


As machine learning adoption continues to accelerate across industries, the need for robust, scalable, and automated ML pipelines has never been greater. In 2025, MLOps platforms have become foundational to operationalizing AI—from model training and deployment to monitoring and governance. These platforms streamline the end-to-end lifecycle, helping teams manage complexity, ensure reproducibility, and accelerate time-to-value. Whether you’re a startup scaling your first model or an enterprise deploying hundreds, choosing the right MLOps platform is critical. In this guide, we explore what MLOps is, why it matters, and the top MLOps platforms shaping the landscape in 2025.
What is MLOps?

MLOps (Machine Learning Operations) is a discipline that merges the principles of machine learning, DevOps, and data engineering to enable the development, deployment, monitoring, and maintenance of reliable ML systems at scale. It ensures that models built in experimental environments can be safely and efficiently transitioned into production—where they must perform consistently, adapt to change, and remain accountable.
Traditional DevOps workflows focus on version control, CI/CD pipelines, automated testing, and system reliability. MLOps inherits these, but extends them to tackle the unique challenges of machine learning: managing constantly evolving data, retraining models to account for drift, evaluating non-deterministic results, and maintaining reproducibility across model iterations.
Why Do you Need MLOps Platforms?
As machine learning moves from experimentation to enterprise-scale deployment, MLOps platforms have become essential for ensuring consistency, reliability, and speed across the model lifecycle. Without a centralized MLOps solution, teams often end up with fragmented tools, manual processes, and inconsistent workflows that slow down innovation and introduce operational risk.
MLOps platforms solve these challenges by providing a unified interface to manage data pipelines, training workflows, model tracking, deployment, and monitoring—all in one place. This consolidation enables tighter collaboration between data scientists, ML engineers, and DevOps teams, reducing handoff friction and improving reproducibility across environments.
How to Choose Best MLOps Platforms?
When selecting an MLOps platform in 2025, it's important to evaluate not just features, but how well the platform supports your ML workflow, scales with your infrastructure, and aligns with your team’s operational goals. Below are some essential criteria to consider—each critical to building a robust and sustainable ML system.
End-to-End Lifecycle Support
An ideal MLOps platform should cover the full machine learning lifecycle—from data versioning and training to deployment and monitoring. Fragmented toolchains can create inefficiencies and inconsistencies across teams. Platforms that unify these stages into a single workflow help improve reproducibility, reduce handoffs, and accelerate iteration.
Scalability and Infrastructure Flexibility
As ML workloads scale, so must the platform. A good MLOps solution should support everything from local experimentation to distributed training across multiple GPUs or nodes. It should also offer flexibility in deployment—supporting cloud-native, on-premise, and hybrid environments without locking you into a specific stack.
Ease of Use and Developer Experience
Usability is often overlooked but critical. A strong platform offers clean interfaces—both UI and CLI—along with comprehensive SDKs that integrate with popular frameworks like PyTorch, TensorFlow, and Hugging Face. A platform that’s intuitive for both data scientists and ML engineers promotes better collaboration and faster onboarding.
Integration Ecosystem
MLOps doesn’t exist in isolation. Your platform should integrate seamlessly with existing systems for storage (like S3 or GCS), CI/CD tools (like GitHub Actions or Jenkins), observability platforms (like Prometheus or Grafana), and model registries. Strong integration ensures smooth data and model flow across your pipeline.
Governance, Security, and Compliance
For organizations working in regulated environments, governance features are a must. The platform should support role-based access control (RBAC), audit logs, and lineage tracking. Compliance with standards like SOC 2, HIPAA, or GDPR helps ensure data privacy, trust, and long-term viability in enterprise settings.
Best MLOps Platforms of 2025 ( Reviewed )
The MLOps landscape in 2025 is rich with platforms catering to different needs—from lightweight experiment tracking to enterprise-grade model deployment and monitoring. Below are the 10 leading MLOps platforms helping teams streamline their ML workflows, optimize infrastructure, and operationalize models at scale. Each platform has its strengths depending on your tech stack, team maturity, and business goals.
1. TrueFoundry

TrueFoundry is a modern MLOps and LLMOps platform built for teams that want to deploy, scale, and monitor machine learning and generative AI models in production. It abstracts away infrastructure complexity while offering complete control, allowing teams to move from experimentation to deployment in minutes. Unlike legacy systems, TrueFoundry is optimized for performance, developer productivity, and GenAI-first workflows—including support for agents, RAG pipelines, and advanced tracing. Its enterprise-grade security and modular design make it suitable for organizations of all sizes.
Key Features:
- Production-grade model serving with support for vLLM, SGLang, and autoscaling for high-throughput, low-latency inference.
- Integrated fine-tuning, tracing, and RAG orchestration, including LoRA/QLoRA, vector DBs, prompt management, and agent frameworks like LangChain and CrewAI.
- Enterprise readiness with SOC 2, HIPAA, GDPR compliance, unified API gateway, role-based access control, and audit logs.
Best For:
AI-driven teams building LLM-backed products, especially where performance, security, and observability are critical. Excellent fit for fast-moving teams or enterprises needing scalable GenAI deployment.
2. Kubeflow

Kubeflow is a Kubernetes-native, open-source MLOps toolkit for building and managing portable, composable ML workflows. It provides the flexibility to orchestrate training, tuning, and serving using familiar Kubernetes abstractions. Though powerful, Kubeflow requires deep infrastructure knowledge and isn’t ideal for teams without dedicated DevOps support. It shines when customized, scalable, and secure ML pipelines are a necessity.
Key Features:
- Modular, cloud-agnostic ML pipelines built on Kubeflow Pipelines with DAG orchestration, notebook support, and multi-step workflows.
- Native Kubernetes integration for managing compute resources, scaling jobs, and deploying models using KFServing.
- Secure multi-user environments with namespace isolation, RBAC, and compatibility across AWS, GCP, Azure, and on-prem clusters.
Best For:
Teams with strong Kubernetes expertise looking to fully customize and control their MLOps workflows—especially in regulated or hybrid cloud environments.
3. MLflow

MLflow is a lightweight, open-source MLOps platform created by Databricks, focused on managing ML experimentation and model versioning. Its modular components let teams integrate tracking, registry, and deployment into their existing workflows. MLflow is ideal for smaller teams or organizations that want flexibility without the overhead of full-scale infrastructure or Kubernetes.
Key Features:
- Experiment tracking and model registry with seamless logging of parameters, metrics, and artifacts across runs.
- Framework-agnostic and extensible, supporting TensorFlow, PyTorch, Scikit-learn, and custom ML workflows with REST and CLI integration.
- Deployment-ready with support for Docker, cloud environments, and custom serving tools for production integration.
Best For:
ML teams seeking lightweight, customizable tooling for tracking experiments, sharing models, and managing versions without relying on a large-scale platform.
4. Azure Machine Learning

Azure Machine Learning is Microsoft’s fully managed MLOps platform designed for building, training, deploying, and monitoring machine learning models at enterprise scale. It integrates tightly with the Azure ecosystem, offering a powerful suite of tools for model management, AutoML, and responsible AI. Azure ML is ideal for organizations already invested in Microsoft’s cloud and looking for security, scalability, and compliance.
Key Features:
- End-to-end ML lifecycle support, including data labeling, automated training, hyperparameter tuning, model registry, and deployment pipelines.
- Deep Azure integration, enabling seamless use of Azure Blob Storage, Azure DevOps, Azure Kubernetes Service (AKS), and Azure Synapse.
- Built-in governance and compliance features like lineage tracking, role-based access, model explainability, and support for responsible AI.
Best For:
Enterprises operating on Microsoft Azure need a highly secure, scalable, and fully integrated MLOps platform with enterprise compliance baked in.
5. Google Vertex AI

Vertex AI is Google Cloud’s unified platform for ML development, combining AutoML and custom model training under one interface. It abstracts infrastructure while offering advanced services like feature stores, pipelines, and experiment tracking. Built for scalability and integration with Google’s ecosystem, Vertex AI is optimized for production-level ML deployment and data-driven workflows.
Key Features:
- Unified MLOps platform combining AutoML, custom training, managed notebooks, pipelines, and feature stores in one place.
- Native GCP ecosystem integration, including BigQuery, Dataflow, and Kubernetes Engine for data and compute orchestration.
- Built-in model monitoring with support for drift detection, explainability, and Vertex AI Model Registry for lifecycle management.
Best For:
Teams building and scaling machine learning on Google Cloud who want a managed, scalable MLOps platform with full data and deployment integration.
6. Amazon SageMaker

Amazon SageMaker is AWS’s flagship MLOps platform that offers everything from data preprocessing to real-time model deployment. Known for its broad functionality, SageMaker supports custom model development, AutoML, model hosting, and advanced monitoring tools. It’s tightly integrated with the AWS ecosystem, making it a go-to choice for cloud-native enterprises.
Key Features:
- Comprehensive ML services including training jobs, experiments, pipelines, AutoML (SageMaker Autopilot), and model registry.
- Tight AWS integration, leveraging S3, Lambda, CloudWatch, and IAM for data access, security, and automation.
- Advanced production tools such as model monitoring, debugger, Shadow Deployments, and multi-model endpoints.
Best For:
Organizations already using AWS for infrastructure who need a robust, scalable MLOps platform with deep integration and full lifecycle support.
7. DVC (Data Version Control)

DVC is an open-source tool that brings version control to machine learning projects by tracking datasets, models, and experiments—similar to how Git manages code. It doesn’t aim to be a full-stack MLOps platform, but instead focuses on reproducibility, collaboration, and model tracking through Git-compatible workflows. DVC integrates seamlessly into existing pipelines and gives ML practitioners more control over experiment management.
Key Features:
- Data and model versioning using Git-style commands, enabling reproducible pipelines and consistent checkpoints across teams.
- Experiment tracking and comparison with support for metrics, parameters, and results visualization, either locally or via DVC Studio.
- Remote storage integration for datasets and artifacts across S3, GCS, Azure, SSH, and local directories.
Best For:
Teams looking for lightweight, code-first MLOps capabilities centered around reproducibility, Git-based workflows, and experiment management—especially in research and iterative ML projects.
8. Weights & Biases
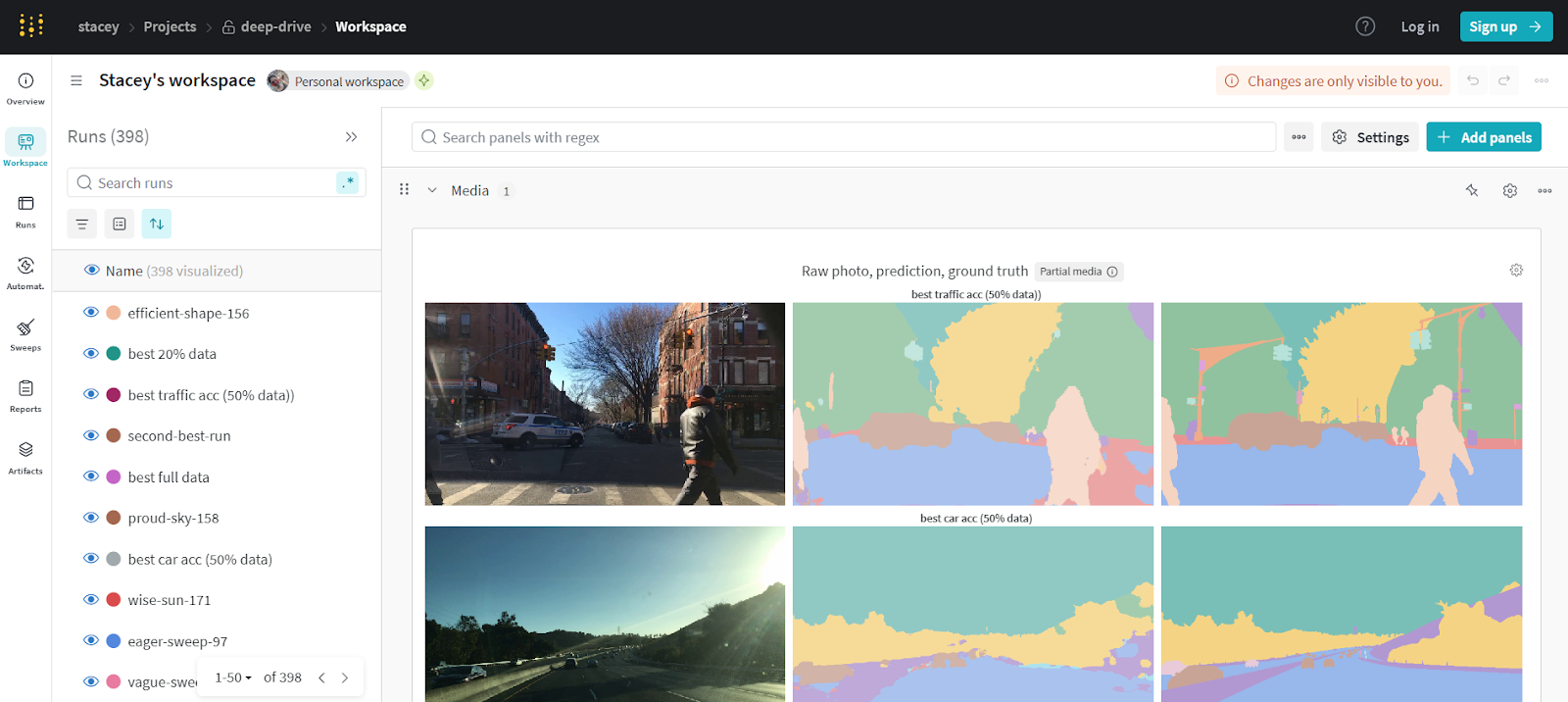
Weights & Biases (W&B) is a popular MLOps tool for experiment tracking, collaboration, and model visualization. It’s widely adopted in both research and production environments, offering simple integration with most ML frameworks. W&B focuses on observability, enabling real-time insight into training performance, hyperparameters, and system metrics.
Key Features:
- Experiment and model tracking, with live dashboarding for training runs, hyperparameter tuning, and performance visualization.
- Seamless integration with PyTorch, TensorFlow, JAX, Hugging Face, and others, with minimal code changes required.
- Collaboration tools including team dashboards, project reports, and artifacts versioning for centralized project visibility.
Best For:
ML teams focused on rapid iteration, visualization, and collaboration. Ideal for research-driven environments and teams that want better insight into training performance.
9. Pachyderm

Pachyderm is an open-source data science platform built for data lineage, version control, and reproducible pipelines. Unlike traditional MLOps tools, Pachyderm uses a Git-like approach for data, making it highly suitable for teams handling complex data dependencies or regulated environments. It combines containerization with data pipeline orchestration to ensure versioned, traceable workflows.
Key Features:
- Data versioning and lineage tracking to ensure full logs of datasets used in model training.
- Scalable, Docker-native pipelines that support parallel processing across large datasets with minimal configuration.
- Enterprise integrations and on-prem support, with compatibility for Kubernetes, cloud, and hybrid deployments.
Best For:
Teams in regulated industries or data-intensive workflows that need strong version control and lineage tracking for compliance, reproducibility, and scale.
10. Allegro AI

Allegro AI is an MLOps platform designed specifically for managing deep learning workflows at scale—particularly in computer vision and edge AI environments. It focuses on improving reproducibility, collaboration, and traceability across the AI lifecycle. With strong capabilities in dataset management, model versioning, and experiment tracking, Allegro AI offers a secure, end-to-end infrastructure for teams building and deploying high-performance models in production or regulated environments.
Key Features:
- Visual dataset and model management with automated versioning, annotations, and lineage tracking for deep learning projects.
- Experiment tracking and collaboration with project-based views, performance comparison, and real-time team dashboards.
- Edge AI support for deploying models to edge devices with reproducibility, rollback, and performance monitoring.
Best For:
Teams working on computer vision, deep learning, or edge deployment use cases—especially in industries like automotive, manufacturing, healthcare, or defense, where traceability and control over data and models are essential.
Conclusion
MLOps has evolved from a niche practice into a foundational component of modern machine learning workflows. In 2025, organizations are no longer asking whether they need MLOps—they’re asking which platform best aligns with their goals, infrastructure, and scale. As we've seen, the landscape offers everything from lightweight, modular tools like MLflow and DVC to fully managed enterprise solutions like Azure ML, Vertex AI, and SageMaker. For teams focused on GenAI, fine-tuning, and real-time inference, newer platforms like TrueFoundry offer cutting-edge capabilities built for modern AI challenges.



Management free AI infrastructure
Book a demo now
%20(1).png)
.png)











