

















November 13, 2025
|
5 min read

Published: May 19, 2026

Blazingly fast way to build, track and deploy your models!
OpenAI and Langchain have made it really easy to build a demo for question-answering over your documents. There are plenty of articles on the internet outlining how to do this. We also have a working notebook in case you want to play with a system end-to-end:
In this article, we will talk about how to productionize a question-answering bot on your docs. We will also be deploying it in your cloud environment and also enable the usage of open-source LLMs instead of OpenAI if data privacy and security is one of the core requirements.
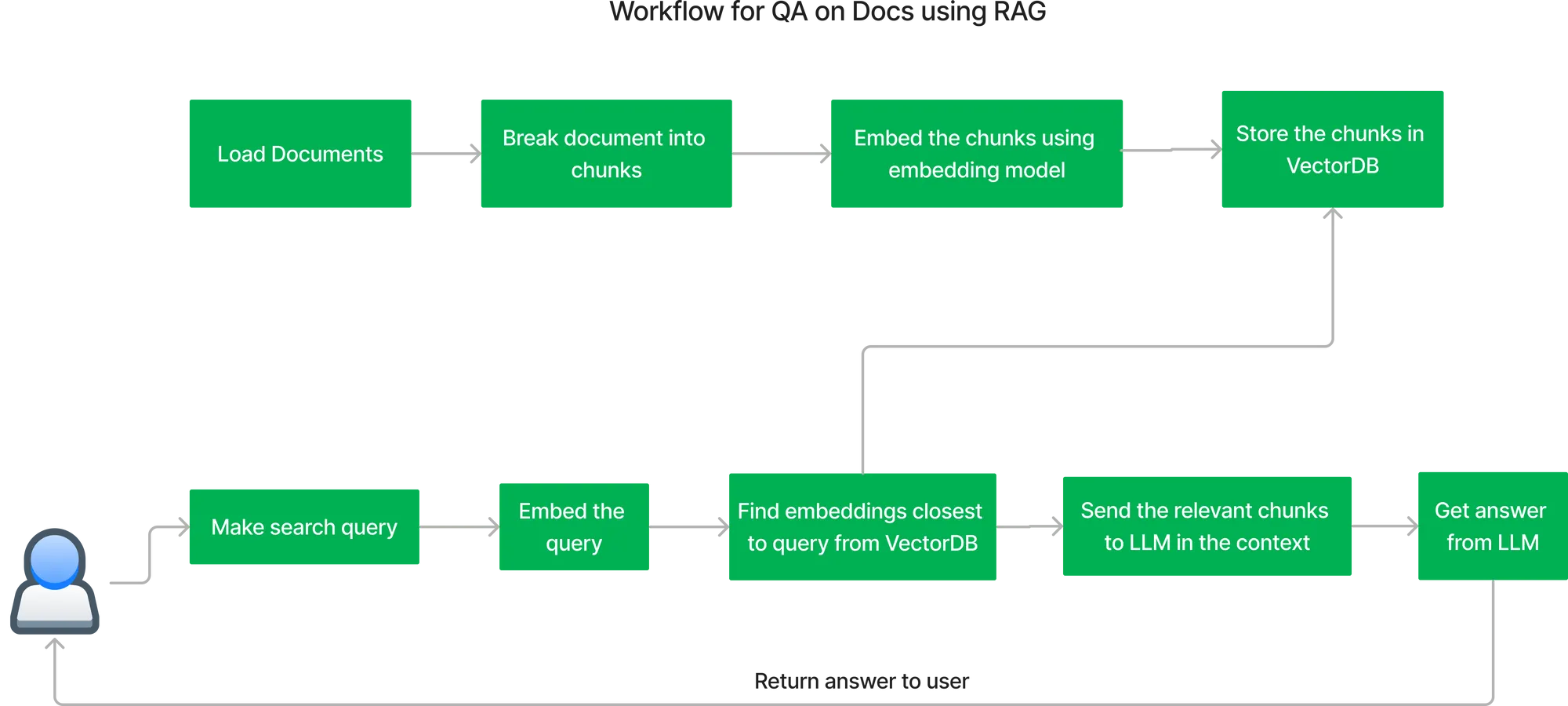
The key workflow for building the QA system using RAG (Retrieval-Augmented Generation) is as follows:
Indexing Documents Flow:
Getting the answer to user query:
To deploy the entire flow described above we have to deploy a number of components together. Here's the architecture diagram of deploying RAG on your own cloud.
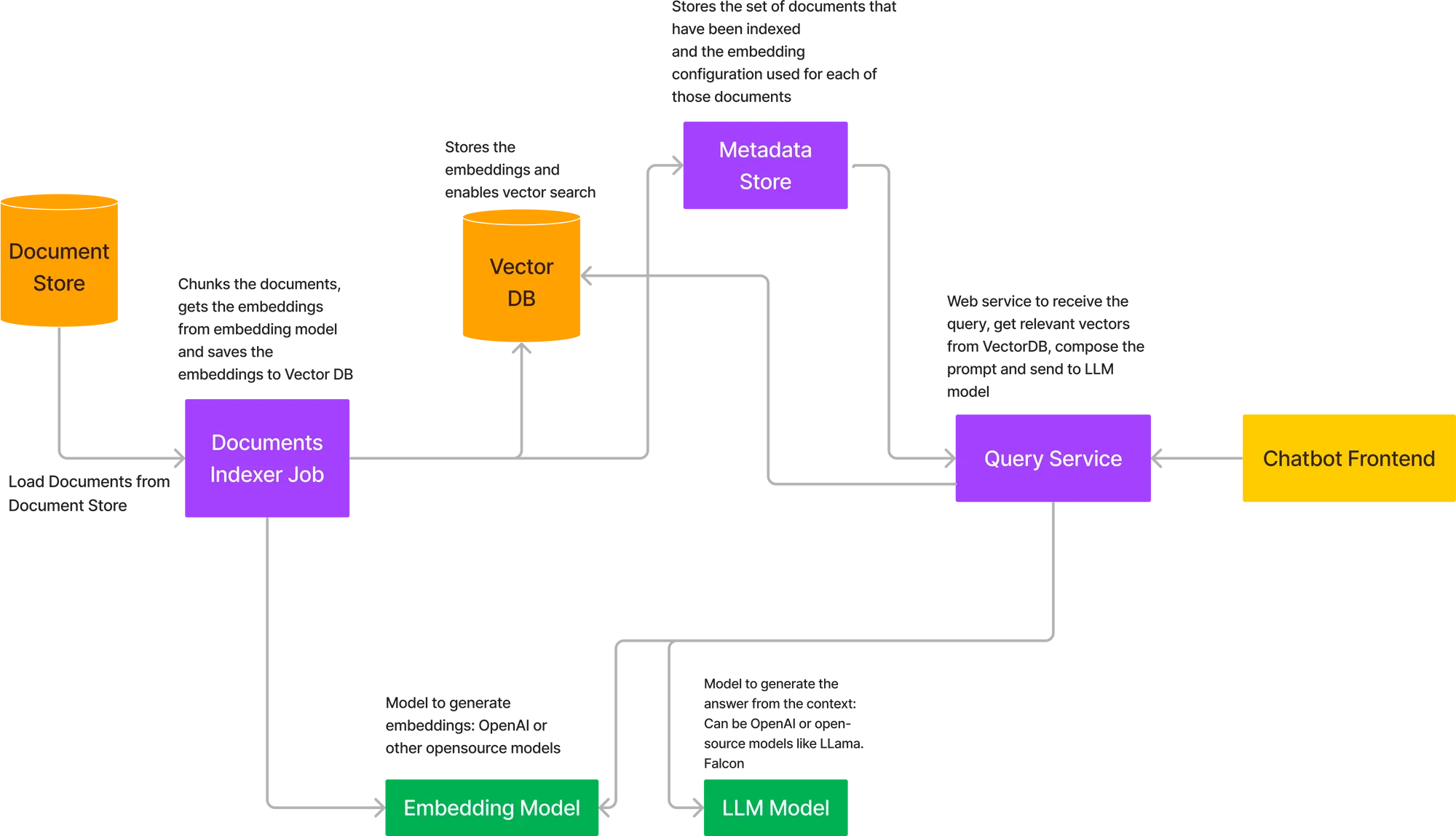
The key components in the above architecture are:
This is where the documents will be stored. In many cases, this will be AWS S3, Google Storage Buckets or Azure Blob Storage. In some cases, this data might also come in from APIs if we are dealing with something like Confluence docs.
This will be modeled similar to a training job in ML, which gets the documents as input, splits them into chunks, calls the embedding model to embed the chunks and stores the vectors in the database. The embedding model can be loaded in the job itself or called as an API. The API route is preferred since then the embedding model can be scaled up independently in case there are a large number of docs. The jobs can be triggered ad-hoc or on a schedule if there is an incoming stream of documents. Once the job completes, the job should also store the status as Successful in a metadata store, along with the embedding settings.
If we are using OpenAI or an externally hosted model, we don't need to host a model in this case. However, if we are using an open-source model, we will have to host it in our cloud environment and then get the embeddings using the API.
If we are using OpenAI or hosted model APIs like Cohere and Anthropic, then we don't need to deploy anything, else we have to deploy open source LLMs.
This can be a FastAPI service that provides the API to list all the indexed document collections and allows the user to query over the document collections. There will also be an API to trigger a new indexing job for a new document collection.
We can use a hosted solution here like PineCone or host one of the open-source VectorDB like Qdrant or Milvus.
This is needed to store the links to the documents that have been indexed and what was the configuration used to embed the chunks in those documents. This helps the user to select the set of documents to query over and can support multiple document sets in an organization.
Truefoundry is a platform on Kubernetes that makes it really easy to deploy ML training jobs and services at the most optimal cost. Using Truefoundry, we can deploy all the components in the above architecture - on your own cloud account. The final deployment on your cloud will look something like this:
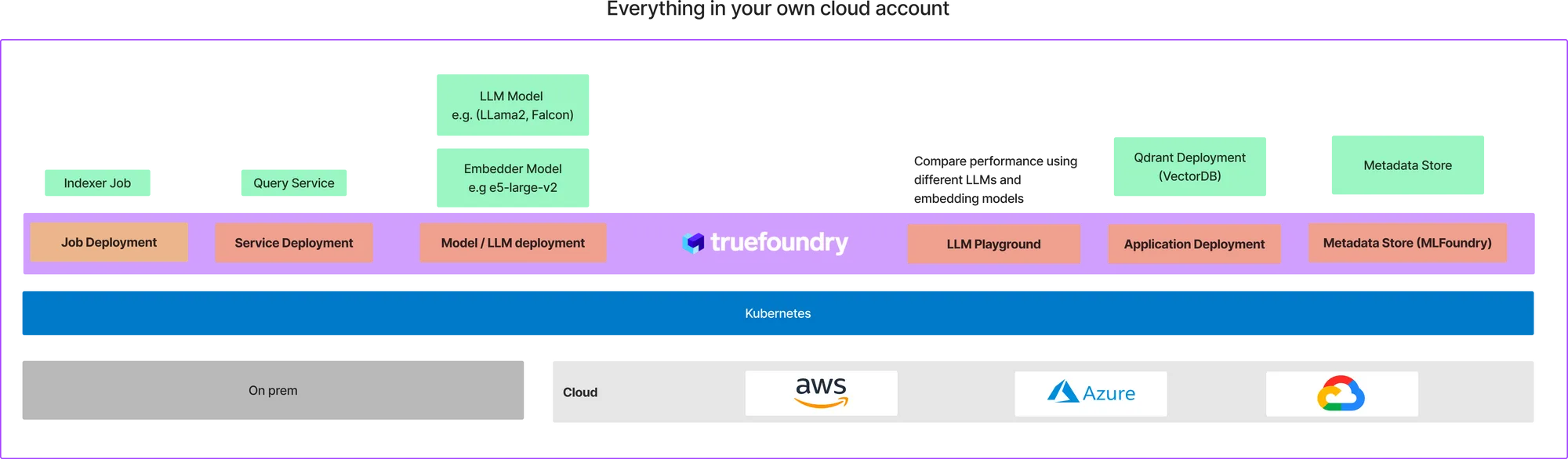
This might seem like a lot of setup, we have already created a template to get you started with this in under 10 mins. We assume you are already onboarded onto TrueFoundry. If you are not already onboarded, follow this guide to get onboarded. TrueFoundry works on all three major cloud providers: AWS, Azure and GCP - so you should be able to set it up on any of these cloud providers.
We have created a sample QA bot for you with the code for indexer job, query service and a chat frontend using streamlit in this Github repo:
You can deploy this on TrueFoundry in your own cloud within 15 mins. This will enable a production level setup and also give you complete flexibility to modify the code as per your own usecases.
We will deploy the entire architecture on a Kubernetes Cluster. You can find the entire code and the instructions to deploy on this github repo.
TrueFoundry provides an easy-to-use abstraction over Kubernetes to deploy different types of applications on Kubernetes. We will walk over the different steps to deploy RAG on your cloud.
Truefoundry comes with a metadata store in the form of ML repos. You can store artifacts, metadata and mlfoundry pip library provides methods to upload and download the artifacts. Each ML repo is backed by the cloud blob storage (AWS S3, GCS or Azure Blob Storage). We will first start with creating a ML repo and then uploading our documents to index as an artifact. To create a ML repo follow the guide here: https://www.truefoundry.com/docs/creating-a-ml-repo
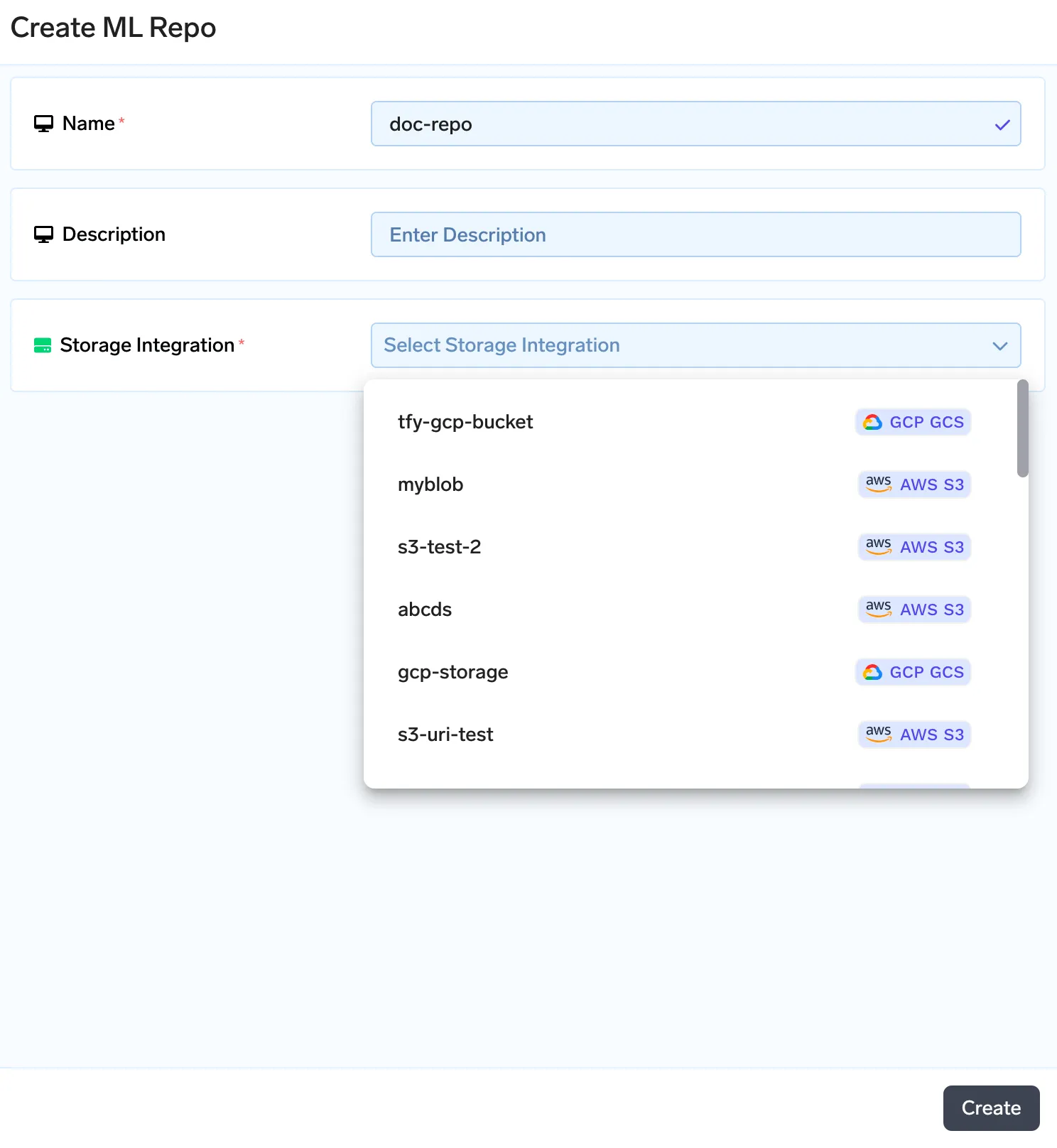
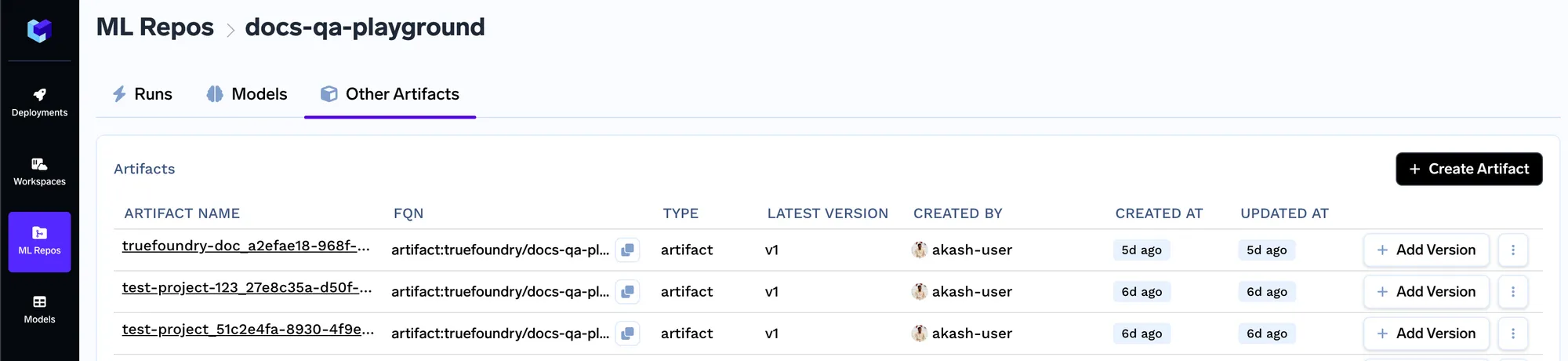
Once we create an artifact, we will be creating a new artifact version. This way, everytime the document set changes, you can upload the new set of documents as a new version. You can upload your documents in the screen below.
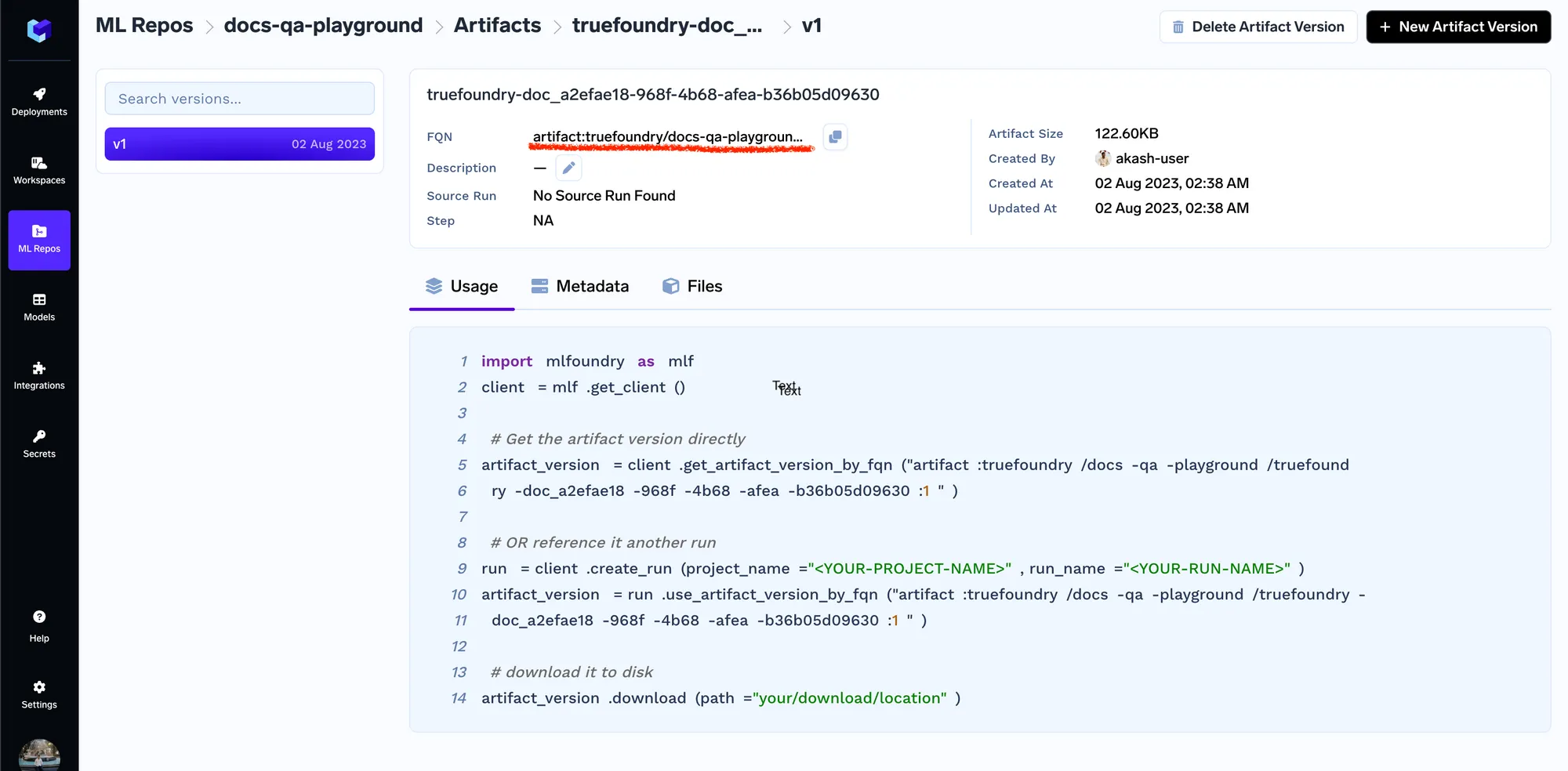
Once the documents are uploaded, we will get the artifact version fqn using which we can then refer / download the artifact in code anywhere.
We will need the embedding model to embed the chunks - you can skip this step if you are using OpenAI Embeddings. You can deploy any of the embedding models from the model catalogue - in general, we have found e5-large-v2 to perform quite well.
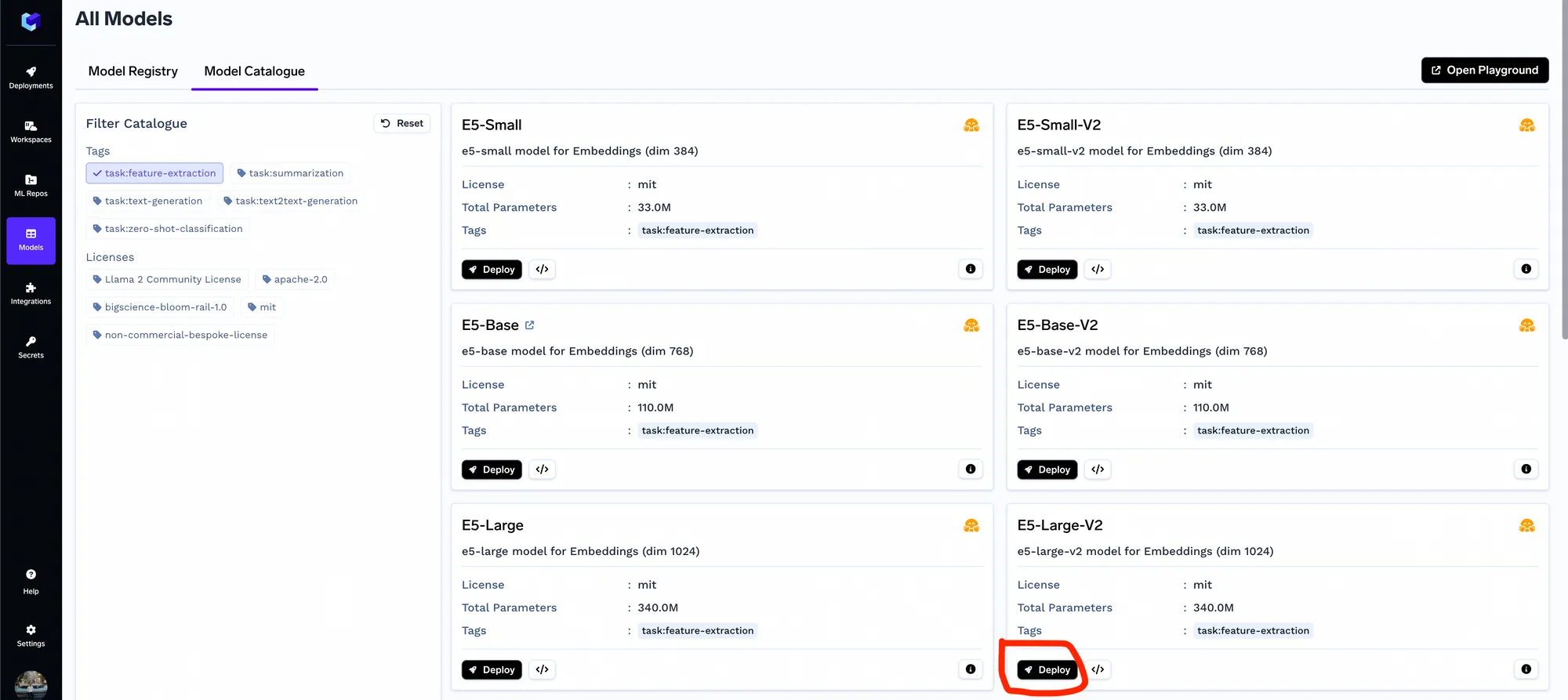
Once the embedding model is deployed, you can check the APIs using the OpenAPI playground on the Truefoundry dashboard.
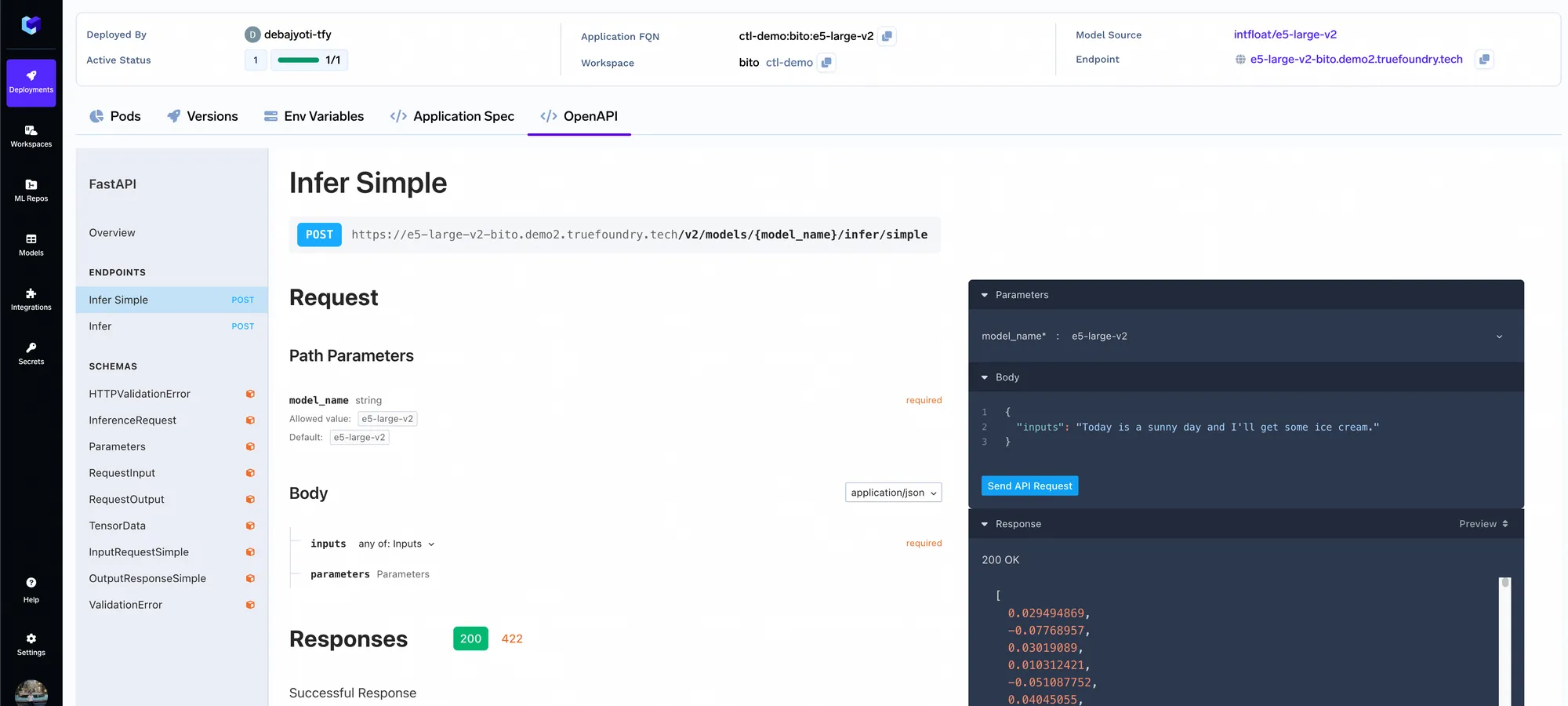
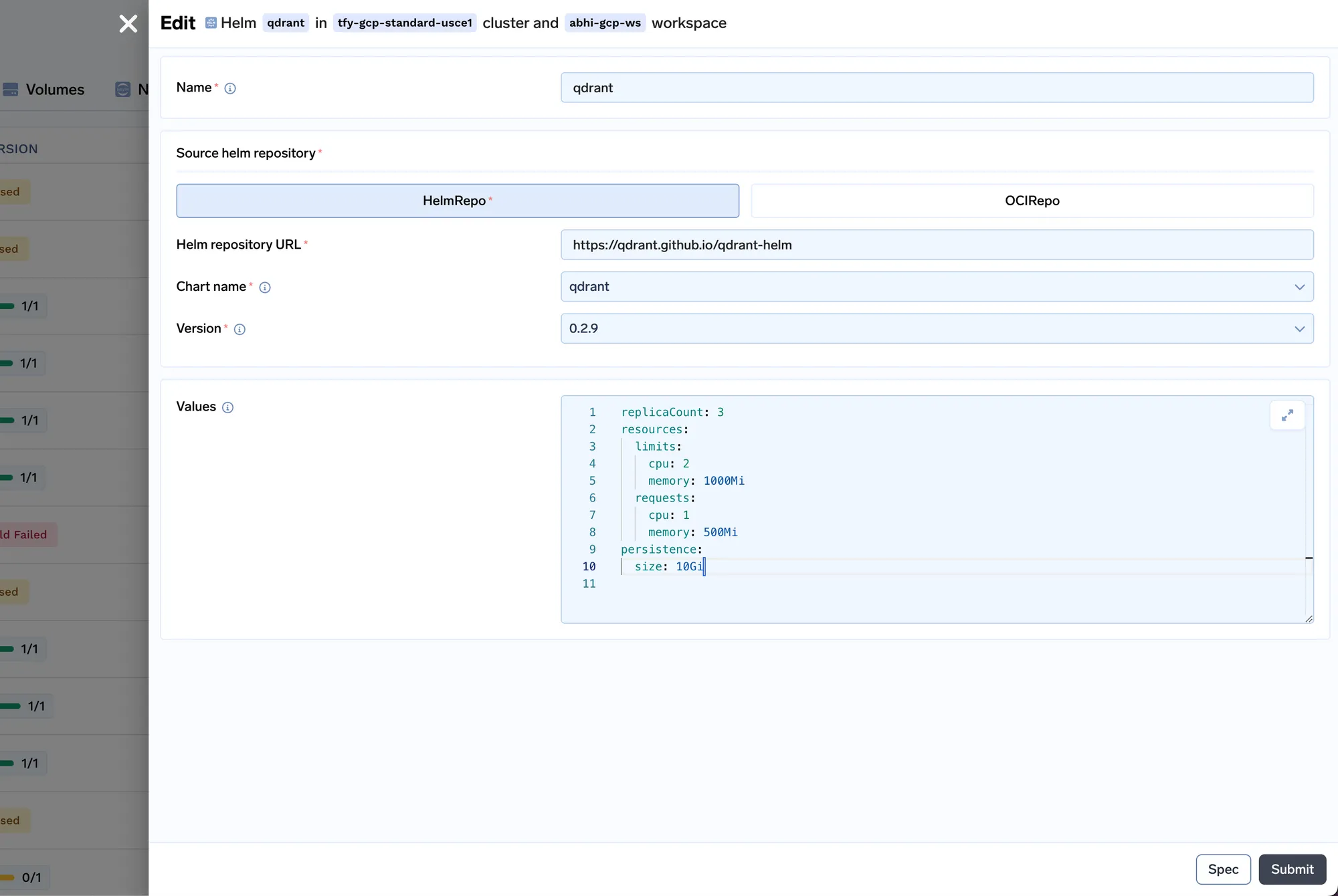
We will be deploying the Qdrant VectorDB.
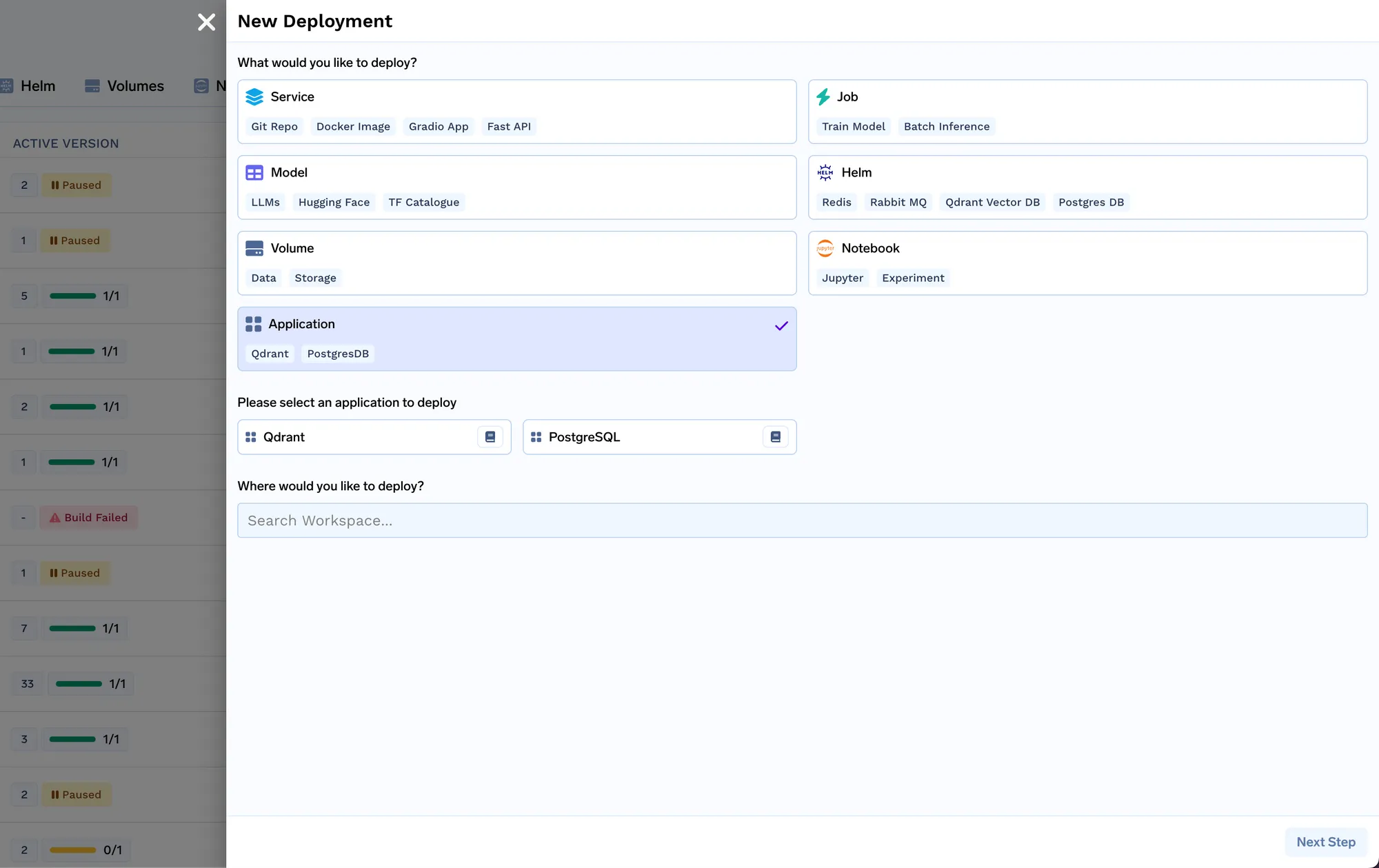
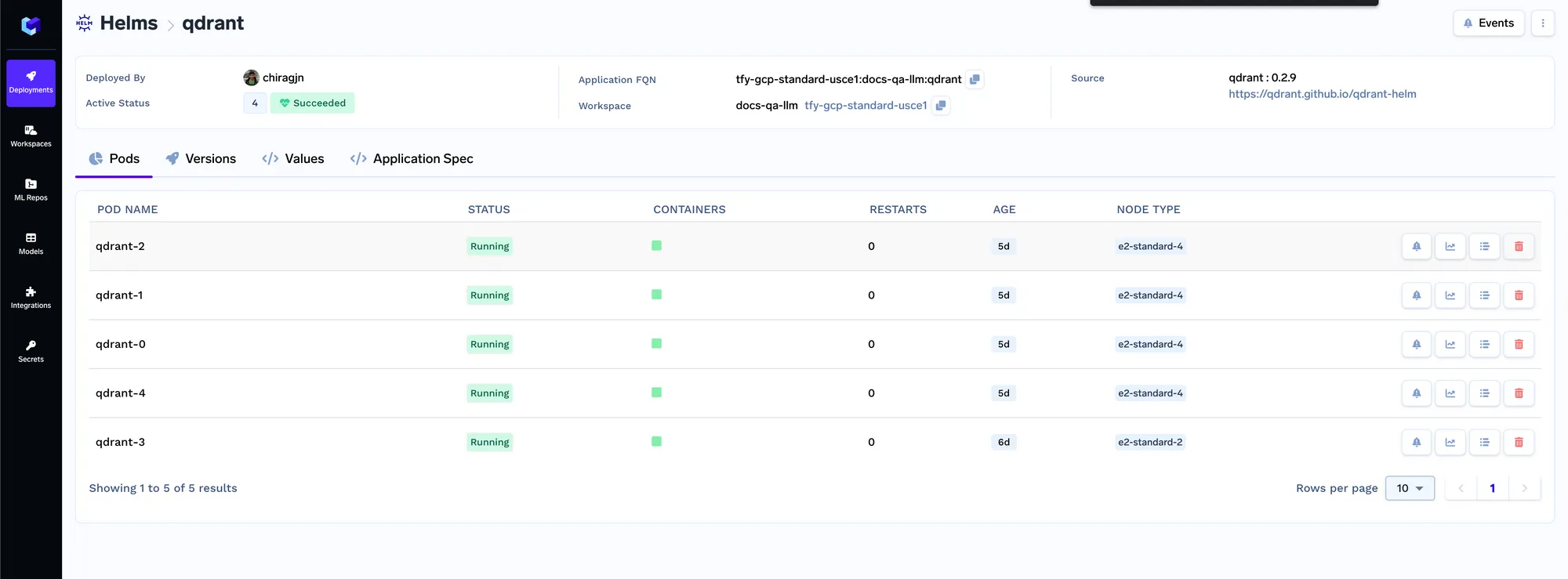
We will now deploy the indexer job. Job in Truefoundry allows us to run a script one time or on schedule and then the compute shuts down after the job is over. The indexer job code can be found here: https://github.com/truefoundry/docs-qa-playground/tree/main/backend/train. The indexer job supports loading data from local files or from a mlfoundry artifact. It also automatically renders a form in which you can provide arguments to trigger the job. You can enter the artifact fqn we copied in step 1 and past it in the source uri field as mlfoundry://<artifact_fqn>. The repo name can be any random string that helps you identify this indexing job. You also have to enter the name of the ML repo that we created in step 1.
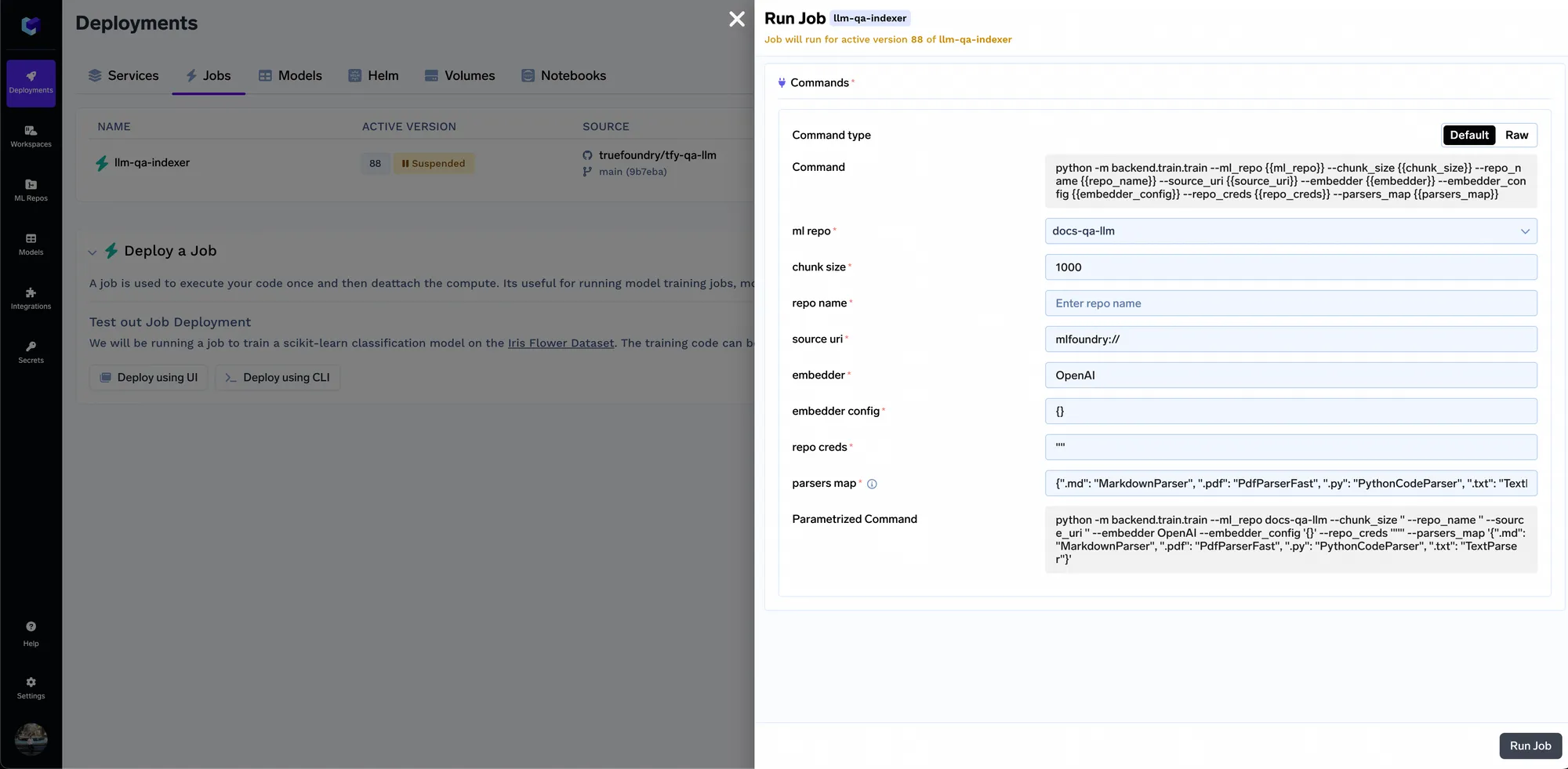
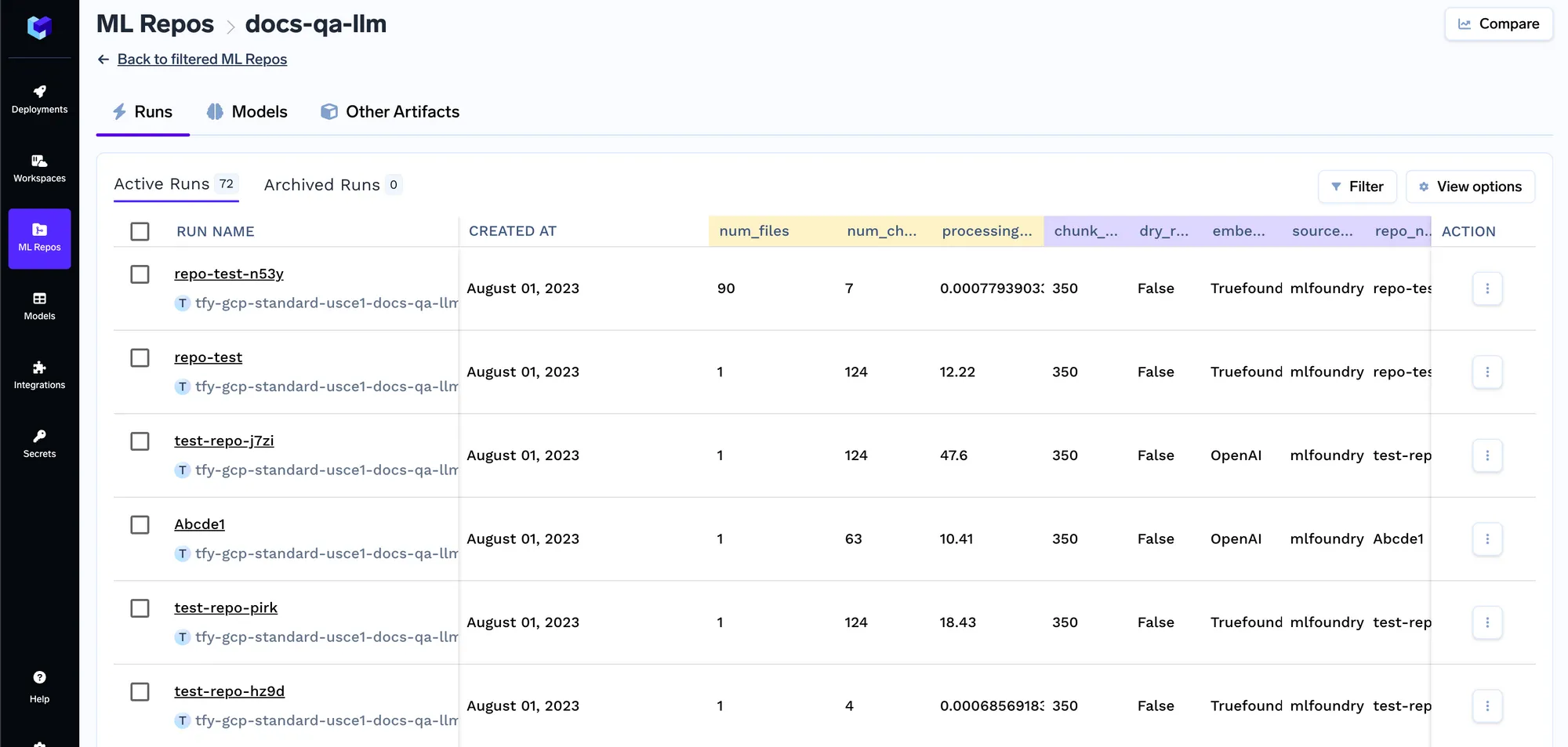
Once the job starts running, you can track all the job runs and their logs:
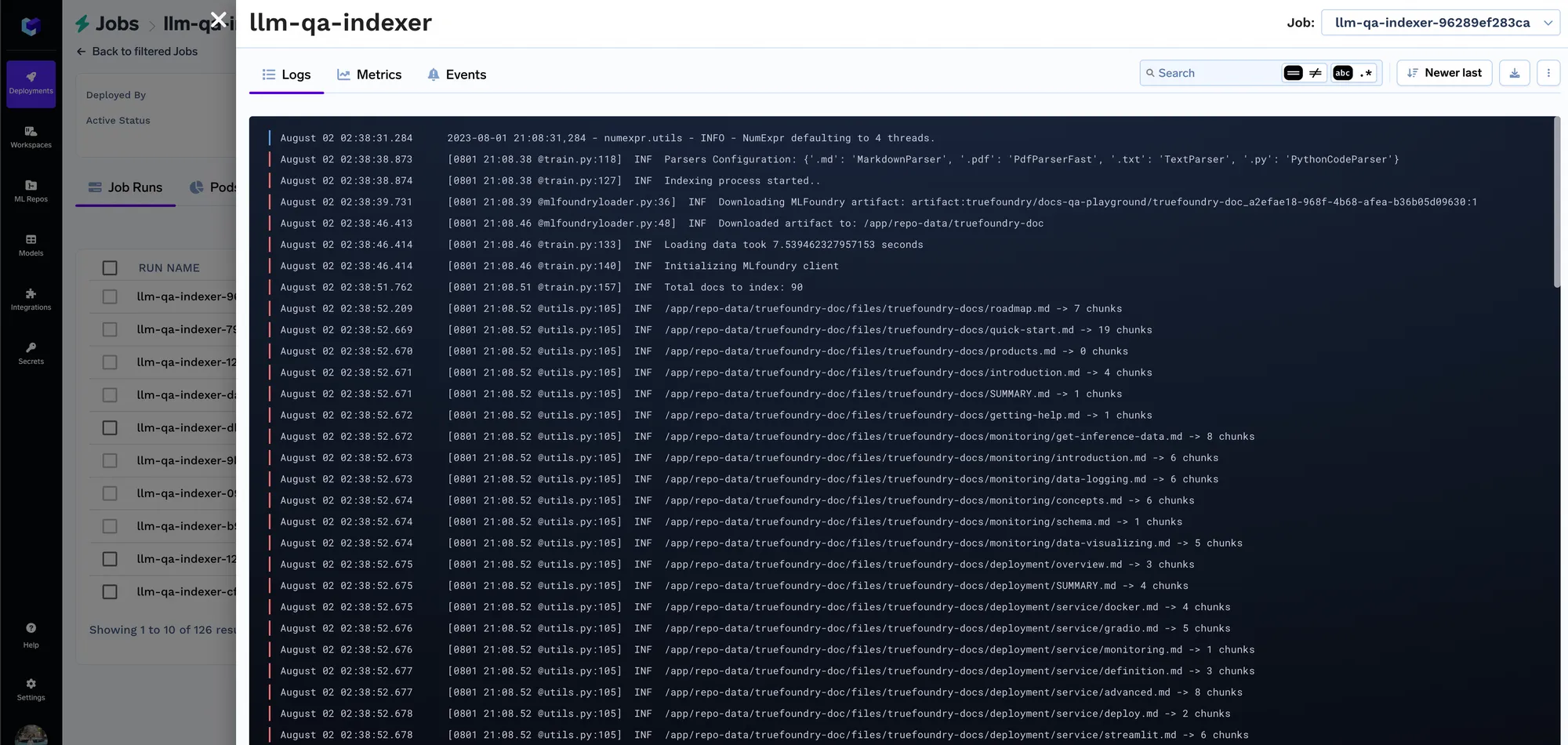
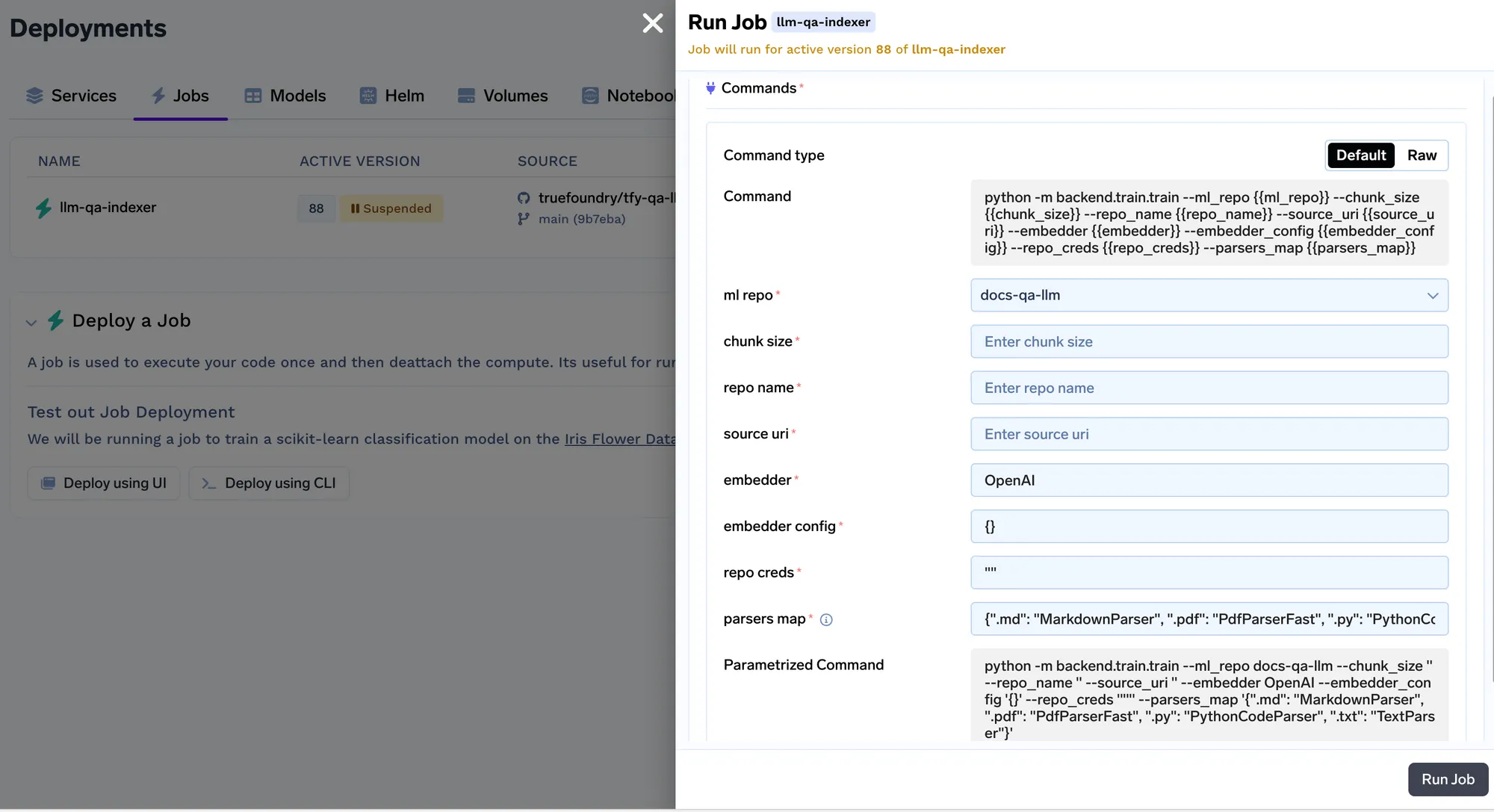
Every time the job runs, we create a run in the ML repo that stores all the embedding settings and the parameters of the indexer job. These settings are later used by the query service to figure out the embedding settings to use for embedding the query. You can track the details of all indexing jobs in the runs tab.
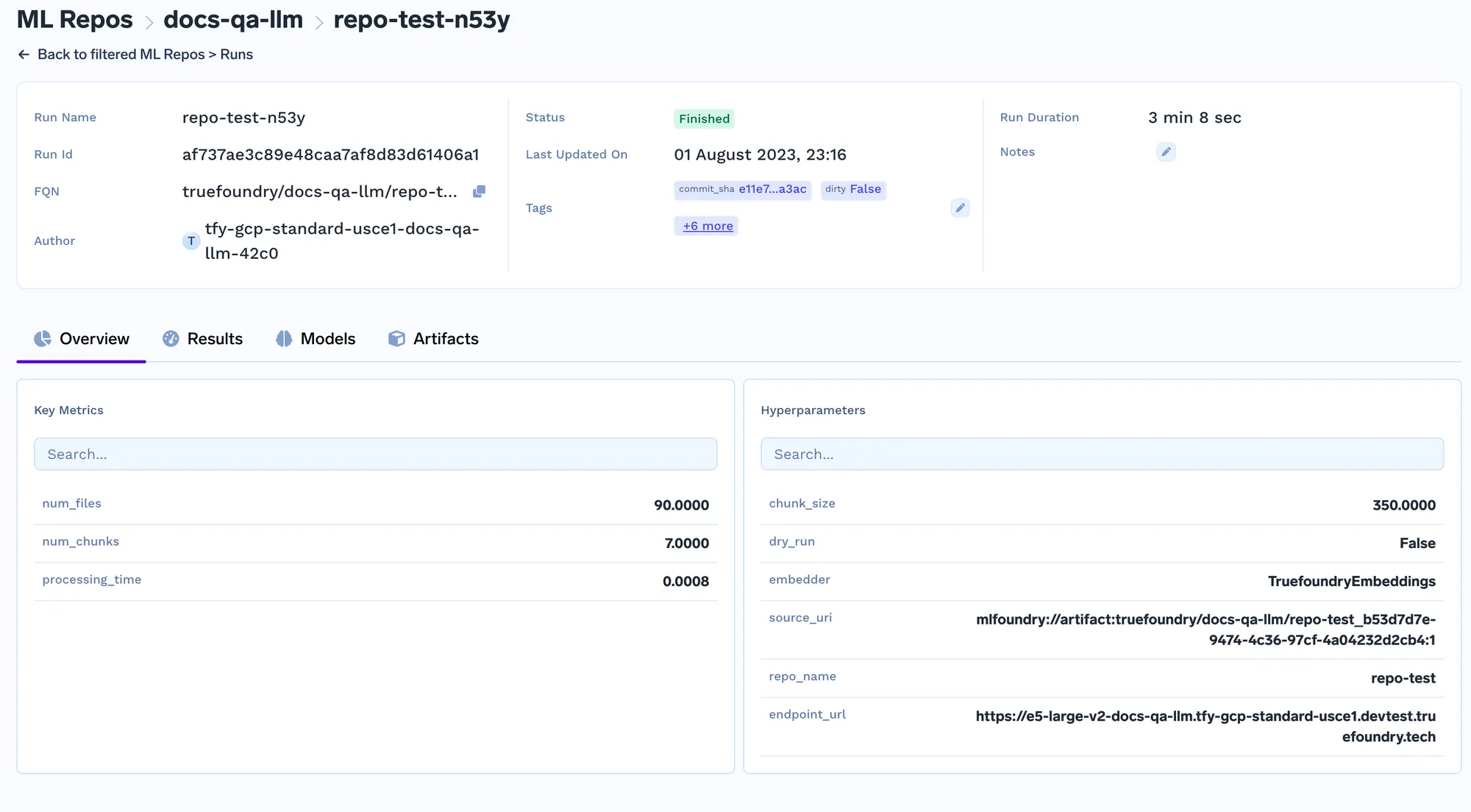
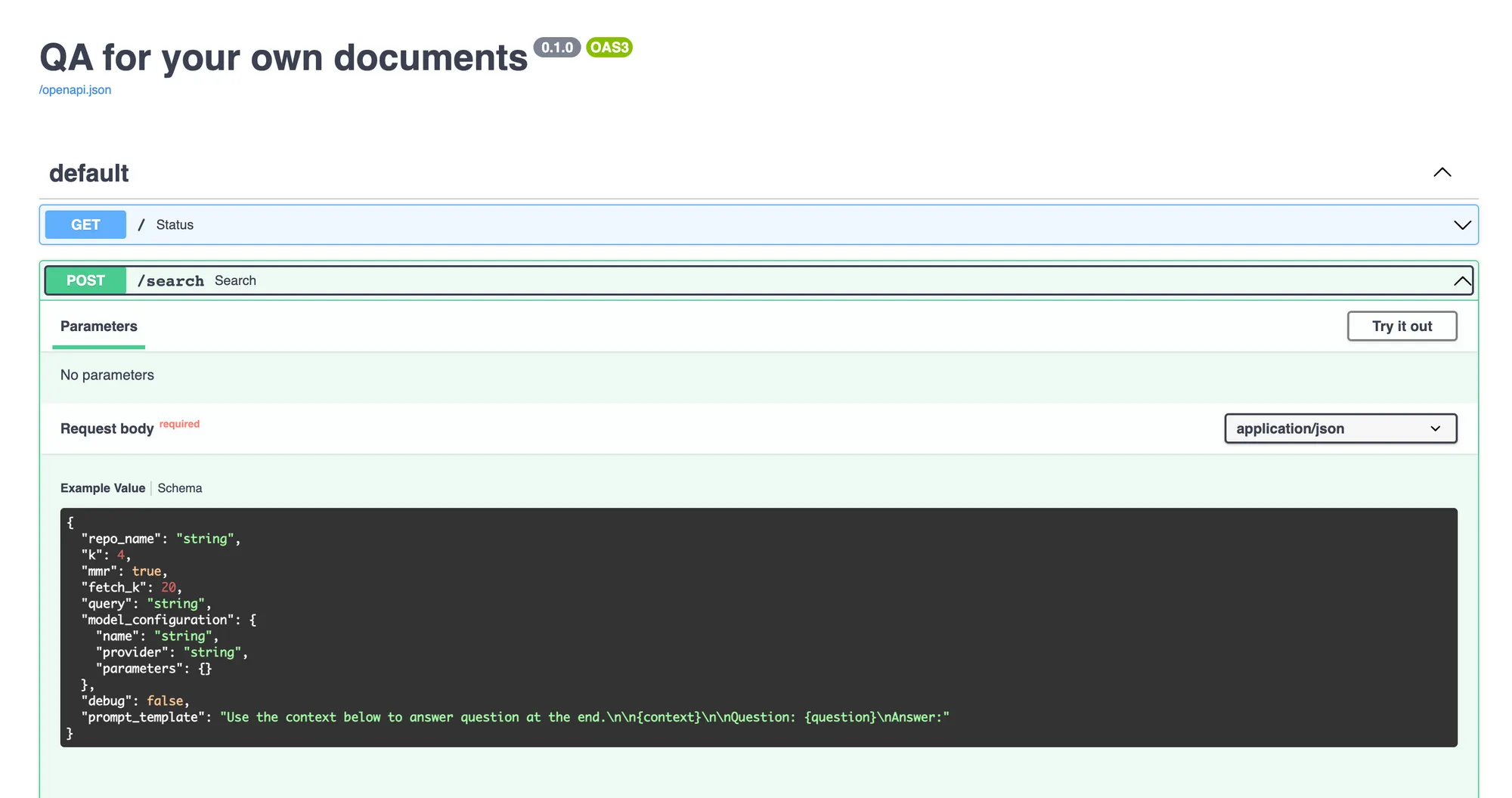
The query service is a fastapi server that has an api to get the query and get the response from the LLM. Once you deploy it, you can make queries using the Swagger UI on fastapi.
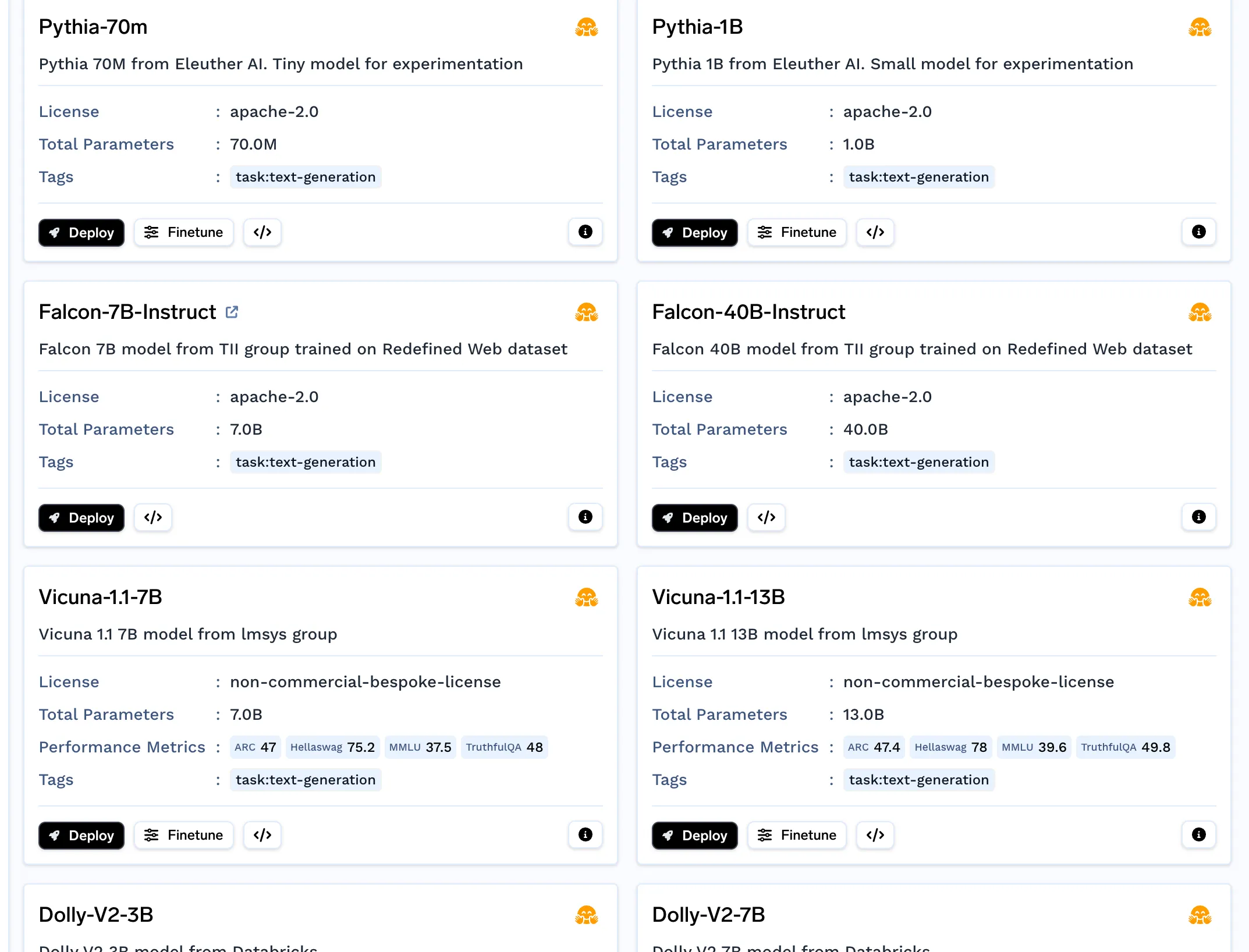
This is needed if you are planning to use an open-source LLM and not OpenAI. You can deploy the LLM from the model catalogue.
We also provide a streamlit app that can tie up to your indexing backend, query service and metadata store to list all the indexed repositories and query over them. A sample demo of this is hosted at https://www.truefoundry.com/docs/create-and-setup-your-account. You can find the code in the github repo here. To make this frontend work, you will have to link it to your query service and job using environment variables:
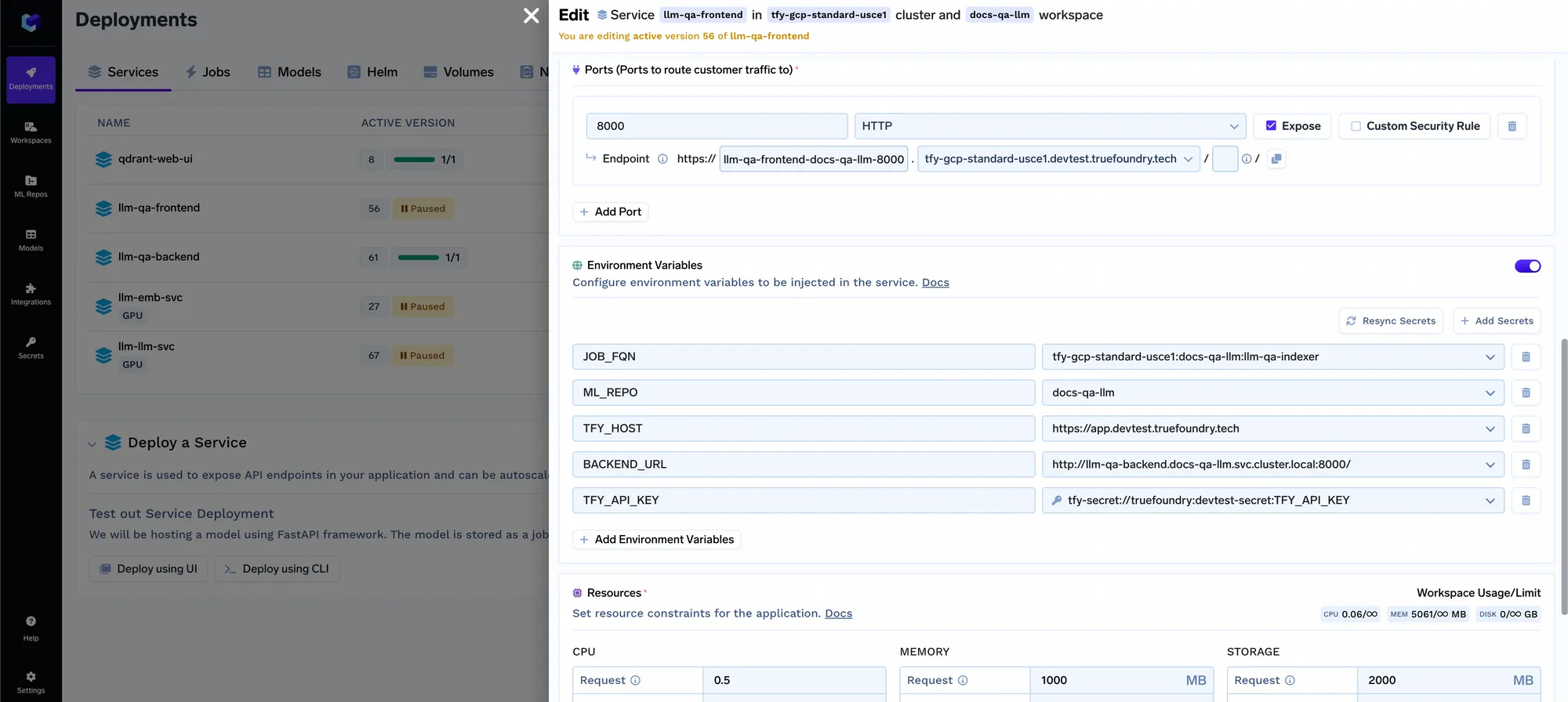
Now we have an end to end system with a frontend that can scale to as many different usecases and document sets within the organization. There are a few things we want to incorporate in the future:
This architecture also enables have a central document indexing service in an organization which relies on a central library of data loaders and parsers.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




