













.webp)
July 3, 2026
|
5 min read

Published: June 14, 2026

Blazingly fast way to build, track and deploy your models!
Large Language Models (LLMs) have taken the AI world by storm—but they’re just the beginning. The real magic happens when LLMs evolve into agents: intelligent, goal-driven systems that can reason, make decisions, and take actions autonomously. LLM agents are transforming how we build AI products, enabling everything from automated research assistants to complex multi-step task solvers. In this ultimate guide, we’ll break down what LLM agents are, how they work, different types, real-world use cases, and the challenges they face. Whether you're a developer, founder, or AI enthusiast—this guide will give you a crystal-clear understanding of the future of intelligent agents.
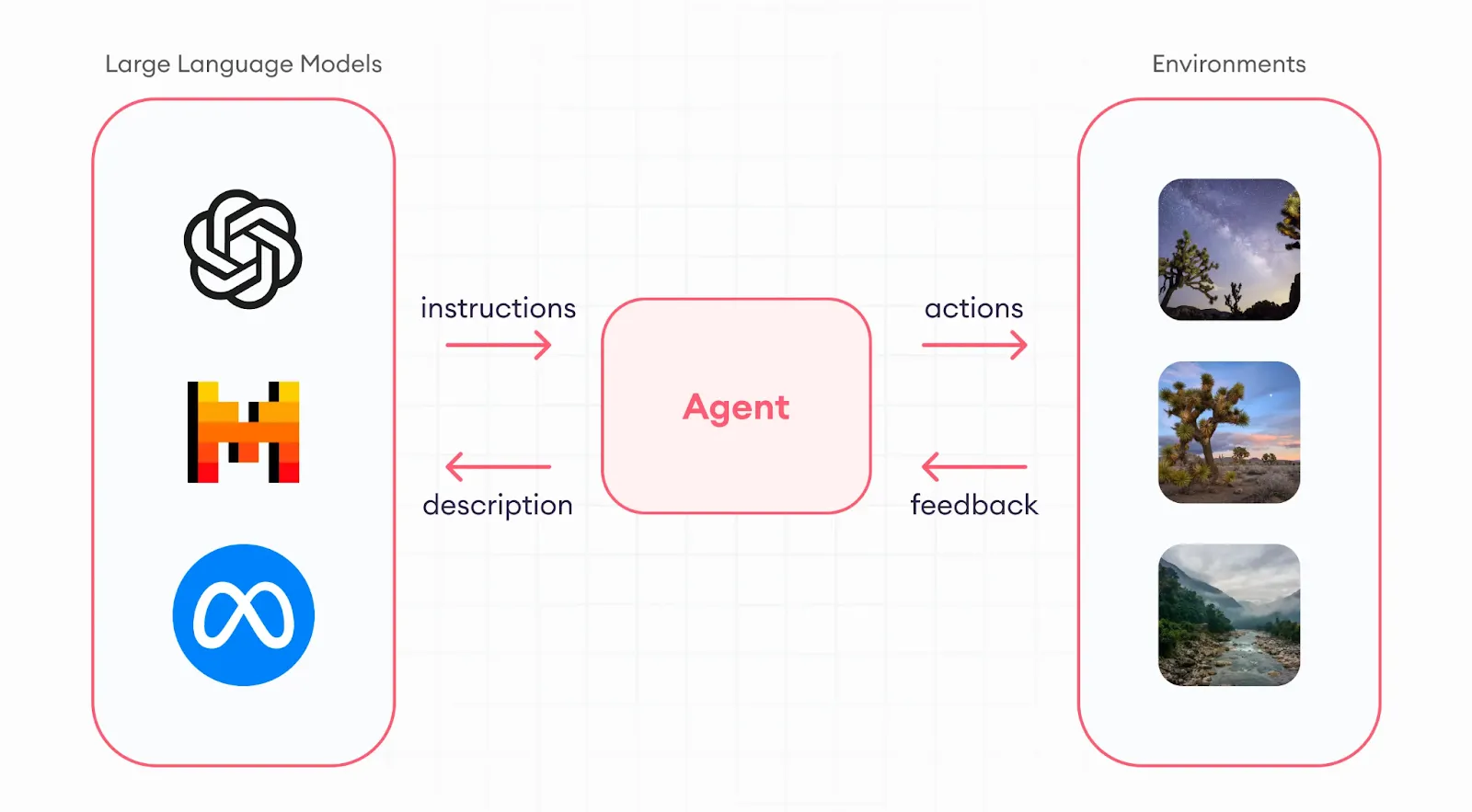
LLM agents are intelligent systems built on top of Large Language Models, designed not just to respond to prompts—but to take action. They can plan, reason, use tools, maintain memory, and operate autonomously to complete multi-step tasks. In simple terms, they transform passive LLMs into goal-oriented AI entities.
While a standard LLM like GPT-4 or Claude responds to a single prompt in isolation, an LLM agent has an objective and a looping process: it evaluates the task, decides what to do next, executes actions (like calling a tool or searching a database), observes the result, and continues until the goal is achieved.
This is possible because agents add multiple layers around the base language model:
LLM agents operate by layering structure, memory, and decision-making capabilities on top of a foundational Large Language Model. At a high level, an LLM agent follows a sense-think-act loop—observing its environment or inputs, reasoning about the next step, and executing actions toward a defined goal.
The workflow typically begins with a user query or task. Instead of responding immediately like a traditional LLM, the agent breaks down the task, determines if external tools are needed, decides what actions to take, and continues interacting with the environment until the objective is met. Each of these steps depends on repeated LLM inferencing, where the model evaluates intermediate context before deciding the next action.
Key Steps in an LLM Agent’s Workflow:
Task Initialization
The agent receives input or is assigned a goal—such as “generate a competitor report” or “book a meeting based on email context.”
Planning
It uses the LLM to generate a plan, often by thinking through the steps in natural language or selecting from predefined options.
Tool Selection and Invocation
If tools are available—like search engines, APIs, code interpreters, or databases—the agent decides which one to use and forms structured calls to access them.
Observation and Feedback Loop
Once a tool returns a result, the agent evaluates the output. It decides whether the information is sufficient, if further action is needed, or if the task is complete.
Memory (Optional)
In more advanced setups, the agent maintains short-term or long-term memory to track previous interactions, store knowledge, or build user profiles.
Iteration Until Goal Completion
This loop continues—plan, act, observe—until the agent achieves its intended result or reaches a termination condition.
As LLM agents continue to evolve, they’re being designed in a variety of forms based on complexity, autonomy, and purpose. While all agents are built on the foundation of a large language model, the way they plan, interact with tools, and handle tasks varies significantly. Broadly, LLM agents can be grouped into several types:
Task-Specific Agents
These agents are built to perform well-defined, narrow tasks. They follow pre-set workflows or logic but still benefit from the flexibility of an LLM to handle edge cases or ambiguity. For example:
They are often used in production because they are easier to test, validate, and control.
Autonomous Agents
These agents operate with minimal human intervention and can decide how to approach a task. Given a broad objective like “research market trends and write a report,” the agent will plan the process, gather data, analyze it, and generate a report—all on its own.
Autonomous agents typically include memory, recursive loops, and even self-correction mechanisms. AutoGPT and BabyAGI are examples of open-source projects that demonstrate this kind of agent behavior.
Tool-Using Agents
This category includes agents that rely heavily on external tools, APIs, and environments to complete their objectives. They may not be fully autonomous, but they excel at calling functions, fetching data, or running scripts when needed.
These agents use strategies like ReAct (Reasoning + Acting) or OpenAI’s function calling to decide:
They’re ideal for enterprise scenarios where the agent needs to integrate with CRMs, databases, or internal APIs.
Multi-Agent Systems
Instead of one agent doing everything, multiple agents with specialized roles collaborate to achieve a complex task. For example, one agent could gather research, another could verify data, and a third could summarize insights. They communicate, pass context, and resolve conflicts when needed.
Frameworks like CrewAI and MetaGPT enable such multi-agent coordination.
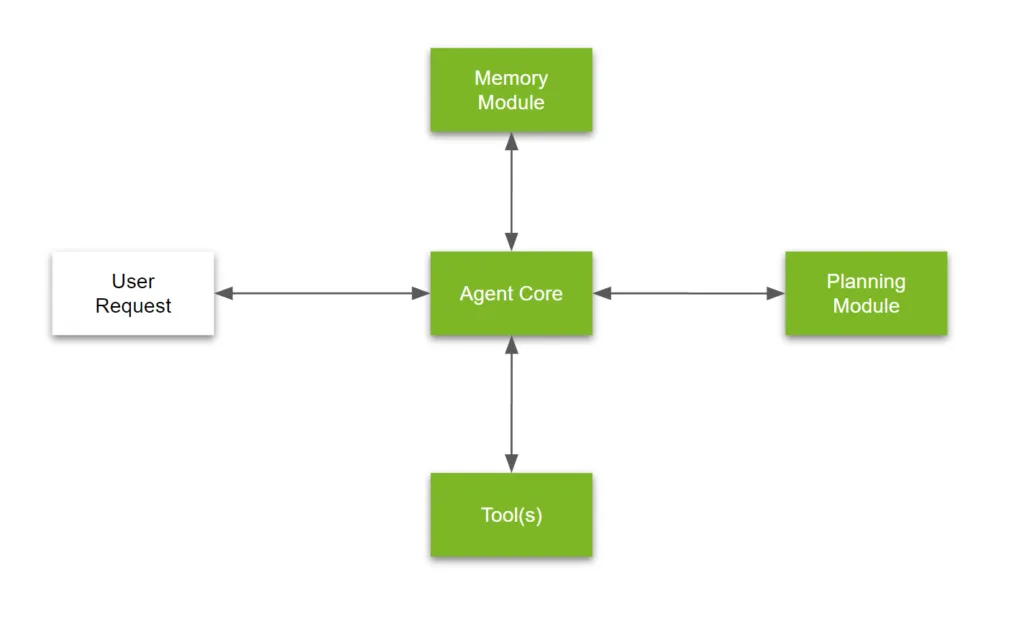
An LLM agent is not a single model or script—it’s a modular system designed to think, remember, interact, and act autonomously. This architecture is typically made up of four core components: the agent core, memory module, tools, and planning module. These parts work together to transform a raw language model into a capable, goal-driven agent.
1. Agent Core
At the center of the agent is the language model itself—often a foundation model like GPT-4, Claude, LLaMA 2, or Mistral. This component is responsible for understanding inputs, generating responses, and reasoning through tasks.
While powerful, the model on its own is reactive. It needs supporting logic to become proactive. The agent core acts as the “brain”, interpreting prompts and instructions, but it depends on the other modules to carry out actions, remember the context, and solve complex problems.
2. Memory Module
Memory allows the agent to retain information across steps, interactions, or sessions. This makes the agent more adaptive and personalized over time.
This module may be implemented using a vector database, a document store, or even structured key-value storage depending on the agent's needs.
3. Tools
The tools layer is what gives agents real-world utility. It allows the agent to go beyond language generation and actually take action.
Tools can include:
When the agent identifies a gap in its own knowledge or capabilities, it can call a tool, process the result, and continue with the task. This gives LLM agents a plugin-like extensibility that scales to enterprise use cases.
4. Planning Module
This is where the agent becomes goal-oriented. The planning module enables it to break down complex tasks, decide the order of operations, and loop through actions intelligently.
It handles:
Without planning, agents are just one-shot responders. With it, they can navigate uncertainty, iterate, and self-correct.
One of the most critical capabilities that separates LLM agents from standard language models is their ability to leverage tools. This allows agents to interact with the real world—fetching up-to-date information, performing calculations, accessing databases, or triggering actions. Without tools, agents are limited to their pre-trained knowledge and remain purely reactive. With tools, they become interactive, task-completing systems.
At a high level, tool usage in LLM agents follows a simple cycle:
Tool Abstraction and Invocation
Tools are typically exposed to the agent as function signatures or tool schemas. These can be custom-defined or registered via a framework like LangChain, OpenAI’s Function Calling, ReAct, or AgentOps. The agent doesn't execute code directly—instead, it generates a structured function call (like a JSON object), which is handled by an execution layer in the backend.
For example, consider a weather-checking tool:
{
"tool": "get_weather",
"inputs": {
"location": "New York City"
}
}
The agent determines that weather information is needed, constructs this tool invocation, and then the backend executes the function (an API call in this case). The result is fed back to the agent core, which continues reasoning.
When and Why Tools Are Used
LLM agents invoke tools when:
Tools are the agent’s bridge to external systems. They expand the agent’s capability from a “smart text generator” to an “action-taking assistant”.
Tool Use Strategy: ReAct and Planning
Most modern agents use the ReAct (Reason + Act) paradigm. The agent reasons about what to do next, chooses a tool, observes the output, and continues until the task is done. This tight loop allows for multi-step problem-solving, validation, and correction.
In more advanced systems, planning modules decide which tool to use at each step of a workflow—like a decision tree, dynamically built based on task context.
LLM agents represent a major leap forward in how AI can be applied across real-world tasks. By combining the reasoning power of large language models with memory, planning, and tool use, agents shift from being static assistants to autonomous collaborators. This architectural shift unlocks a range of tangible benefits across both technical and business domains.
Autonomy and Multi-Step Reasoning
Unlike traditional LLMs that respond to single prompts, agents can manage complex workflows by breaking down tasks, invoking tools, and iterating until the job is done. This autonomy makes them suitable for executing multi-step business processes—like analyzing a dataset, summarizing insights, generating a presentation, and emailing the results—all without human intervention.
Real-Time Interaction with Systems
Through tool integration, agents can fetch live data, interact with APIs, and even manipulate files or databases. This ability to access up-to-date information removes the limitations of static knowledge inherent in pre-trained models. For businesses, it means agents can interface with CRMs, analytics systems, calendars, and internal tools—making them operationally useful out of the box.
Context Awareness and Personalization
Memory modules give agents the ability to maintain context across interactions. This allows them to remember user preferences, track prior steps, and personalize output. Over time, agents can adapt their tone, content, and recommendations based on learned user behavior—offering a more human-like experience.
Scalability Across Use Cases
LLM agents are highly composable. The same agent core can be reused across departments (e.g., sales, marketing, finance) by changing the tools and planning logic around it. This modularity accelerates time-to-value and reduces redundant development effort.
Increased Efficiency and Cost Savings
By automating repetitive or analytical tasks, agents free up human bandwidth. Teams can focus on higher-value strategy and decision-making, while agents handle operational tasks—leading to measurable improvements in productivity and operational costs.
Here's The Evaluation Framework for Proposal Template
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Unified API & Routing | |||
| Unified OpenAI-compatible endpoint | Is the gateway API compatible with OpenAI's /v1/chat/completions and /v1/responses formats, allowing consistent access across different models through a standardized interface? | Must have | ✅ Supported: OpenAI-compatible endpoint across all providers. |
| Provider and model coverage | Does it support leading providers like OpenAI, Azure OpenAI, Amazon Bedrock, Anthropic, Gemini, Groq, plus self-hosted models? | Must have | ✅ Supported: 1000+ LLMs across hosted and self-hosted providers. |
| Model onboarding speed | How quickly can new models (OpenAI-compatible and non-standard APIs) be added without code changes? | Must have | ✅ Supported: config-driven onboarding within minutes. |
| Multimodal support | Does the gateway support text, vision, audio, image generation, and embeddings through a single interface? | Depends on use case | ✅ Supported: chat, embeddings, images, audio, rerank, and realtime APIs. |
| Routing, load balancing, fallback | Can requests be routed by model, provider, latency, priority, weight, region, and failure state with automatic retries? | Must have | ✅ Supported: load balancing, fallbacks, weighted and latency-based routing. |
| Model switching without code change | Is model switching supported via headers or config without changing client code? | Must have | ✅ Supported: header-based and config-based model switching. |

LLM agents are powerful systems, but their complexity introduces several engineering and operational challenges. From decision accuracy to system reliability, building robust, production-ready agents requires more than just plugging an LLM into a prompt loop. Below are some of the most common challenges—along with simple examples to illustrate their impact.
Hallucination and Decision Errors
LLMs can still generate confident, but incorrect or misleading information—a phenomenon known as hallucination. In an agent pipeline, this can cascade into faulty actions.
Tool Misuse and Invocation Failures
Agents must correctly call APIs or tools using structured inputs. However, generating the correct format or handling edge cases dynamically is error-prone.
Latency and Cost Overheads
Multi-step reasoning and tool chaining introduce high latency and model token costs, especially if large models are used for each step.
Memory Complexity
Managing what to remember, what to forget, and how to retrieve relevant memory efficiently is an ongoing challenge.
Security, Privacy, and Guardrails
Agents often touch sensitive systems and data. Without guardrails, they can expose internal logic or leak private data in responses.
Debugging and Observability
Agents are not deterministic. Without proper tooling, it's difficult to trace why an agent failed or how it made a decision.
LLM agents are no longer just theoretical concepts—they’re already being applied across industries to perform autonomous tasks, automate workflows, and interact with users intelligently. Let’s look at some practical examples that illustrate how LLM agents function in real environments.
AutoGPT & BabyAGI
These open-source projects demonstrated the idea of autonomous agents capable of executing tasks without human supervision. Given a high-level objective like “analyze competitors and generate a strategy,” AutoGPT will plan steps, search the web, write summaries, evaluate results, and adjust its plan iteratively. While these agents are still experimental and require guardrails, they sparked a major interest in autonomous task execution loops.
LangChain Agents
LangChain provides a framework to build agents using modular components like prompt templates, tool interfaces, memory, and planners. For example, an agent could answer complex queries over a collection of PDFs by retrieving relevant documents, summarizing content, and synthesizing an answer. LangChain makes it easy to create both task-specific agents and tool-using agents by defining workflows and integrating APIs, while understanding LangChain vs LangGraph helps teams decide when graph-based orchestration is better for multi-step agent execution.
OpenAI Function-Calling Agents
OpenAI's function calling enables structured, tool-using agents. Developers define tools as JSON schemas, and the model chooses when and how to invoke them. A practical use case is a customer service agent that, upon recognizing intent, automatically fetches order status, updates delivery info, or submits a support ticket—without manual API engineering.
CrewAI and MetaGPT
These frameworks introduce multi-agent collaboration, where agents are assigned specific roles—such as developer, reviewer, or strategist—and communicate with one another to solve complex tasks. For example, in MetaGPT, a project manager agent creates the requirements, a developer agent writes the code, and a tester agent validates it—effectively mirroring the workflow of a real software team.
Most LLM agents work great in a sandbox—but quickly fall apart in the wild. They hallucinate, fail on tool calls, struggle with latency, and offer little visibility when something breaks. Building a smart agent is easy. Making it reliable, scalable, and secure in production is the hard part.
That’s where TrueFoundry comes in. It offers an end-to-end LLMOps platform designed to transform promising prototypes into enterprise-grade agent systems that are fast, observable, compliant, and built to scale.
TrueFoundry allows teams to deploy agents built using LangChain, AutoGen, CrewAI, or custom architectures—without worrying about infrastructure complexity. Whether it's a single-agent use case or a multi-agent pipeline, TrueFoundry provides the orchestration backbone to manage workflows across cloud or on-prem environments.
To power real-time agent interactions, the platform offers optimized model serving using high-performance backends like vLLM and SGLang. Combined with autoscaling and intelligent resource provisioning, agents can respond faster while keeping inference costs in check.
Agents that call external tools or third-party APIs benefit from TrueFoundry’s unified API gateway. It provides:
LLM agents are reshaping how we interact with AI—from reactive chatbots to autonomous systems capable of reasoning, planning, and acting. Their architecture, powered by language models, tools, memory, and orchestration, is evolving rapidly to support more complex, real-world tasks. While the possibilities are vast, deploying agents in production requires more than clever prompts—it demands scalable infrastructure, observability, and careful system design.
Enterprises deploy LLM agents to automate complex, multi-step workflows that require dynamic decision-making. These systems use language models to reason through problems and execute actions using external tools. They provide autonomous execution capabilities that traditional, static chatbots cannot achieve in scalable production environments.
LLM agents often struggle with reasoning loops, tool errors, or data hallucinations when operating in unconstrained environments. These failures typically occur when the agent lacks clear instructions or encounters unexpected API responses. Implementing deep observability helps teams trace agent steps and fix these logical breakdowns to ensure production reliability.
The reliability of LLM agents depends on task complexity and the underlying model capabilities. While simple data retrieval is highly reliable, complex reasoning requires rigorous evaluation frameworks. Platform-level monitoring allows teams to measure these success rates and iterate on agent prompts systematically for better inference accuracy.
An LLM agent specifically refers to an autonomous system utilizing a large language model as its core reasoning engine. While "AI agent" is a broader category encompassing various algorithms, LLM-based versions excel at natural language comprehension and planning complex tasks. They transform text-based instructions into actionable steps across integrated software tools.
While many modern systems are LLM agents, some AI agents utilize traditional reinforcement learning or fixed rule-based logic. However, integrating LLMs allows agents to handle vastly more diverse and unstructured information. Enterprise platforms like TrueFoundry support hybrid architectures, giving teams the flexibility to choose the optimal intelligence for specific, high-stakes workflows.
MCP agents focus on connecting LLMs to external tools or data via the Model Context Protocol, acting as controlled intermediaries. LLM agents, on the other hand, operate autonomously, making decisions, executing tasks, or interacting with multiple tools without direct human instruction, leveraging reasoning and workflow orchestration.
Risks include generating inaccurate or biased outputs, leaking sensitive information, making autonomous decisions that violate policies, or misusing integrated tools. Without proper oversight, LLM agents can propagate errors, create legal liabilities, or compromise security, making governance, monitoring, and safety mechanisms essential in enterprise deployments.
When left unsupervised, LLM agents continue executing assigned tasks within their programmed constraints. They may iterate workflows, query connected tools, or refine outputs autonomously. However, without human oversight or guardrails, they can drift from intended objectives, generate inconsistent or unsafe results, and fail to detect context changes.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




