Get instant access to a live TrueFoundry environment. Deploy models, route LLM traffic, and explore the full platform — your sandbox is ready in seconds, no credit card required.
9.9
LLM Deployment in Regulated Industries: HIPAA, SOC2, and GDPR Playbook for 2026
The technical challenge of deploying a large language model in a regulated enterprise is not primarily a machine learning problem. The models exist, they work, and they are capable enough for serious clinical, financial, and insurance use cases. The challenge is the architecture around the model: who controls the data, where it flows, what gets logged, who approved the vendor, and how the compliance team can demonstrate all of that to a regulator.
Medtronic, with 90,000 employees and FDA-regulated device portfolios, runs AI in production. Innovaccer processes protected health information at scale inside a governed clinical intelligence platform. Aviva, operating under UK GDPR, uses AI across insurance workflows. Siemens Healthineers has AI deployed across multiple regulatory jurisdictions simultaneously. These are not proofs of concept. They are enterprise-scale production deployments that passed legal, compliance, and IT security review.
The architecture that made each of those deployments possible is the subject of this playbook. It covers the specific regulatory requirements for healthcare, financial services, and insurance, the technical decisions those requirements drive, and what a governed VPC-isolated deployment looks like in practice for teams preparing to go through the same approval process.
What Makes Regulated Industry AI Deployment Different
The differences between regulated and unregulated AI deployment are not primarily technical. The underlying models are the same. The difference is legal obligation, accountability structure, and audit burden, and those things change the architecture decisions from the ground up.
Data handling rules are set externally. In regulated environments, permissible uses of data are defined by statute, not by engineering judgment. An AI system that sends patient records to an external API can be technically elegant and simultaneously constitute a HIPAA violation. The technical sophistication of the implementation is irrelevant to the legal standard. What matters is where the data went and whether it was authorized to go there.
AI systems are now in scope for regulatory audit. Regulators in healthcare, financial services, and insurance increasingly expect organizations to document what data their AI systems accessed, what decisions those systems influenced, who authorized the deployment, and what the human oversight process looked like. The HIPAA security rule requires appropriate safeguards, including encryption at rest and in transit, based on risk assessment. The burden of demonstrating compliance lies with the organization at all times.
Your AI vendor is in your compliance scope. Any vendor that creates, receives, maintains, or transmits protected health information on your behalf is a Business Associate under HIPAA and legally requires a signed BAA before PHI touches their infrastructure. Most standard public LLM API offerings are not BAA-covered by default and require enterprise agreements or alternative deployment models. AWS Bedrock and Azure OpenAI Service offer BAA-eligible options with specific configuration requirements, but eligibility is not the same as compliance.
Data residency may eliminate SaaS options entirely. A European insurance company processing GDPR-covered personal data cannot legally route that data through US-based infrastructure without either a Standard Contractual Clause arrangement or another approved GDPR transfer mechanism. Many SaaS AI gateway products are US-based, which means EU-to-US data transfer documentation must be completed before any technical deployment begins. For some organizations and some data types, this eliminates the SaaS option entirely.
Audit trails are not optional, and structured ones are better. Every access to regulated data, including AI-assisted access, must generate an audit record. For HIPAA, that record must include timestamp, accessor identity, the action performed, and a reference to the PHI accessed. AI systems that generate these records automatically in structured JSON format are deployable. Systems that require manual log correlation after the fact create compliance gaps that regulators do not accept as equivalent.
Healthcare: HIPAA Requirements for LLM Deployments
HIPAA covers any system that handles Protected Health Information. An LLM deployment is in scope if the model can receive PHI in prompts, if PHI appears in retrieval-augmented generation context passed to the model, or if model outputs feed decisions about individual patients. Clinical note summarization, patient record analysis, diagnostic assistance tools, and prior authorization support all fall inside this boundary.
Three HIPAA rules shape LLM deployment architecture directly. The Privacy Rule governs what PHI can be used for and who can access it, including the minimum necessary standard that limits data exposure to what is required for the specific task. The Security Rule requires administrative, physical, and technical safeguards for electronic PHI, including access controls, audit logging, and transmission security. The Breach Notification Rule sets what happens when controls fail. All three have technical implementation requirements that show up in how the AI infrastructure is designed, not just in the policy documents.
PHI Isolation: Why Most Cloud LLM APIs Are Not Suitable for Clinical Use Cases
Standard consumer API offerings from OpenAI, Anthropic, and Google are generally not designed for HIPAA-regulated workloads and typically do not provide Business Associate Agreements (BAAs) for their public endpoints. When PHI is transmitted to a third-party service acting as a business associate without a BAA in place, this constitutes a HIPAA compliance violation. This is one of the most common failure modes in early enterprise AI deployments that move faster than their vendor governance processes.
AWS and Microsoft both provide HIPAA Business Associate Agreements that cover specific eligible services within their platforms. AWS includes eligible services under its standard BAA, while Microsoft provides coverage through its Online Services Data Protection Addendum. However, compliance depends on using only in-scope services and configuring them correctly. Encryption at rest and in transit, audit logging, and least-privilege IAM controls are required. Signing a BAA is a prerequisite, not the end state of compliance.
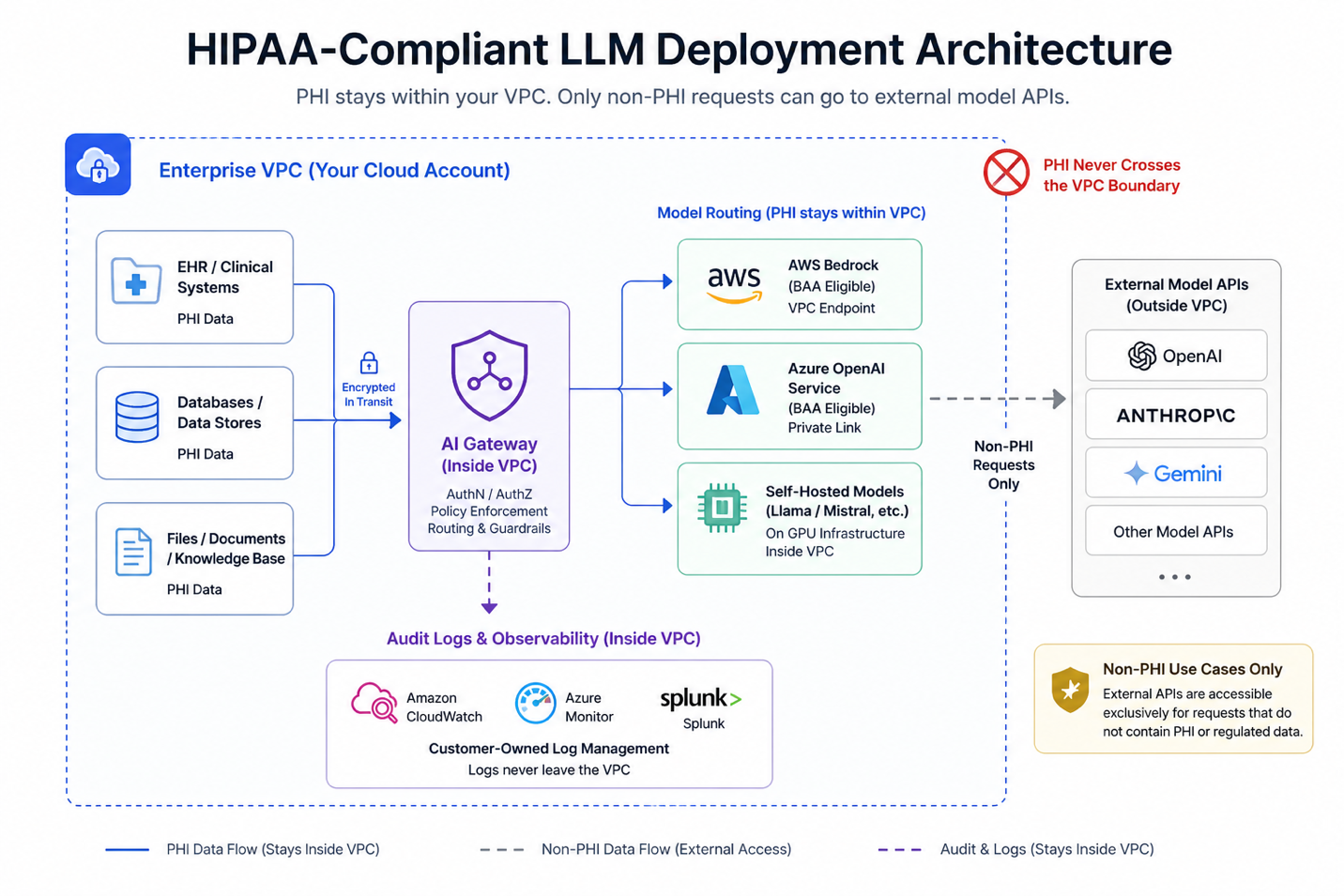
For clinical use cases involving PHI, VPC-isolated or self-hosted model deployment provides the cleanest architectural boundary. When models run inside the organization’s own cloud account, PHI remains within the enterprise perimeter and is not exposed to external model providers. This removes the need for a separate BAA with a third-party model API vendor, though a BAA with the underlying cloud provider (for example AWS or Azure) remains required as part of the overall compliance posture.
For organizations that must use external model APIs in limited scenarios, data masking or de-identification can be a viable pattern. Sensitive fields are removed or tokenized before the request is sent, and reconstructed only within the controlled environment after the response is returned. For this to be compliant, the transformation must ensure that no identifiable PHI is exposed to the external service, and the process must be documented, validated, and demonstrable to auditors as part of the organization’s compliance controls.
HIPAA Audit Log Requirements for AI Systems
The HIPAA Security Rule requires covered entities and business associates to implement audit controls that record and examine activity in systems handling electronic PHI. In practice, this means systems must generate logs that capture access events in a way that supports investigation and accountability. While the regulation does not prescribe exact fields, industry-standard implementations include timestamps, user or system identity, the action performed, and the data or system accessed. For LLM deployments, this extends to capturing which user or agent initiated a request, which model processed it, and sufficient context to reconstruct what occurred. Aggregate usage metrics alone are not sufficient to support audit or incident investigation.
HIPAA requires that documentation related to security controls, including audit records where applicable, be retained for a minimum of six years. In addition, systems must implement integrity controls to protect logs from unauthorized alteration or deletion. In practice, this is often achieved through tamper-evident storage mechanisms such as write-once-read-many (WORM) configurations, strict access controls, and centralized log management systems that prevent modification by operational teams.
HIPAA requires mechanisms to uniquely identify and authenticate users accessing systems containing ePHI. As a result, audit logs must be able to attribute access events to a specific individual or system identity. Implementations that rely solely on shared service accounts or API keys without user-level attribution create gaps in accountability and make it difficult to meet audit and investigation requirements. In modern AI systems, this typically requires integrating identity-aware access controls so that actions performed through agents or gateways can be traced back to the originating user.
Access Control Requirements
HIPAA requires that access to PHI be controlled through technical and administrative safeguards, including unique user identification, authentication, and role-based access controls. In addition, the Privacy Rule enforces the “minimum necessary” standard for the use and disclosure of PHI. In practice, this means access must be provisioned and managed through a documented process, with permissions aligned to the user’s role. For AI systems, this has two implications. First, access should be tied to individual identities through the organization’s identity provider, not shared API keys that cannot be attributed to specific users. Second, role-based controls must ensure that users can only access AI capabilities appropriate to their function, for example, separating billing workflows from clinical workflows with different PHI exposure.
The minimum necessary standard applies to how PHI is used within a system, not just to which user initiates access. In AI systems, this extends to the data included in model prompts and context. Passing full patient records when only a subset of structured fields is required may not align with the minimum necessary principle. While HIPAA does not explicitly define how this applies to AI prompts, organizations are expected to limit PHI exposure to what is required for the task. Enforcing this at the infrastructure layer, for example through an AI gateway that applies context-aware data policies based on user role and use case, is one approach to ensuring consistent adherence rather than relying on application-level implementation.
Financial Services: SOC2 and Regulatory Requirements for LLM Deployments
Financial services firms deploying LLMs face a layered regulatory environment. SOC2 Type II requirements apply to technology infrastructure. OCC, Federal Reserve, and FINRA guidance on AI and model risk applies to models used in financial decisions. And EU AI Act provisions for high-risk AI systems, enforceable for EU operations from August 2026, add another layer for international organizations. These frameworks overlap in ways that create specific architecture requirements for AI gateway and model deployment infrastructure.
SOC2 Type II Controls for AI Infrastructure
AI gateways and model deployment platforms that handle financial data are in scope for SOC2 Type II assessments when they touch data or systems covered by the audit. The relevant trust service criteria are CC6 (logical and physical access controls), CC7 (system operations monitoring), CC8 (change management), and CC9 (risk mitigation). Each criterion requires specific technical controls that must be present in or alongside the AI gateway.
The most common SOC2 finding in AI gateway deployments is inadequate access control at the API level: shared service accounts that cannot attribute access to individuals, API keys stored in source code, or AI platforms that do not support the fine-grained access controls required by CC6. Choosing a platform that integrates with the enterprise identity provider and enforces RBAC at the model and team level eliminates these findings before the audit period begins.
SOC2 Type II requires continuous evidence of control operation over the audit period, typically six to twelve months. This means audit logs must be generated continuously and retained throughout the period, not captured on demand when auditors request them. AI gateway platforms that produce structured, continuous logs from the first day of deployment are significantly easier to audit than systems where logging was added after the fact. The audit evidence must show that controls were operating consistently throughout the period, not just at the moment of audit.
Model Risk Management (SR 11-7) for LLMs
OCC and Federal Reserve guidance SR 11-7 on Model Risk Management applies to AI and LLM models used in credit decisions, risk assessment, and other regulatory-relevant processes. The guidance requires three things for each in-scope model: documentation of purpose, training data, and testing methodology; independent validation against defined performance standards; and ongoing monitoring with performance tracking and drift detection.
For LLMs in financial services, the SR 11-7 documentation burden extends to the infrastructure the model runs on. Which LLM is being used, by which teams, for which decisions, at what cost, at what latency, and with what observed output behavior, must all be documented and available for regulatory review. An AI gateway that captures this data automatically as part of its standard logging produces the model documentation evidence as a byproduct of normal operations. This reduces what would otherwise be a significant manual documentation effort for each model in scope.
Insurance: Data Residency and GDPR Requirements
Insurance companies operating across multiple jurisdictions face data residency and cross-border transfer restrictions that directly constrain AI architecture choices. GDPR, UK GDPR, and US state privacy laws all have provisions affecting where and how customer data can be processed, including whether it can be sent to an AI model API for inference.
GDPR data processing basis: AI systems processing personal data must have a documented lawful basis under GDPR Article 6. For most insurance AI use cases, the basis is either legitimate interest or contractual necessity. Both require that the processing be documented, proportionate to the purpose, and disclosed in the organization's privacy notice. AI systems processing personal data without a documented lawful basis create direct regulatory exposure under a framework where fines reach 4% of global annual turnover.
Cross-border transfer restrictions: Sending EU resident personal data to non-EU AI infrastructure requires either a Standard Contractual Clause arrangement or another approved GDPR transfer mechanism. Many AI SaaS providers are US-based. EU-to-US data transfer compliance documentation must be completed with legal involvement before the technical deployment begins. For some data types and some organizational risk tolerances, this requirement effectively requires a European or fully VPC-isolated deployment with no data crossing jurisdictional boundaries.
Records of processing under Article 30: GDPR requires organizations to maintain records of processing activities that cover AI systems, describing the processing purpose, data categories, international transfers if any, and security measures applied. AI gateway audit logs provide the raw data for these records, but must be configured to capture the required fields including data category, processing purpose, and transfer destination, in a format the compliance team can produce to a regulator on request.
Right of explanation for automated decisions: GDPR Article 22 restricts fully automated decisions that significantly affect individuals and grants individuals the right to a meaningful explanation of how the decision was made. Insurance AI systems that assist in underwriting or claims handling must be designed with human review capability and explanation generation built into the workflow, not added as an afterthought. The architecture decision about how AI recommendations flow to human decision-makers is a compliance decision, not just a product design choice.
The VPC-Isolated Architecture: What It Looks Like in Practice
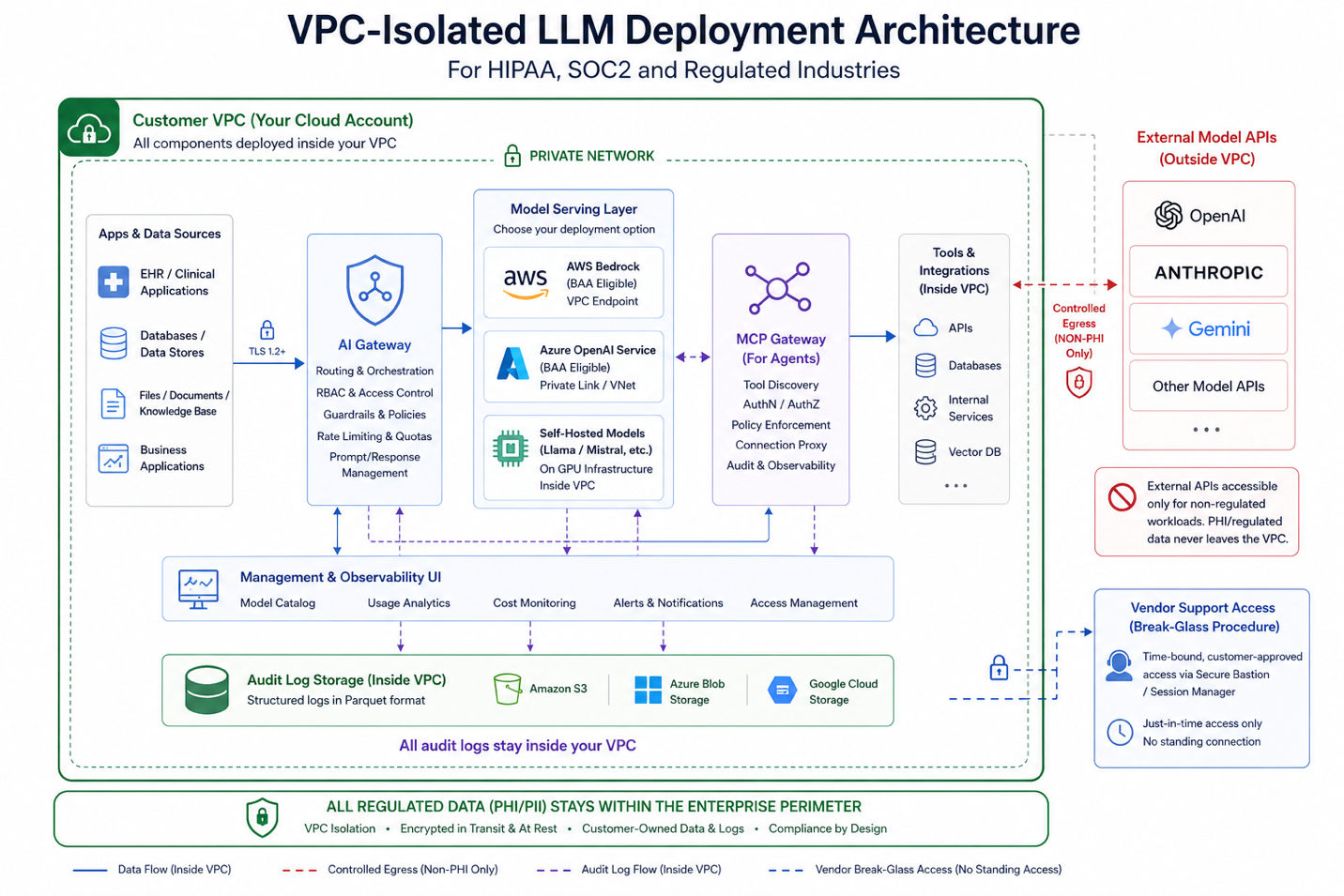
VPC-isolated LLM deployment is the architecture pattern that satisfies the broadest range of regulated industry requirements simultaneously. PHI isolation for HIPAA, data residency for GDPR, network security controls for SOC2, and operational accountability for financial services regulators all follow from a properly implemented VPC deployment. Understanding what this actually involves is what compliance, infrastructure, and security teams need before an approval conversation.
AI gateway inside the perimeter: The gateway runs as a containerized service within the organization's VPC. All LLM API calls route through this internal gateway. No application communicates directly with an external model provider. The gateway is the only component with egress capability to external APIs, and only when the deployed architecture permits external model access for specific use cases that do not involve regulated data. For fully isolated deployments, even that egress is absent.
Model serving inside the perimeter: For HIPAA and strict data residency requirements, the LLM itself runs inside the VPC. AWS Bedrock accessed within the same AWS account, Azure OpenAI Service within an Azure subscription with appropriate BAA coverage, or self-hosted open-source models on GPU infrastructure inside the cloud account all satisfy this requirement. In fully isolated deployments, no model inference data leaves the organization's cloud account boundary at any point in the request lifecycle.
Audit logs in customer-owned storage: All audit logs write to the organization's own logging infrastructure: CloudWatch, Azure Monitor, Splunk, or a customer-specified SIEM. Log data, which may itself contain regulated information, never transits to a vendor's SaaS logging service. Retention policies, access controls, and tamper-evident storage configuration are managed by the organization's compliance team without depending on a vendor's retention settings.
No vendor access to production traffic: In a properly implemented VPC-isolated deployment, production inference traffic, prompt content, and model responses remain within the customer’s cloud environment rather than being routed through vendor-managed infrastructure. This significantly reduces external visibility into sensitive data flows and aligns with data residency and privacy requirements. Support access, where required, is governed through controlled, time-bound “break-glass” procedures with explicit customer approval rather than persistent access. This architecture minimizes vendor exposure to regulated data in the production path, although the vendor relationship for platform software and support remains within the organization’s overall compliance scope.
How TrueFoundry Solves Regulated Industry LLM Deployment
TrueFoundry deploys entirely within the customer's cloud account on AWS, Azure, or GCP. No production data, including prompt content, model responses, MCP tool invocation parameters, or audit log data, leaves the enterprise perimeter to reach TrueFoundry's infrastructure. This is not a deployment option. It is the default architecture for enterprise deployments, not a premium tier.
VPC-isolated deployment by default: TrueFoundry deploys into the customer's own cloud account using infrastructure-as-code. The AI gateway, MCP gateway, management UI, and audit log storage all run within the customer's perimeter. Four deployment options cover the full spectrum from fully managed SaaS at no infrastructure cost to full Control Plane plus Gateway Plane inside the customer's account at approximately $800 to $1,000 per month in infrastructure cost. For regulated workloads, Options 3 and 4 ensure that no data transits TrueFoundry's infrastructure. TrueFoundry support access uses documented break-glass procedures with customer approval.
Structured audit logs aligned to HIPAA, SOC2, and GDPR: Every LLM call generates a structured JSON audit log entry via the X-TFY-LOGGING-CONFIG header. At the gateway level, REQUEST_LOGGING_MODE: ALWAYS on self-hosted deployments ensures every request is captured without configuration drift. Log fields cover user identity, model, token counts, latency, cost, policy decision, and output. Logs export via OpenTelemetry to Grafana, Datadog, Splunk, or any OTLP-compatible SIEM. On self-hosted deployments, log data writes to the customer's own AWS S3, GCS, or Azure Blob storage in Parquet format with configurable retention. S3 Object Lock in WORM mode satisfies HIPAA's tamper-evident retention requirement for the six-year minimum.
SSO integration with clinical and enterprise identity systems: TrueFoundry integrates with Okta, Azure Active Directory, PingFederate, and any SAML 2.0 or JWKS-compatible identity provider. Access provisioning follows the organization's standard identity lifecycle management process. Developers joining a team gain AI gateway access through the same IdP workflow that provisions their other systems. Developers leaving have access revoked through the same offboarding workflow. There is no separate AI gateway credentialing system to maintain or audit independently.
Approved model catalog for regulated workloads: Platform administrators define which models are approved for which data types and use cases. A clinical team cannot route PHI-containing prompts to a non-BAA-eligible model because the gateway enforces model-to-use-case policies at the routing layer before the request leaves the perimeter. This policy enforcement happens at the AI gateway, not at the application layer, which means it applies consistently regardless of which application or agent initiates the request.
Verified production deployments in regulated industries: Medtronic, with FDA-regulated medical device portfolios, runs TrueFoundry in production. Siemens Healthineers uses it across global medical technology operations with multi-jurisdiction regulatory exposure. Innovaccer processes approximately 17 million clinical AI inference requests per month inside AWS GovCloud under HIPAA with no data leaving their cloud boundary, using TrueFoundry's gateway with OpenTelemetry feeding Grafana dashboards. Aviva runs TrueFoundry for UK insurance operations under GDPR. ResMed uses it for digital health applications. These are production deployments at enterprise scale with regulatory compliance sign-off, not pilots.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.
Does TrueFoundry sign a HIPAA Business Associate Agreement for enterprise deployments?
TrueFoundry’s VPC-isolated deployment model is designed to reduce how much PHI ever interacts with vendor-managed infrastructure. In deployment configurations where both the control plane and gateway components run entirely inside the customer’s own cloud account, production prompts, model responses, and audit logs remain inside the customer’s environment rather than passing through systems operated by TrueFoundry.
The requirement for a Business Associate Agreement depends on whether PHI is created, received, maintained, or transmitted by a third party on behalf of the covered entity. In practice, that determination comes down to the actual data flow and the role TrueFoundry plays in the deployment. Organizations should evaluate BAA scope with TrueFoundry’s enterprise team based on their architecture, their compliance posture, and how PHI moves through the system.
Can TrueFoundry's VPC deployment be certified for HIPAA without routing any PHI through TrueFoundry infrastructure?
Yes. In VPC-isolated deployments where the gateway and control components are hosted inside the customer’s own AWS, Azure, or GCP account, PHI can be processed entirely within the enterprise boundary. The model inference request, the response, and the audit log of that interaction all remain inside the customer’s cloud environment rather than traversing external vendor infrastructure.
That said, HIPAA compliance is not determined by architecture alone. It depends on the full system configuration: identity controls, access policies, audit logging, and the use of HIPAA-eligible services across the data path. Even in a VPC deployment, organizations must assess whether any vendor participates in handling PHI as part of the workflow, because that is what ultimately defines whether a Business Associate relationship exists.
What LLM providers are available for VPC-isolated deployment that do not require sending data to an external API?
Three viable approaches exist for fully VPC-isolated inference. AWS Bedrock, accessed within the same AWS account, keeps inference within AWS-managed infrastructure inside the customer’s account boundary when properly configured. Models available include Claude Sonnet, Llama variants, Mistral models, and others, with the specific catalog depending on the AWS region. Azure OpenAI Service, accessed within an Azure subscription covered by Microsoft's BAA, provides GPT-4 and other models within the Azure boundary. Self-hosted open-source models including Llama 3, Mistral, and their derivatives can be deployed on GPU infrastructure inside the customer's cloud account and served through TrueFoundry's model deployment layer, with the gateway routing requests to the internal endpoint.
TrueFoundry's Virtual Models configuration allows platform administrators to create named model endpoints that route to any of these options, so applications call a stable internal endpoint and the underlying model can be changed or upgraded without application code changes.
How does TrueFoundry handle audit log retention to meet HIPAA's 6-year retention requirement?
On self-hosted deployments (Options 3 and 4), audit logs write to the customer's own AWS S3, GCS, or Azure Blob storage in Parquet format. The customer configures retention policy, access controls, and storage class directly in their cloud account. AWS S3 Object Lock in WORM (Write Once Read Many) mode provides tamper-evident storage that satisfies HIPAA's requirement for audit records that cannot be modified or deleted by the teams generating them. Retention periods are set by the customer's compliance team to the six-year HIPAA minimum or longer depending on organizational policy. Log format, retention configuration, and access controls are documented for audit evidence production without involving TrueFoundry support.
Can TrueFoundry be configured to prevent specific teams from routing certain data types to external model providers?
Yes, through two complementary controls. At the routing layer, Virtual Models and model catalog configuration define which model endpoints are available to which teams and users. A clinical team's model catalog can be restricted to VPC-hosted models only, with no external provider endpoints visible or accessible. At the guardrail layer, TrueFoundry's LLM Input guardrails can detect and block PHI or other regulated data types in prompts before they reach any model, with PII Detection and custom Regex Pattern Matching available to flag sensitive content. When an input guardrail triggers, the request is blocked before reaching the model. The guardrail result is logged with the detection reason for audit evidence. Both controls operate at the AI gateway layer and apply consistently across all applications using the platform.
What documentation does TrueFoundry provide for SOC2 Type II audits covering the AI gateway infrastructure?
TrueFoundry holds SOC2 Type II certification. For customer audits, TrueFoundry can provide its SOC2 Type II report for auditors reviewing the platform as part of the customer's vendor risk assessment. For the AI gateway infrastructure itself, the audit evidence is primarily generated from the customer's own TrueFoundry deployment: structured audit logs showing continuous operation of access controls throughout the audit period, RBAC configuration documentation, IdP integration records showing identity lifecycle management, and guardrail configuration and execution logs. TrueFoundry's solutions team can work with customers' audit preparation processes to identify which log fields and configuration exports are needed for each SOC2 trust service criterion under review.



























.webp)

.webp)


.webp)
.png)
.webp)
.webp)



.webp)



