



November 13, 2025
|
5 min read

We are excited to introduce that TrueFoundry has developed a powerful, yet easy to use, solution to Large Language Model (LLM) deployment and fine-tuning through our Model Catalouge. We aim to help companies self host their open source LLMs on top of Kuberenetes, thus making your inference costs 10x cheaper in 1 click. In this blog we show you how you can deploy a Dolly-v2-3b model and finetune a Pythia-70M model using TrueFoundry.TrueFoundry platform has been designed to support Machine Learning and Deep Learning models of all types, from the simplest ones like Logistic Regression to state-of-the-art models like Stable Diffusion. One may think, why does it need to build something new when it comes to Large Language Models?
The sheer size and complexity of these models pose significant challenges when it comes to deploying them in real-world applications. Though the TrueFoundry platform already supported deploying models of all sizes at scale, we realized that there are more optimizations (cost+time) and user experience improvements that we could do for these models.
Large language models (LLMs), like ChatGPT, have undeniably sparked considerable hype in the field of artificial intelligence.
But having talked to 50+ companies that are already starting to put it in production, the value that it is already creating is immense. We believe that the usage of LLMs is only going to expand as people discover new use cases every day.
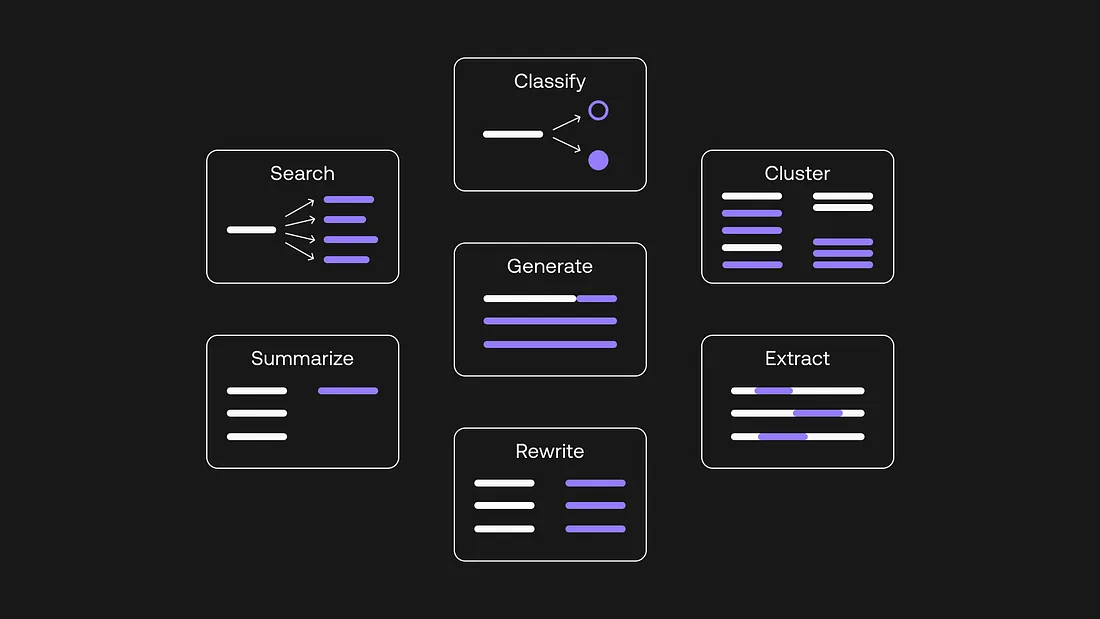
Creating a Proof of Concept use case with Large Language Models and OpenAI APIs is easy, but when you start thinking of production 🚀, a lot more considerations come into play.
For most companies, building the engineering capability to handle the complex GPU infra for serving LLMs reliably is difficult and time taking. Moreover, most companies want specific models that run best on their use case, for which they need to fine-tune these models. This can both be technically challenging and an expensive affair.
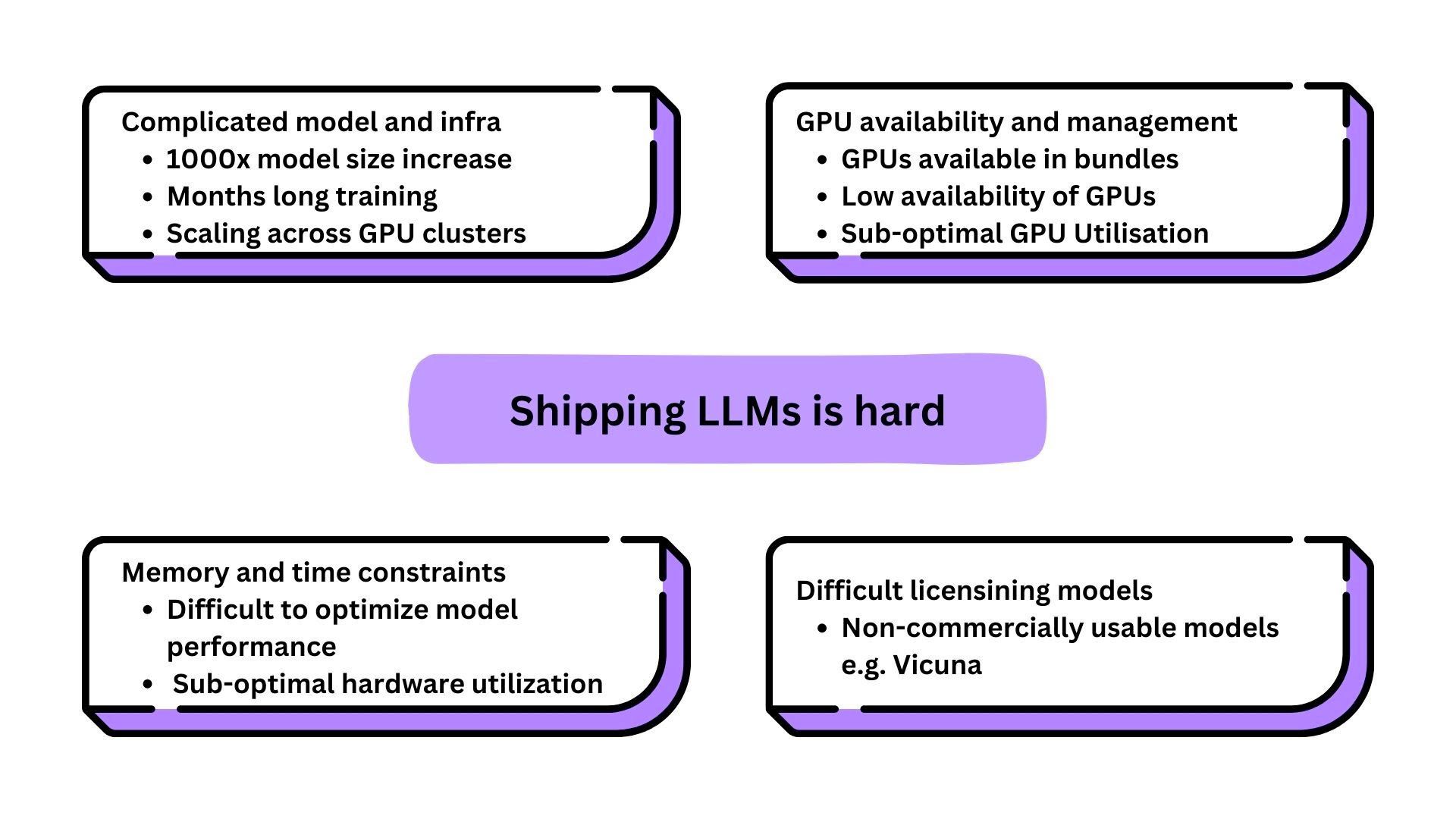
Our stance on the future of LLMs is that Open Source Models are going to be the way forward. Read more about our views on the topic here. We have decided to leverage this rapidly innovating community of innovators and help equip companies to utilize the complete value of these open-source LLMs in their organizations.
TrueFoundry wants that our partners can realize the full scale of advantages that Open-Source LLMs, fine-tuned for their specific use case, can have on their organizations:
However, managing and deploying Open Source on one's own self is not an easy feat.
But imagine if it was just as easy as plugging in your data and a few clicks?
We understand the challenges businesses face when transitioning LLM proof of concept to production. We aim to build the layer that makes this process super easy for our partners. Here's how we do it:
TrueFoundry's Model Catalogue is a repository of all the popular Open Source Large Language Models (LLMs) that can be deployed with a single click. The user can also fine-tune the model directly from the model catalogue.
The catalogue has most of the popular models already supported, and we are adding support for more every day. Some of the popular models that you could already deploy on your own cloud are:
And many more.....
We are obsessed that companies should be able to ship on day 1. To make this possible, here are the principles we are building our LLM capabilities on:
ℹ️
For a detailed walkthrough of the training and fine-tuning flows on the UI refer to this YouTube video
Deploying your LLMs is as easy as clicking three times!
🚀
Your model is now deployed!
Start Inference with the model API endpoint. TrueFoundry provides you with the OpenAPI interface to test your model and the sample code to call the model within your applications.
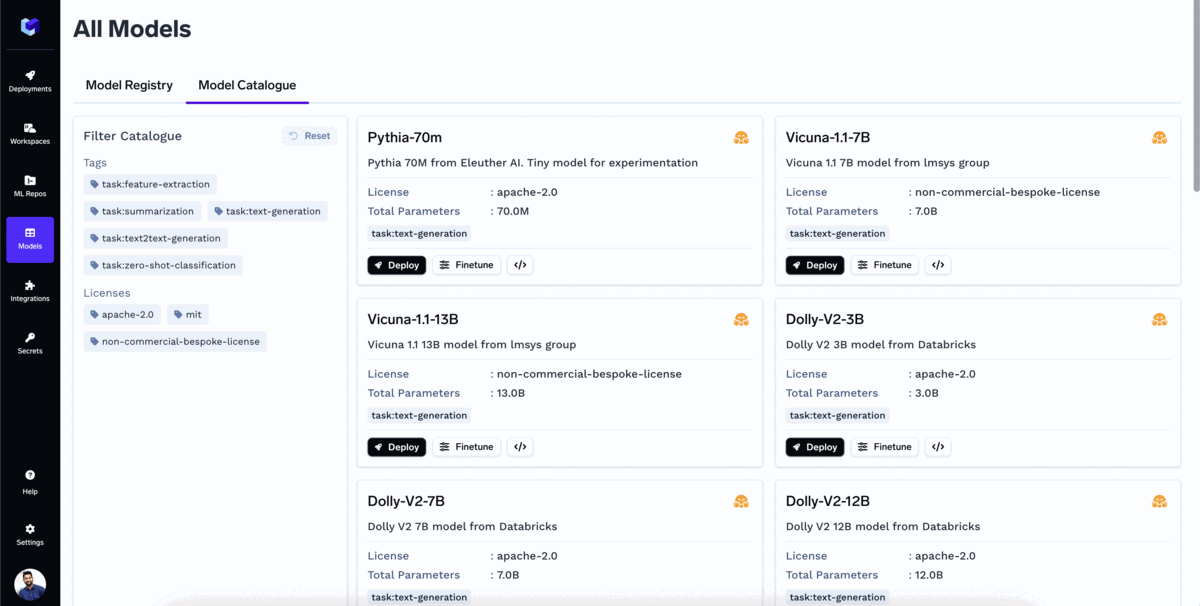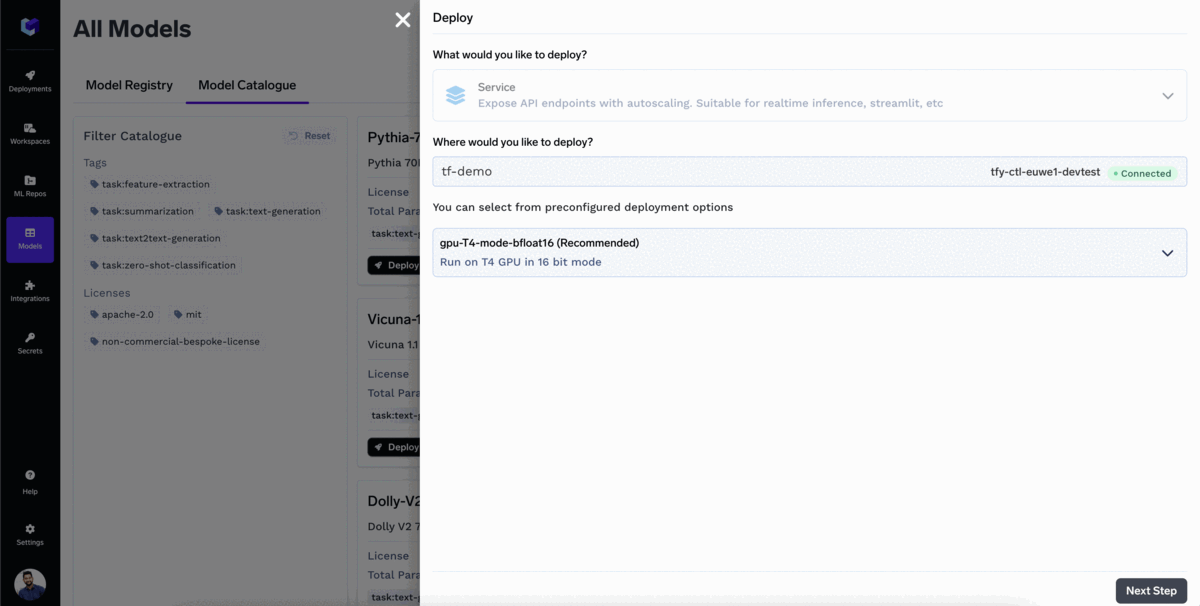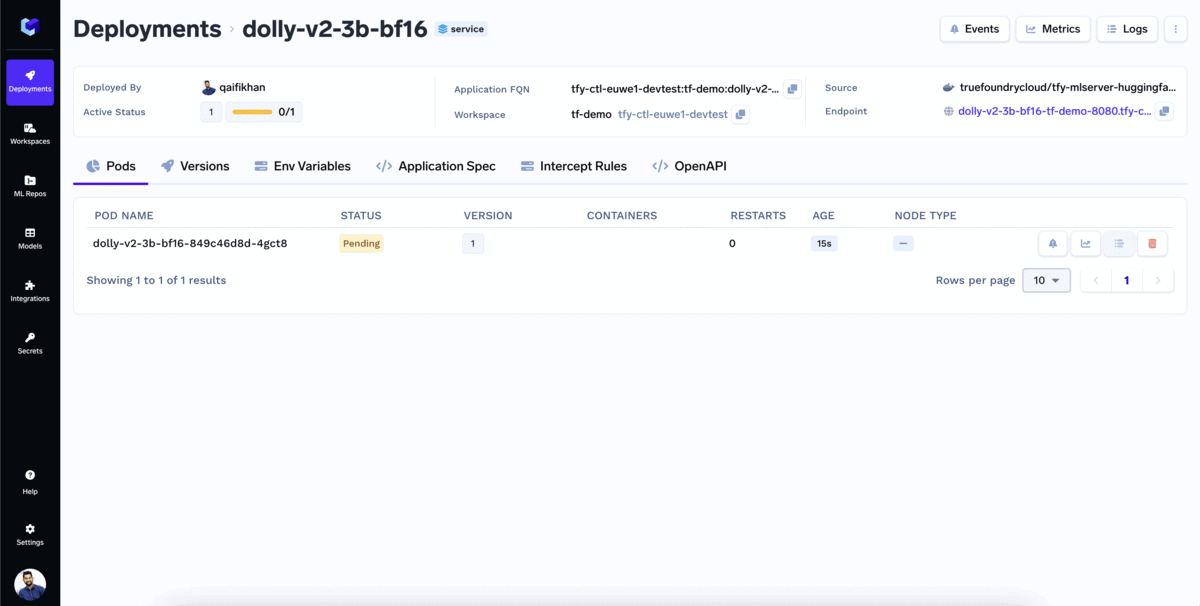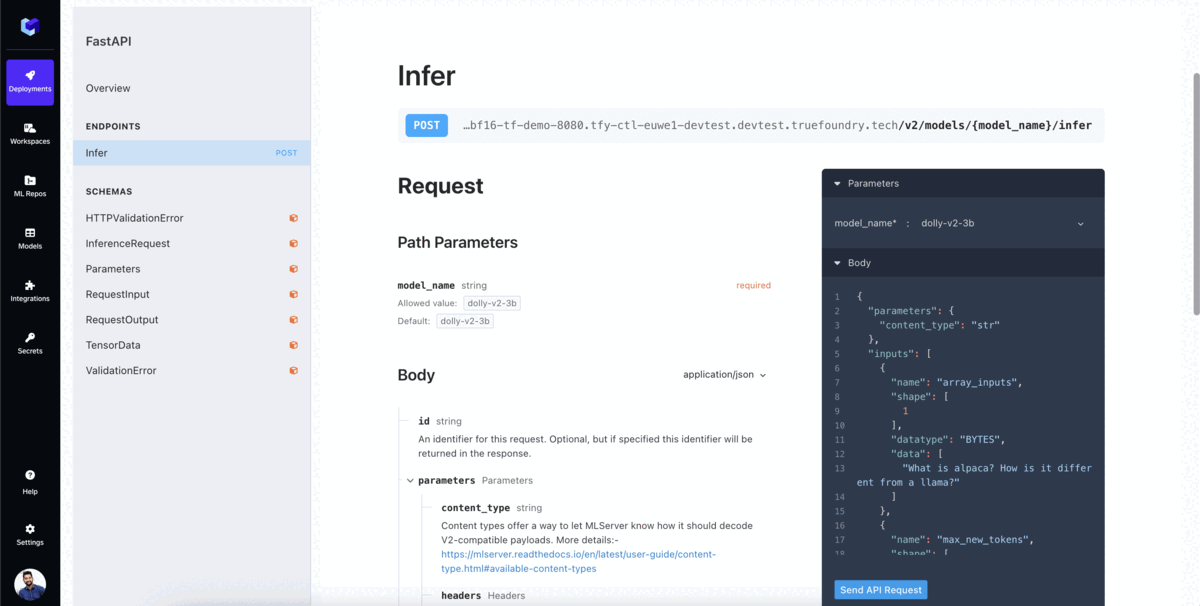
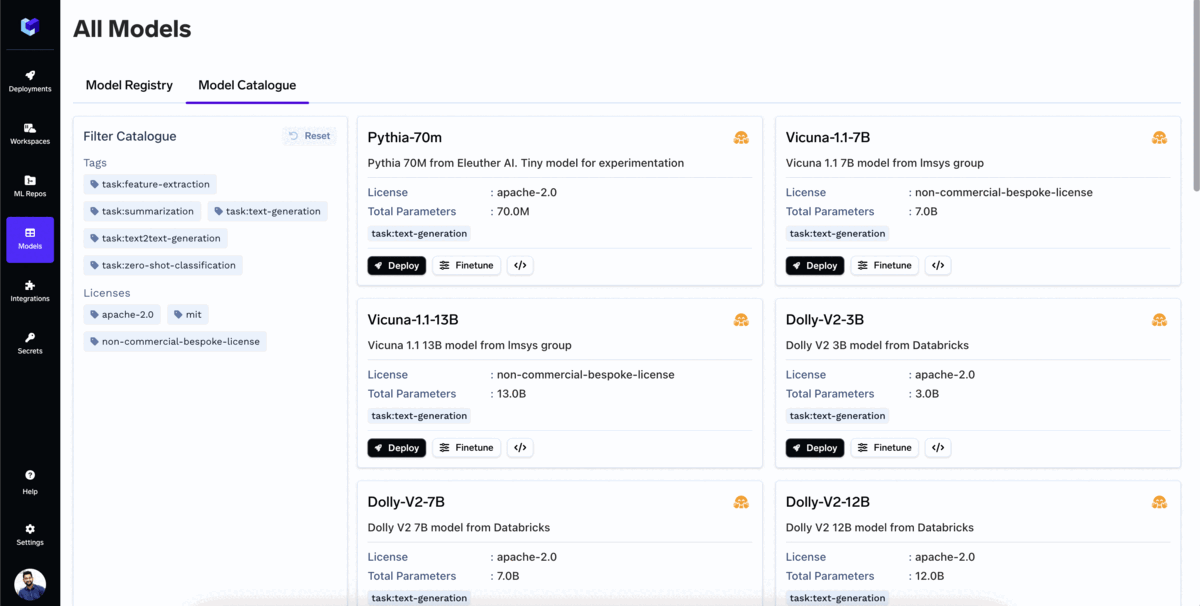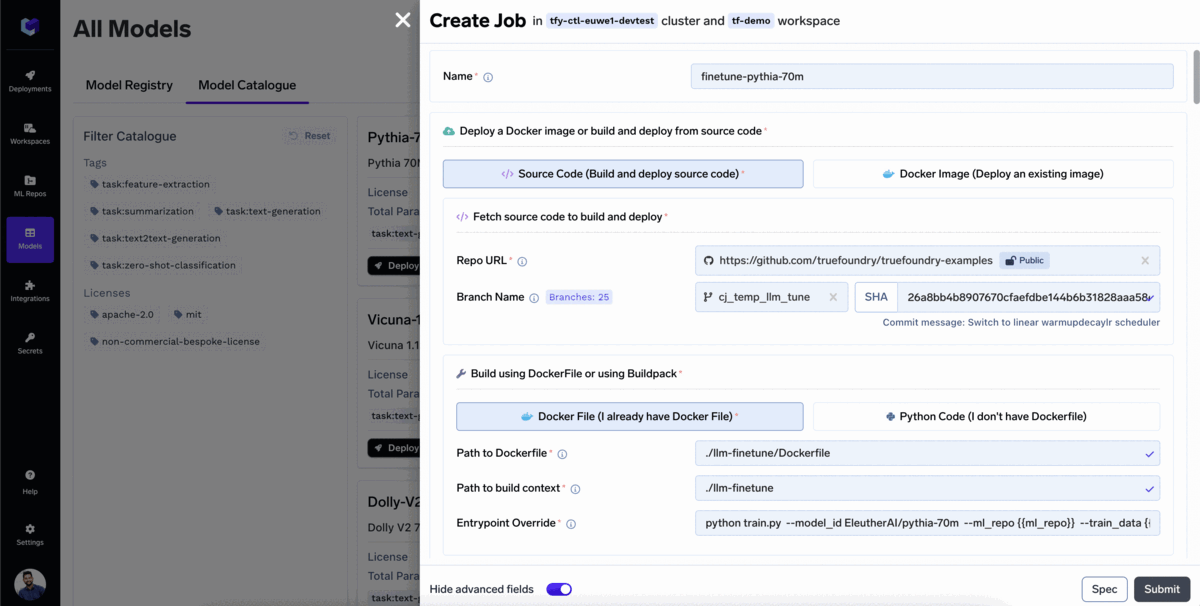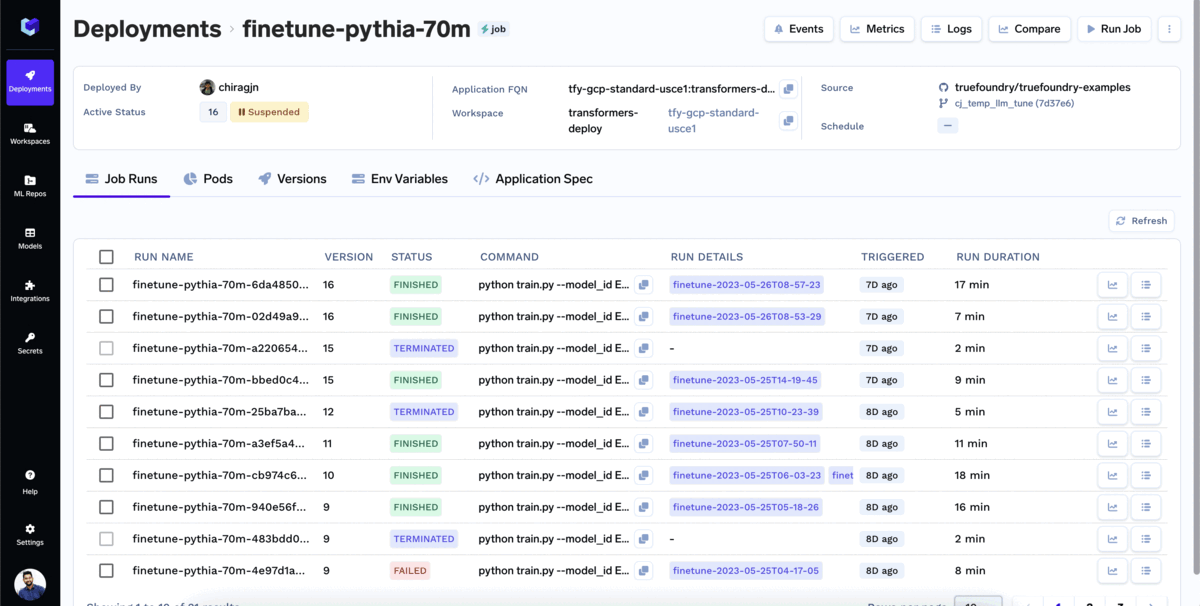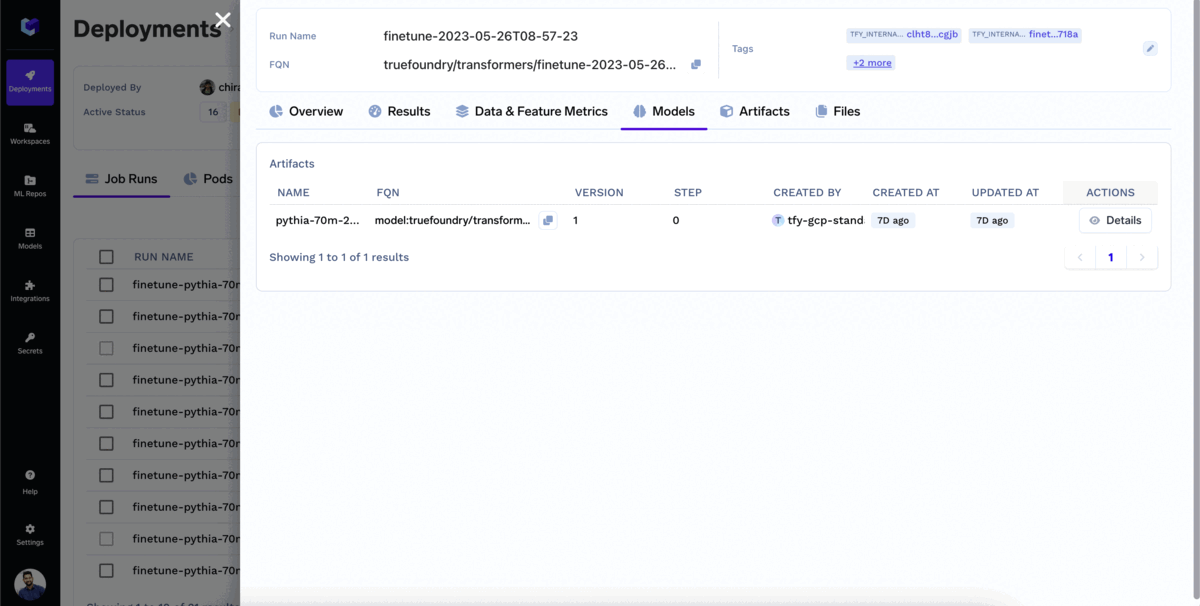
Most companies would want to use models fine-tuned for their specific use case. To fine-tune a model with TrueFoundry:
🚀
The model has started to fine-tune!
You can monitor the fine-tuning as it progresses. In the job runs tab, you can view all the relevant information associated with the training job, such as loss metrics, training curves, and evaluation results. This allows you to keep track of the finetuning process and make informed decisions based on the job's performance.
This is only the start of our journey with Large Language Models (LLMs) and Generative AI. We are planning to build much more in the days to come and would keep you guys posted!
We are still learning about this topic, as everyone else. In case you are trying to make use of Large Language Models in your organization, we would love to chat and exchange notes.
Blazingly fast way to build, track and deploy your models!
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.







The latest news, articles, and resources sent to your inbox
© 2025 All rights reserved.






.png)


