Volumes provide persistent storage to containers within pods so that they can read and write data to a central disk across multiple pods. They are especially useful in machine learning when you need to store and access data, models, and other artifacts required for training, serving, and inference tasks.
In this blog, we will discuss how to utilize volumes and the options available in each cloud.
When to use Kubernetes volumes?
A few usecases where volumes turn out to be very useful:
Share training data: It's possible multiple data scientists are training on the same data, or we are running multiple experiments in parallel on the same dataset. The naive way will be to duplicate the data for multiple data scientists—however, this will end up costing us much more. A more efficient way here will be to store the training data in a volume and mount the volume to the notebooks of different data scientists.
Model Storage: If we are hosting models as real-time APIs, there will be multiple replicas of the API server to handle the traffic. Here, every replica must download the model from the model registry (say S3) to the local disk. If every replica does this repeatedly, it will take more time to start up and also incur more S3 access costs. Using volumes, you can store your trained models externally and mount them onto the inference server. There is no need to download the model; the API server can just find the model on disk at the mounted path.
Artifact Sharing: We might have a usecase wherein the output of one pipeline stage needs to be consumed by the next stage. For example, after finetuning a model, we might need to host it as an API just for experimentation. While we can write the model to S3 and then download it back from S3, it will take a lot of time just for the model upload/download process. Instead, for faster experimentation, the finetuning job can just write the model to a volume, and the inference service can then mount the volume with the model.
Checkpointing: During the training of machine learning models, it's common to save checkpoints periodically to resume training in case of failure or to fine-tune models. Volumes can be used to store these checkpoint files, ensuring that training progress is not lost when a job restarts from failure. This also enables you to run training on-spot instances, saving a lot of costs.
Now, talking about ML use cases. In most of the cases, the ML Engineers get the data in S3 Bucket GCS Buckets, or Azure Blob Storage. Now, if they want to train models on this data, they need to download the data onto their training workload (deployed job or notebook) or mount the contents of their bucket directly on the workload.
When to use Volume vs Blob storage like S3 / GCS / Azure Container?
Choosing when to choose blob storage like S3 vs. volume is important from a performance, reliability, and cost perspective.
Performance
In most cases, reading data from S3 will be slower than reading data directly from a volume. So if the loading speed is crucial for you, volume is the right choice. An excellent example of this is downloading and loading the model at inference time in multiple replicas of the service. A volume is a better choice since you don't incur the time of downloading the model repeatedly and can load the model in memory from volume much faster.
Reliability
Blob storages like S3/GCS/ACS will generally be more reliable than volumes. So, you should ideally always back up the raw data in one of the blob storages and use volumes only for intermediate data. You should also permanently save a copy of the models in S3.
Cost
Access to volumes like EFS is a bit cheaper than using S3 - so if you read for the same data quite frequently - it might be helpful to store it in a volume. If you are reading or writing very infrequently, then S3 should be just fine.
Access Constraints
Data in volumes should ideally only be accessed by workloads within the same region and cluster. S3 is meant to be accessed globally and across cloud environments, so volumes are not a great choice if you want to access the data in a different region or cloud provider.
Volume Provisioning Modes
To support all types of volumes, TrueFoundry provides two volume provisioning modes catering to different use cases:
Dynamic
These are volumes that are created dynamically and provisioned as you deploy a volume on truefoundry. E.g., EBS, EFS in AWS, and AzureFiles in Azure can be dynamically provisioned on Truefoundry.
Static
These are volumes for which a storage volume already exists and we want to mount the data in that storage volume to our service/job. Examples include mounting S3 buckets and GCS buckets on the workloads deployed on the platform.
So, let us understand how these two work and what options are available in each cloud:
Dynamically Provisioned Volumes
Dynamically Provisioned Volumes require you to specify a storage class. A volume is dynamically provisioned according to the storage class and size provided by the user.
So, let us understand what is a storage class and the different storage classes available in each cloud:
Storage Classes
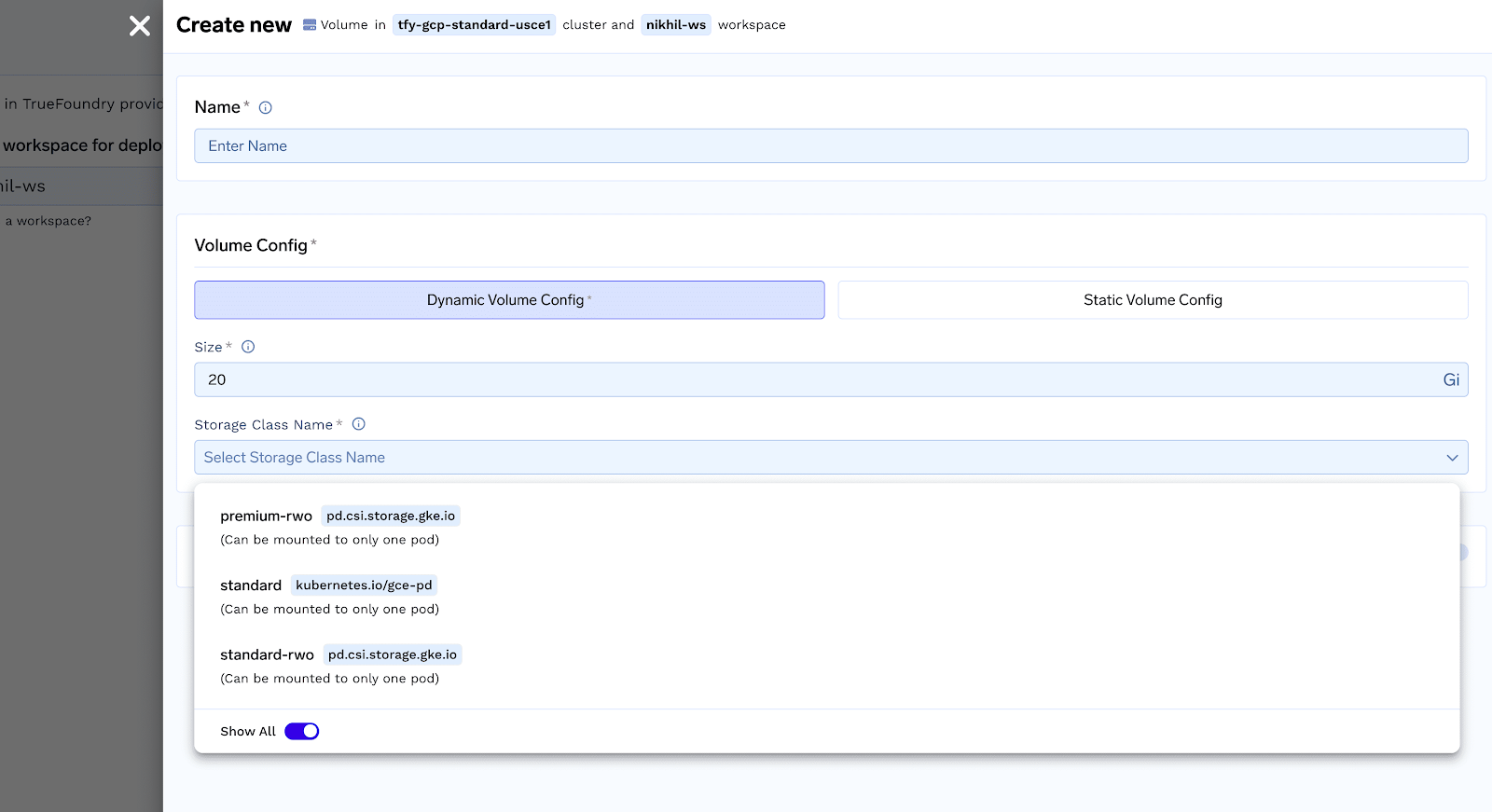
Storage classes provide a way to specify the type of storage that should be provisioned for a Volume. These storage classes differ in their characteristics, such as performance, durability, and cost. You can select the appropriate storage class for your Volume from the Storage Class dropdown menu while creating it.
The specific storage classes available will depend on the cloud provider you are using and what is preconfigured by the Infra team. You will usually see the following options in the storage classes based on the cloud provider:
AWS Storage Classes
TrueFoundry Storage Name
Cloud Provider Storage Name
Storage Class
Description
efs-sc
Elastic File System (EFS)
efs.csi.aws.com
A fully managed, scalable, and highly durable elastic file system that offers high availability, automatic scaling, and cost-effective general file sharing. It's suitable for workloads with varying capacity needs.
GCP Storage Classes
TrueFoundry Storage Name
Cloud Provider Storage Name
Storage Class
Description
standard-rwx
Google Basic HDD Filestore
filestore.csi.storage.gke.io
A cost-effective and scalable file storage solution ideal for general-purpose file storage and cost-sensitive workloads. It offers lower cost but also lower performance due to its HDD-based nature.
premium-rwx
Google Premium Filestore
filestore.csi.storage.gke.io
Provides higher performance and throughput compared to Basic HDD, making it suitable for I/O-intensive file operations and demanding workloads. It's SSD-based, offering higher performance at a higher cost.
enterprise-rwx
Google Enterprise Filestore
filestore.csi.storage.gke.io
Delivers the highest performance, throughput, advanced features, multi-zone support, and high availability, making it ideal for mission-critical workloads and applications with strict availability requirements. It comes with the highest cost.
Azure Storage Classes
TrueFoundry Storage Name
Cloud Provider Storage Name
Storage Class
Description
azurefile
Azure File Storage (Standard)
file.csi.azure.com
Uses Azure Standard storage to create file shares for general file sharing across VMs or containers, including Windows apps. It offers cost-effective performance.
azurefile-premium
Azure File Storage (Premium)
file.csi.azure.com
Uses Azure Premium storage for higher performance, making it suitable for I/O-intensive file operations.
azurefile-csi
Azure File Storage (StandardCSI)
file.csi.azure.com
Leverages Azure Standard storage with CSI for dynamic provisioning, potentially offering better performance and CSI features.
azurefile-csi-premium
Azure File Storage (PremiumCSI)
file.csi.azure.com
Combines Azure Premium storage with CSI for dynamic provisioning and high-performance file operations.
azureblob-nfs-premium
Azure Blob Storage (NFS Premium)
blob.csi.azure.com
Uses Azure Premium storage with NFS v3 protocol for accessing large amounts of unstructured data and object storage, catering to demanding workloads with NFS access.
azureblob-fuse-premium
Azure Blob Storage (Fuse Premium)
blob.csi.azure.com
Uses Azure Premium storage with BlobFuse for accessing large amounts of unstructured data and object storage, suitable for workloads that require BlobFuse access.
Statically Provisioned Volumes
Statically provisioned volumes enable you mount the following as a volume:
GCS Bucket
S3 bucket
Existing EFS
Any general volume on Kubernetes
To use statically provisioned volumes, you need to create a “PersistentVolume” which refers to your storage (S3/GCS etc). This will require you to install the necessary CSI drivers on the cluster and/or setup relevant serviceaccounts for permissions. The next section we will discuss how you can create statically provisioned volumes.
Mount a GCS bucket as volume
To mount a GCS bucket as a volume on truefoundry, you need to follow the following steps. You can refer to this document for more details:
Create a GCS bucket
Create a GCS bucket and ensure the following:
Should be single region ( multi-region will work but speed will be slower and costs will be higher )
Region should be the same as that of your Kubernetes Cluster
Create Service account and Grant relevant permissions
You need to run the following script. This does the following:
Enables GCS Fuse Driver on the cluster
Create IAM Policy to access your bucket
Create K8s service-account and add policy to this service-account
Enables role-binding of service account to the desired K8s namespace.
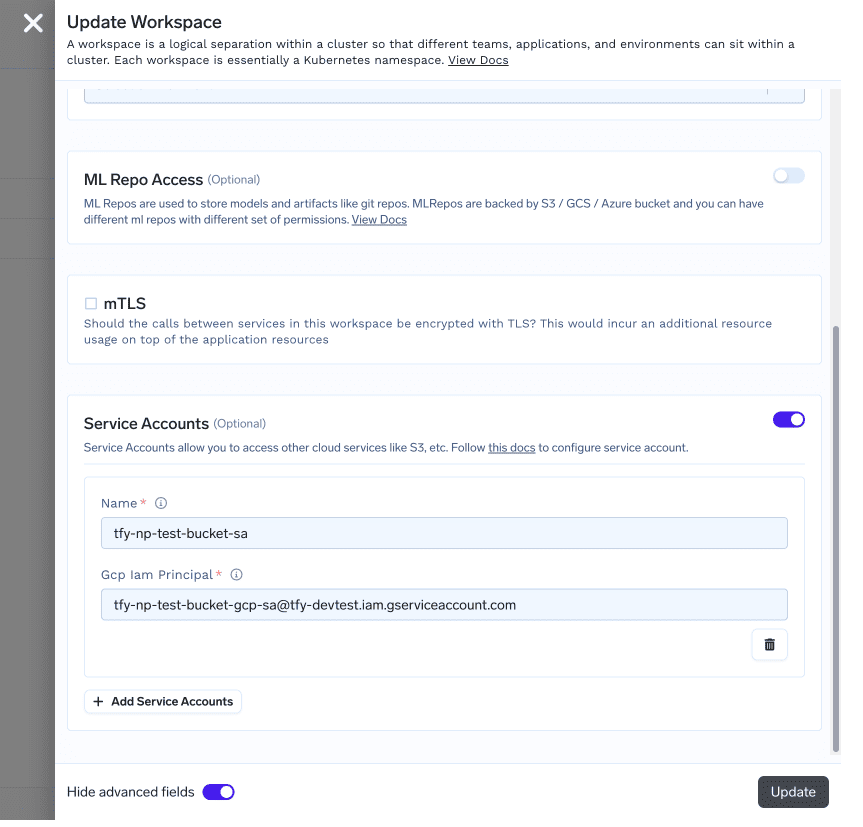
Create Service-Account in Workspace from Truefoundry UI
We now need to create a service account on TrueFoundry in the same workspace with name: TARGET_NAMESPACEand the service account must have the name GCP_SA_NAME.
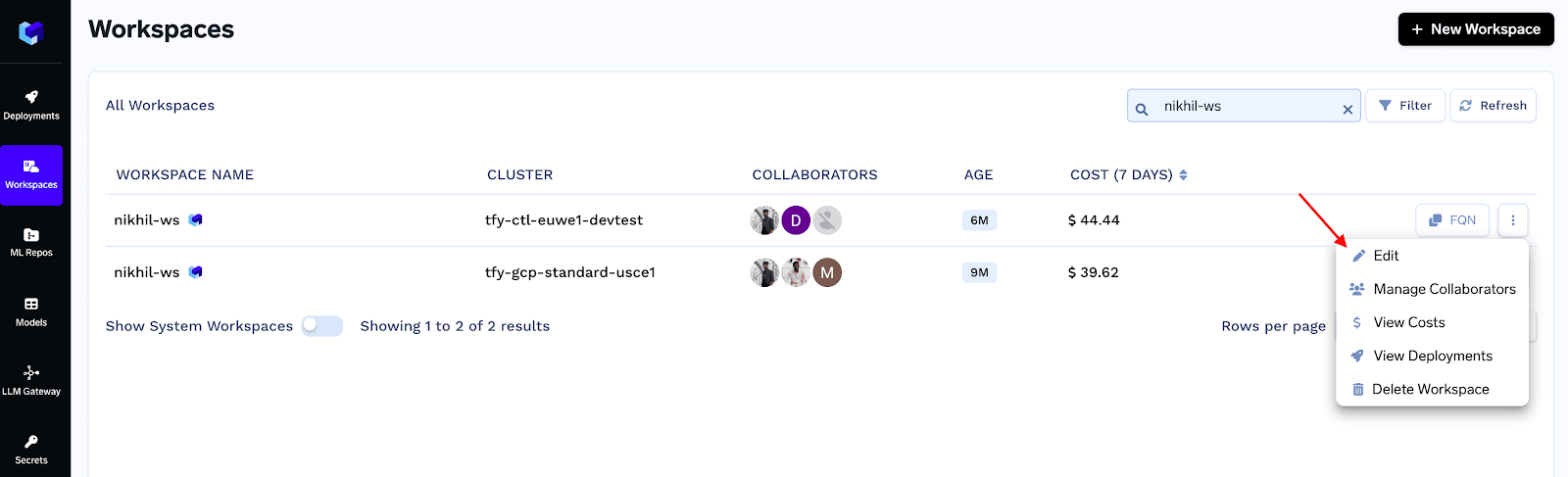
Go to Workspaces -> Choose Your Workspace and Click on three dots on the right and click on Edit:
Open Advanced Options from the bottom left of the form and fill in the Serviceaccount section:
Note
The service account name and workspace should be exactly same as the previous step.
Create a PersistentVolume object
Create a persistent volume object with the following step. (by doing a kubectl apply)
To mount an S3 bucket as a volume on Truefoundry, you need to follow the following steps:
Setting up IAM Policies and Relevant Roles
Please follow this document of AWS to set up mount point of S3 in an EKS cluster.
This will guide you to do the following things:
Create an IAM policy to give permissions for mount point to access the s3 bucket
Create an IAM role.
Install the mountpoint for Amazon S3 CSI driver and attach the role that was created above.
Creating a Persistent Volume on the Kubernetes Cluster
Create a PV with the following spec (by doing a kubectl apply):
YAML
apiVersion: v1
kind: PersistentVolume
metadata:
name:
spec:
capacity:
storage: 100Gi
csi:
driver: s3.csi.aws.com
volumeHandle: s3-csi-driver-volume # must be unique
volumeAttributes:
bucketName:
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
storageClassName: s3-test # put any value here
mountOptions:
- allow-delete
- region
- allow-other
- uid=1000
volumeMode: Filesystem
Mount an Existing EFS as a Volume
To mount an S3 bucket as a volume on TrueFoundry, you need to follow the following steps:
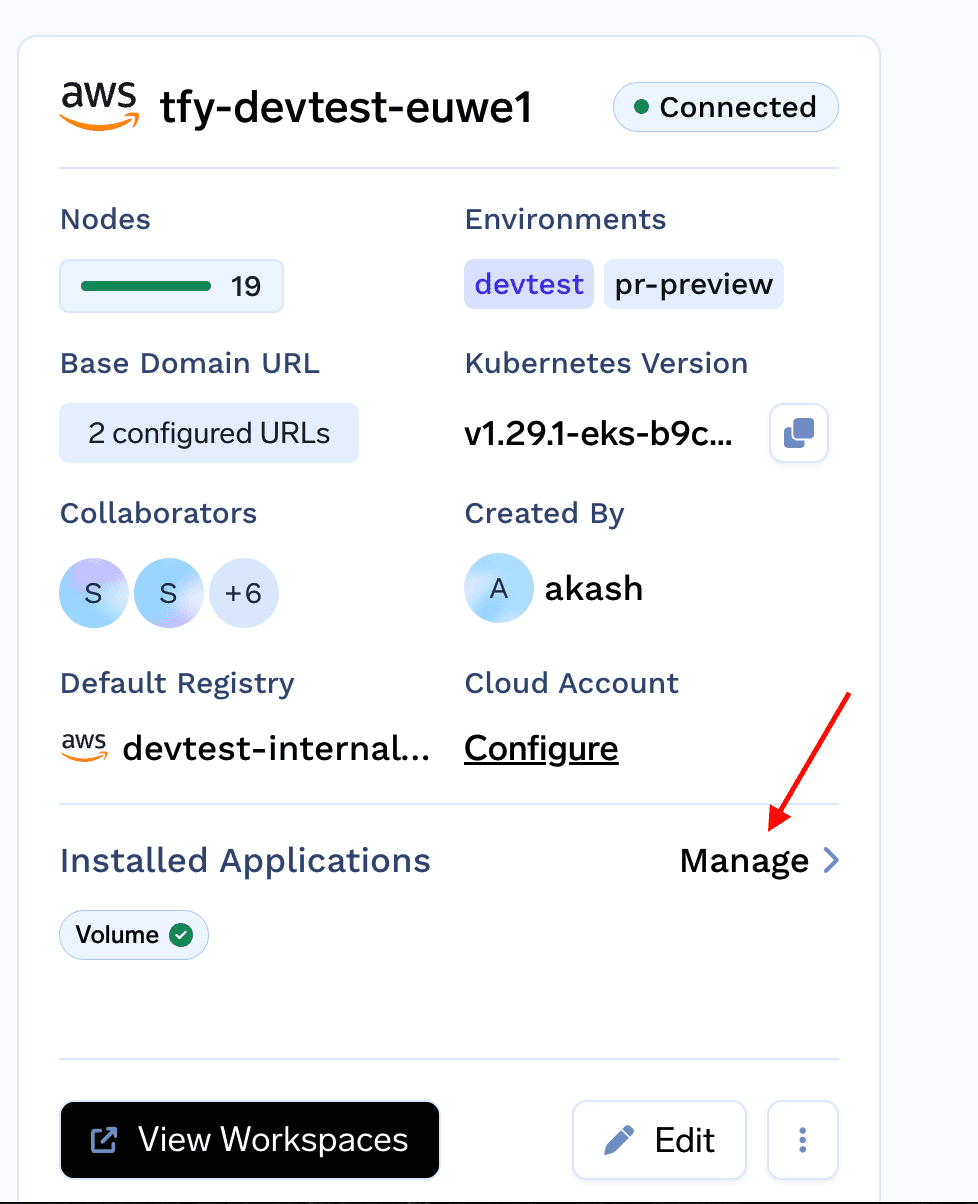
Install EFS CSI driver on your cluster
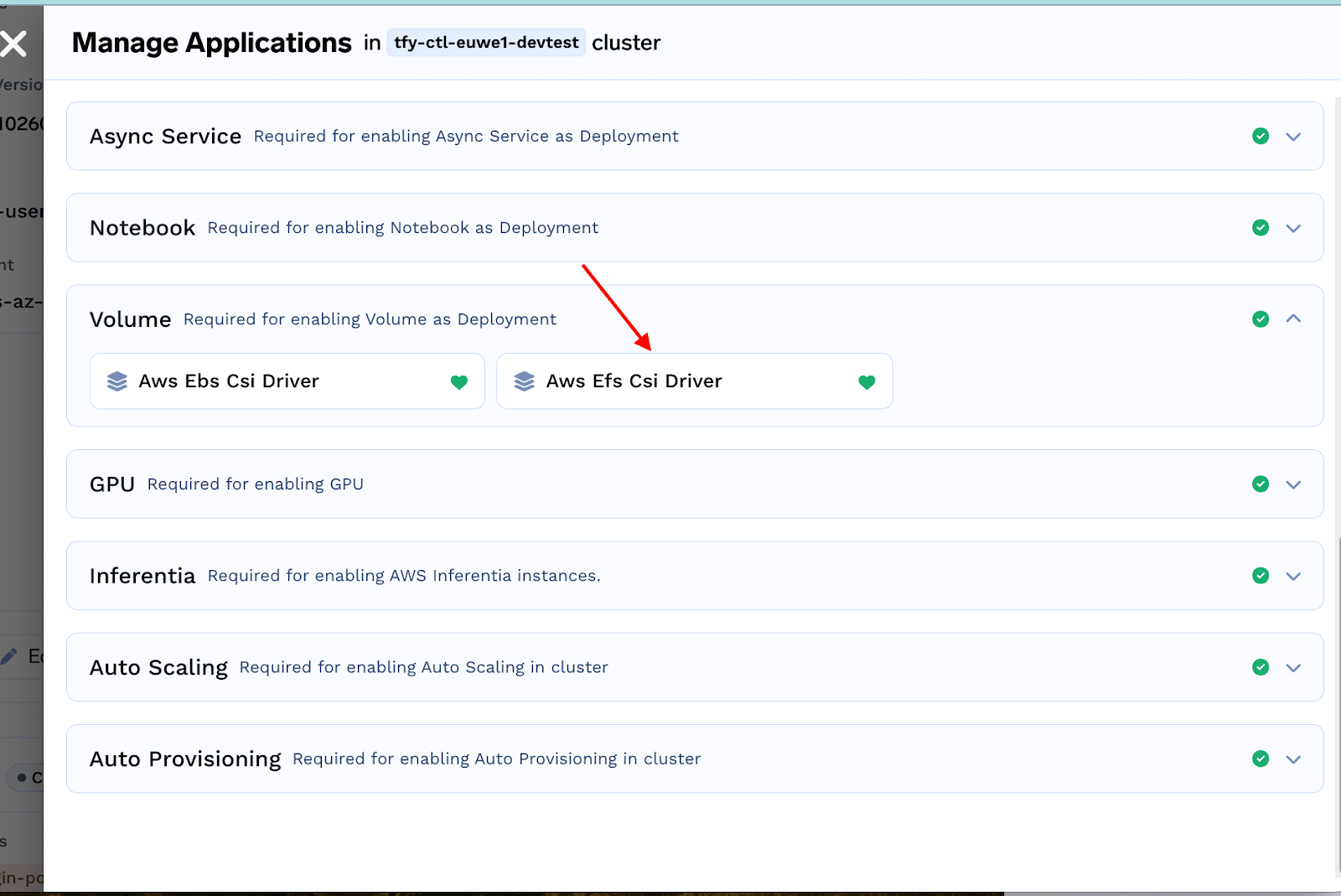
To install EFS CSI driver on your cluster, go to Truefoundry UI -> Clusters-> Installed Applications-> Manage
From the Volumessection click on install AWS EFS CSI driver and click on Install.
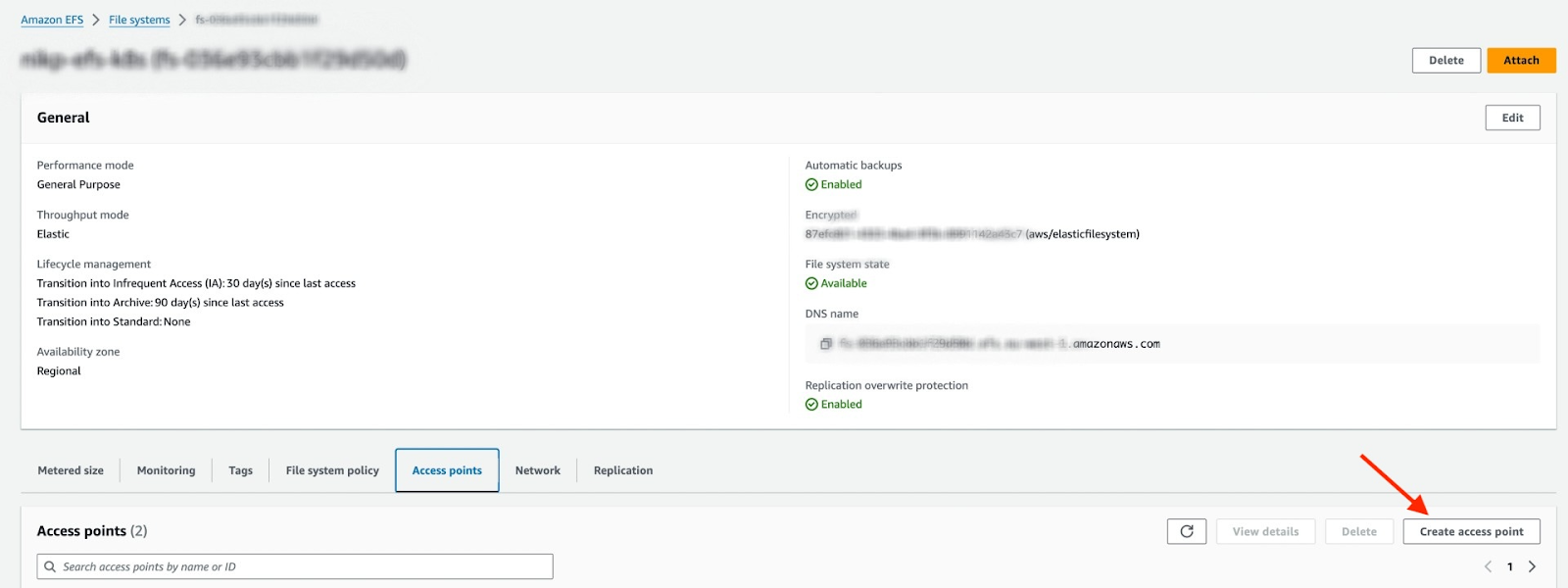
Create an Access Point for your EFS
Locate your EFS in the AWS console and open it. Ensure that the EFS and the K8S cluster are in the same VPC. Click on "Create access point"
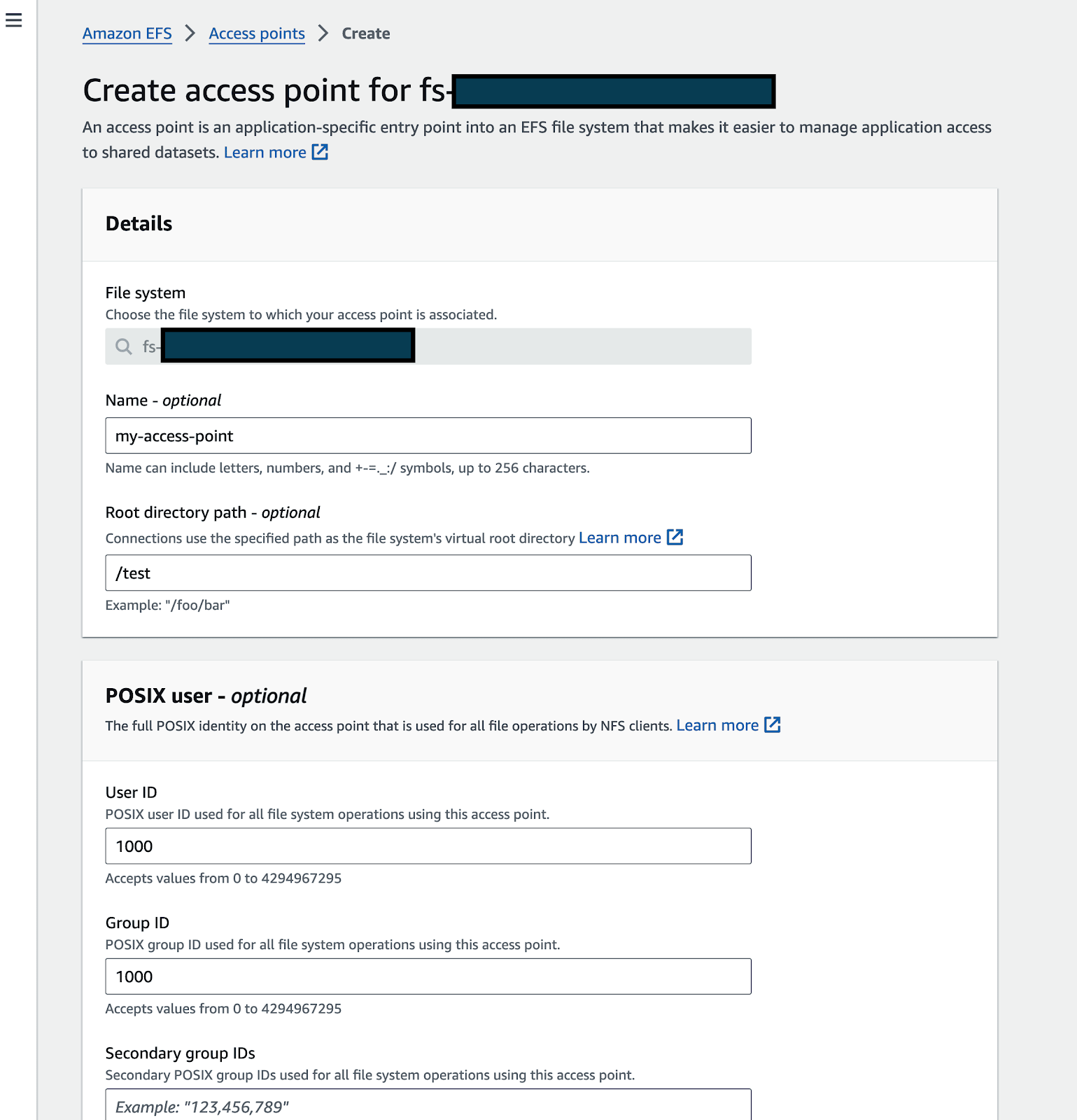
Enter details like name, Root directory path(please make sure you fill in the Root directory creation permissionssection, you can fill in with UID:1000 GID:1000 if you want to attach it to the notebook)
Click on create.
Create a PersistentVolume on the cluster
Create a PV with the following spec (by doing a kubectl apply):
YAML
apiVersion: v1
kind: PersistentVolume
metadata:
name:
spec:
capacity:
storage: 5Gi # this number doesn't matter for EFS, any number will work
csi:
driver: efs.csi.aws.com
volumeHandle: :: # e.g. fs-036e93cbb1fabcdef::fsap-0923ac354cqwerty
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
storageClassName: efs-sc
volumeMode: Filesystem
Create a Volume on TrueFoundry
Please follow this section to create volume on TrueFoundry
Using Volumes on Truefoundry
With the guides above you can easily provision volumes or use existing storage containers as volumes. Now these volumes can be mounted to any workload on Kubernetes. If you are using this you can easily mount your volume to any workload on TrueFoundry. You can easily mount it to a service or similarly any workload deployed on Truefoundry. You can also enable a file browser to browse through the volume's contents in just a few clicks using our volume browser.
Built for Speed: ~10ms Latency, Even Under Load
Blazingly fast way to build, track and deploy your models!
Handles 350+ RPS on just 1 vCPU — no tuning needed
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.


















.png)


