November 5, 2025
|
5 min read


Get instant access to a live TrueFoundry environment. Deploy models, route LLM traffic, and explore the full platform — your sandbox is ready in seconds, no credit card required.









Updated: August 17, 2022
Blazingly fast way to build, track and deploy your models!
Configuration Management is an important aspect of software engineering. This article will highlight the why and what of the problem and reason about the different solutions that exist.

The approach to managing configuration changes as the app scales — both in terms of traffic and developer team size. To illustrate the journey, lets start with a simple app.
This is a simple server app that connects to MongoDB and returns the list of users. The code is just pseudo code and is not meant to adhere to any language.

Hardcode configuration in app: a BIG NO!

Hardcoding the MongoDB uri into the app will it really hard to run the application in any other environment — like fellow teammates’ laptops, or for production. We should follows the 12 factor app methodology here to separate config from code.
“ SEPARATE CONFIGURATION FROM CODE “
Now the question is what comprises an app’s config? Quoting from https://12factor.net/config
An app’s config is everything that is likely to vary between deploys (staging, production, developer environments, etc). This includes:
1. Resource handles to the database, Memcached, and other backing services
2. Credentials to external services such as Amazon S3 or Twitter
3. Per-deploy values such as the canonical hostname for the deploy
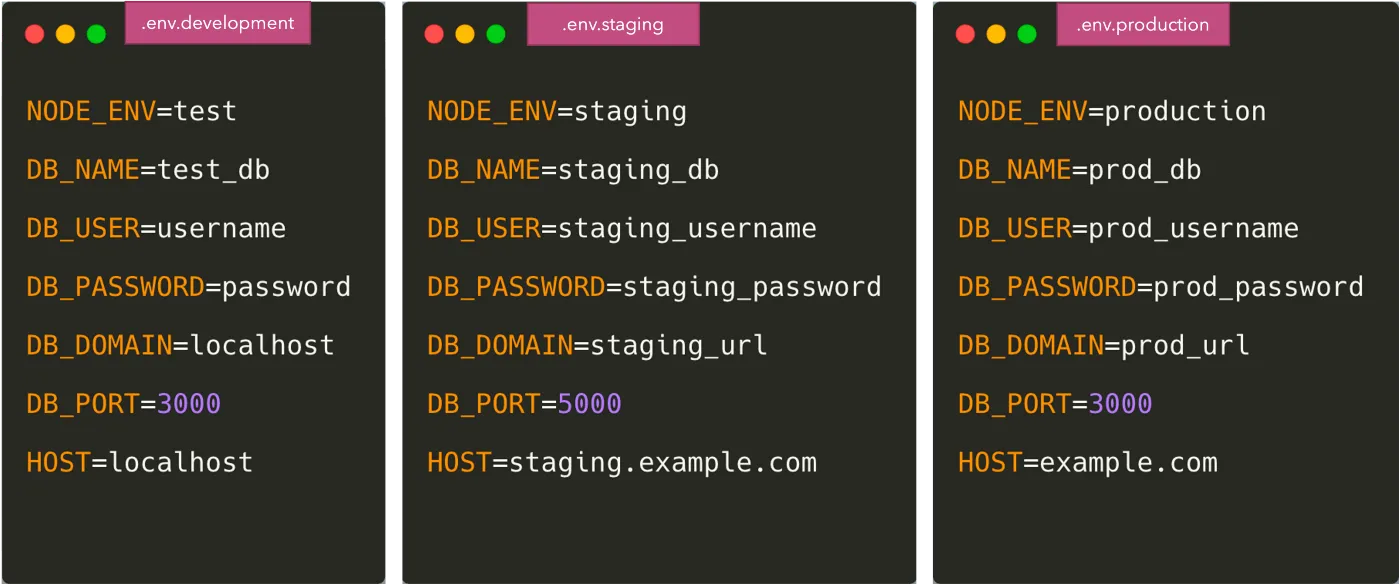
The easiest and most common way to separate configuration from code is to put the variables in a .env file.
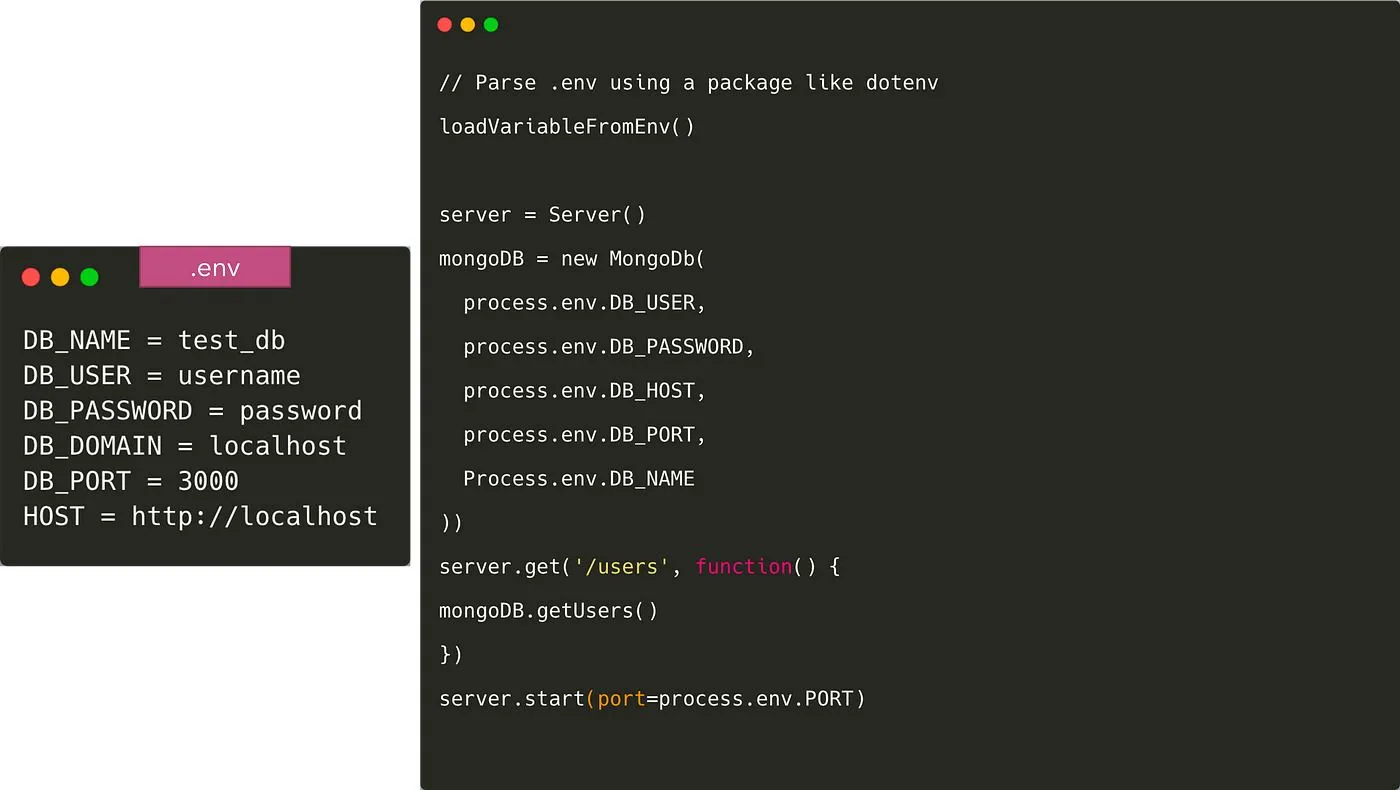
Once we do this, we need to load the variables in code from the .env file. There are several packages to do like dotenv and dotenv-expand. The .env file is not pushed to Git in this case and every developer overwrites the variable according to their own environment. To give all developers an idea of what environment variables need to be added, we usually commit a file like .env.example to Git.

We will also need to provide values of these variables in the staging and production environments. Almost all deployment systems provide a way to store and provide environment variables like ConfigMap and Secrets in Kubernetes, or S3 for Elastic Container Service.
We will need to copy these variables to those environments and keep it synced whenever developers add / remove environment variables. One possible approach is to have a separate .env file for staging, production, etc environments.

One may suggest storing these files in Git but there is a big security issue in that case — specially for some of the sensitive credentials in the env files.
People use different approaches here — however some of the well known methods are:

While using any of these external systems, we have now split the configuration between the .env files and the secretmanagers. Some of the non-sensitive params will come from the .env files and some will come from the remote storage of credentials. We can argue that we can store all the params in the remote storage — but it can be an overkill sometimes. So now what we end up with is:
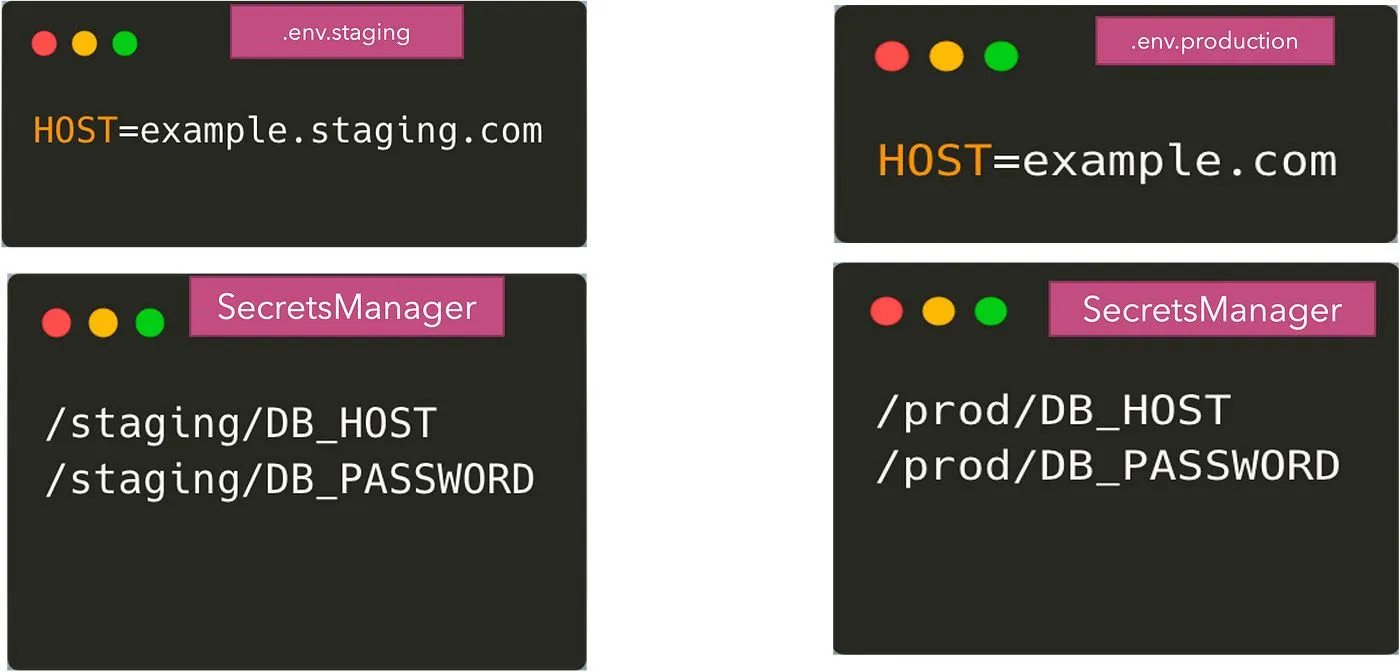
Our application now needs to have code to read from both these sources of configuration. Reading from the .env files can be done using the dotenv package, however, getting the environment variables from the secretmanagers requires us to use their corresponding APIs to get the values.

This solves the issue of keeping our configuration secure and also follow the 12-factor methodology.
However, writing application code to get secrets ends up being a repetitive practice wherein every application now needs to add secretmanager specific code to get the values from the api. This also means that if we ever change our secretsmanager provider. the code in all the applications needs to change. To solve this problem, there can be a few approaches:
Configuration management is complex and should be done properly from the start to ensure developer velocity remains high without sacrificing security aspects. Kubernetes, which is most widely used today to deploy applications comes with its own configuration and secret management, which I will dive into in another article. Also, if you are using some other way for configuration management, please mention it in the comments — I would love to know more and learn from you!
TrueFoundry is an enterprise-grade AI gateway that encompasses an LLM , MCP, and agent aateways, enabling enterprises to securely connect, observe, and govern access to models, tools, guardrails, and agents from a single control plane. The AI Gateway enables agentic workloads that are:
a) Secure — solving for key management, authentication, and authorization
b) Efficient — optimizing cost, latency, and multi-region failovers
c) Future-safe — enabling unified and composable connections across LLMs, MCPs, and guardrails from any provider
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.







The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.












.webp)
.webp)