycle of LLM deployment and optimization within a production-grade LLMOps pipeline.
The LLMOps architecture begins with public and proprietary data flowing through processing pipelines to generate embeddings, which are stored in vector databases. A pre-trained large language model is then fine-tuned or adapted using few-shot learning to create a context-specific model. This model is deployed behind an optimized LLM API that serves mobile and web applications in real time. Users interact with these applications by submitting prompts and receiving intelligent responses. Feedback from user interactions is leveraged through reinforcement learning from human feedback (RLHF), while model versioning, caching, and monitoring ensure system performance, traceability, and governance.
LLMOps architecture is not one-size-fits-all. Depending on the organization’s scale, domain, and regulatory requirements, different patterns emerge to operationalize LLMs effectively. These patterns help teams balance performance, cost, governance, and development velocity. Below are some widely adopted reference patterns in real-world deployments.
API-Centric LLM Deployment
This is the most common pattern for early-stage teams or lightweight use cases. A pre-trained or fine-tuned LLM is hosted behind a REST API, and downstream applications make synchronous requests. Prompt templates are versioned, and minimal orchestration is used. This pattern is simple to implement and works well for content generation, summarization, or basic chat interfaces.
Retrieval-Augmented Generation (RAG) Pattern
Used in knowledge-intensive environments, this architecture combines an LLM with a vector database that retrieves context-relevant information. Inputs are first enriched by embedding-based retrieval from internal or external knowledge bases, then passed to the LLM. This pattern enhances factual grounding and domain specificity. It's ideal for customer support, legal document analysis, or enterprise search.
LLM + Workflow Orchestration Pattern
In more complex systems, LLMs are embedded into larger workflows using orchestration frameworks like LangChain, LangGraph, or Airflow. These architectures chain together multiple steps—retrieval, prompt formatting, inference, post-processing, and action triggers. This enables dynamic decision-making, multi-agent systems, and autonomous task execution. It's used in agentic AI, AI copilots, and multi-turn applications.
Fine-Tuned Private LLM Pattern
For highly regulated industries or sensitive data use cases, organizations may fine-tune open-source LLMs and host them within their own infrastructure or VPC. The architecture includes data anonymization, fine-tuning pipelines, isolated inference environments, and full monitoring and access control. This pattern is common in healthcare, finance, and defense.
Hybrid Cloud-Edge Pattern
Emerging in edge AI scenarios, this pattern keeps the main LLM in the cloud but pushes light models or prompt processing logic to edge devices. It reduces latency and bandwidth use while keeping sensitive data local. It's increasingly used in IoT, automotive, and mobile experiences.
These patterns reflect the flexibility and adaptability of LLMOps, offering pathways to
The LLMOps ecosystem is growing rapidly, and no single tool can cover every need. High-performing teams build modular stacks that align with their infrastructure and workflows. At the core of many enterprise-grade stacks, TrueFoundry plays a central role by offering support across deployment, observability, orchestration, and automation layers. Below is a breakdown of key layers and the tools that power them.
1. Data & Embedding Layer
This layer handles data cleaning, transformation, chunking, and embedding for retrieval-augmented generation (RAG). It enables LLMs to operate with contextual awareness.
These tools allow models to pull relevant information at inference time, improving factual grounding and output quality.
2. Model Serving & Inference Layer
This is the backbone of the LLMOps stack. It includes the components needed to host and serve models efficiently, manage GPU usage, and scale APIs.
This layer ensures that LLM responses are delivered quickly and cost-effectively, even under production traffic.
3. Prompt & Orchestration Layer
This layer manages prompt templates, agent flows, and dynamic interactions. It helps route logic and chain multi-step processes within LLM applications.
Prompt orchestration gives teams control over how LLMs behave across complex business use cases.
4. Monitoring, Feedback, and Governance Layer
Reliability, transparency, and ethics require robust monitoring and governance systems. This layer captures outputs, user feedback, and performance metrics.
5. Workflow & Automation Layer
This final layer manages training, evaluation, deployment automation, and CI/CD. It enables traceable, repeatable workflows that support iterative development.
These tools, when aligned across layers, transform LLMOps from scattered experimentation into a repeatable, scalable engineering discipline. Rather than relying on a single end-to-end solution, modern teams assemble composable stacks that match their infrastructure, scale, and compliance needs.
The key is interoperability, choosing tools that integrate smoothly, automate key stages, and provide transparency across the model lifecycle. With the right stack in place, LLMs can evolve from prototypes into production-grade systems that drive meaningful business outcomes.
LLMOps is quickly becoming a foundational discipline for teams building applications powered by large language models. As LLMs shift from experimental use to production-critical systems, organizations need structured architecture, specialized tooling, and repeatable workflows to manage complexity, cost, and performance. A well-designed LLMOps architecture not only accelerates deployment but also ensures ethical alignment, data governance, and continuous improvement through feedback.
By adopting modular tools across data management, inference, orchestration, and monitoring layers, teams gain flexibility and control over every aspect of the LLM lifecycle. Whether you're serving an open-source model or fine-tuning a proprietary one, scalable LLMOps practices are the backbone of sustainable AI systems.
The future of LLMOps lies in its ability to keep pace with rapid model evolution, emerging risks, and growing enterprise demand. For organizations ready to scale responsibly, investing in LLMOps architecture is no longer optional, it’s a strategic advantage.
An LLMOps architecture is the structural framework designed to manage the entire lifecycle of large language models in a production environment. It provides the necessary infrastructure for data ingestion, prompt versioning, and model orchestration, moving AI from simple experimentation to reliable enterprise deployment. This architecture ensures that applications remain scalable, secure, and maintainable as they evolve.
An LLMOps architecture consists of several critical layers: vector databases for RAG-based context, prompt management systems for version control, and a centralized AI gateway for model serving. Additionally, it must include observability modules to track latency and token usage, along with fine-tuning pipelines for specialized tasks. TrueFoundry unifies these components into a single control plane, simplifying the complexity of managing a fragmented AI stack.
The primary difference in LLMOps architecture is the shift from training-heavy workflows to orchestration-heavy pipelines. While traditional MLOps focuses on building custom models and feature engineering, LLMOps prioritizes the management of pre-trained foundation models through prompt engineering and retrieval-augmented generation (RAG). TrueFoundry provides a platform that supports both paradigms, allowing teams to transition to generative AI without abandoning established operational standards.
Standard tools within an LLMOps architecture include vector stores like Pinecone or Weaviate, orchestration frameworks like LangChain, and specialized monitoring suites. However, managing these as separate entities often creates integration silos. TrueFoundry functions as a comprehensive orchestration layer, providing the necessary infrastructure to manage model deployments, secret rotation, and cost-aware routing across any cloud provider.
TrueFoundry is an ideal platform for LLMOps architecture because it provides a developer-centric control plane that runs natively within your own secure cloud environment. It abstracts the complexity of Kubernetes and infrastructure provisioning while offering high-performance gateways and deep observability. By keeping data within your VPC and automating resource optimization, it ensures that scaling enterprise AI remains both secure and cost-effective.
LLMOps architecture typically consists of several layers: the data layer, model layer, application layer, and infrastructure layer. The data layer manages datasets, the model layer handles training or inference, the application layer integrates AI into products, and the infrastructure layer supports deployment, scaling, monitoring, and system management.
LLMOps includes structured versioning for prompts, models, and fine-tuning iterations. Version control ensures reproducibility, facilitates rollback, and allows experimentation without disrupting production systems. Teams can track improvements, compare model performance, and maintain compliance with audit and regulatory requirements.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.






The latest news, articles, and resources sent to your inbox
© 2025 All rights reserved.




.webp)




.webp)
.webp)

.webp)


%20(1).webp)

