















November 13, 2025
|
5 min read

Published: May 9, 20255

Blazingly fast way to build, track and deploy your models!
We benchmark the performance of LLama2-70B in this article from latency, cost, and requests per second perspective. This will help us evaluate if it can be a good choice based on the business requirements. Please note that we don't cover the qualitative performance in this article - there are different methods to compare LLMs which can be found here.
In this blog, we have benchmarked the Llama-2-70B model from NousResearch. This is a pre-trained version of Llama-2 with 70 billion parameters.
Meta developed and publicly released the Llama 2 family of large language models (LLMs), a collection of pre-trained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters.
The key factors across which we benchmarked are:
GPU Type:
Prompt Length:
For benchmarking, we have used locust, an open-source load-testing tool. Locust works by creating users/workers to send requests in parallel. At the beginning of each test, we can set the Number of Users and Spawn Rate. Here the Number of Users signify the Maximum number of users that can spawn/run concurrently, whereas the Spawn Rate signifies how many users will be spawned per second.
In each benchmarking test for a deployment config, we started from 1 user and kept increasing the Number of Users gradually till we saw a steady increase in the RPS. During the test, we also plotted the response times (in ms) and total requests per second.
In each of the 2 deployment configurations, we have used the huggingface text-generation-inference model server having version=0.9.4. The following are the parameters passed to the text-generation-inference image for different model configurations:
We calculate the best latency based on sending only one request at a time. To increase throughput, we send requests parallelly to the LLM. The max throughput is the case when the model is able to process the input requests without significant deterioration in latency.
LLMs process input tokens and generation differently - hence we have calculated the input tokens and output tokens processing rate differently.

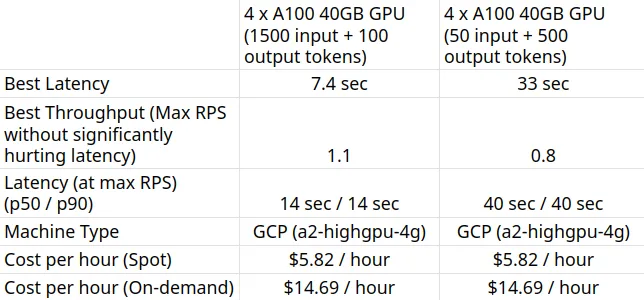
4 x A100 40GB GPU (1500 input + 100 output tokens)
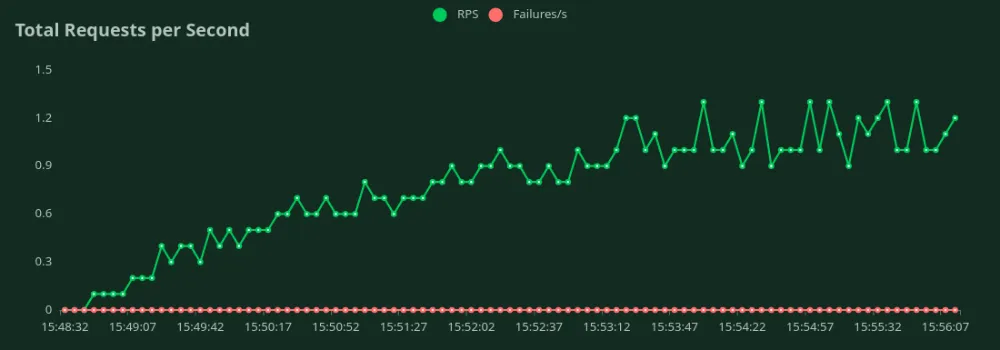
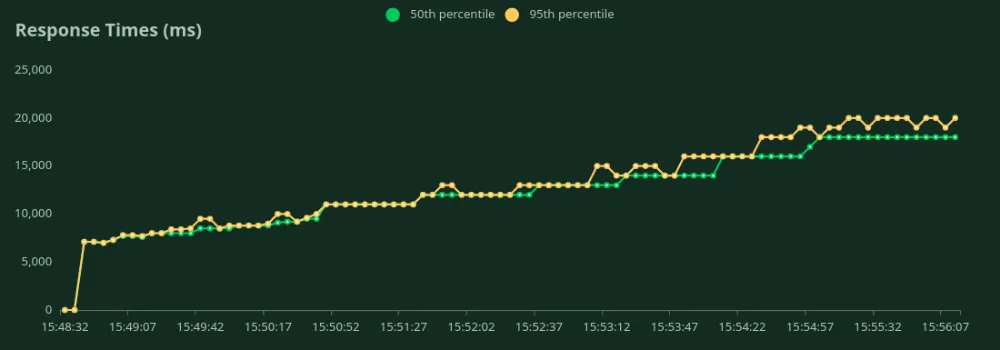
We can observe in the above graphs that the Best Response Time (at 1 user) is 7.4 seconds. We can increase the number of users to throw more traffic at the model - we can see the throughput increasing till 1.1 RPS without a significant drop in latency. Beyond 1.1 RPS, the latency increases drastically which means requests are being queued up.
4 x A100 40GB GPU (50 input + 500 output tokens)
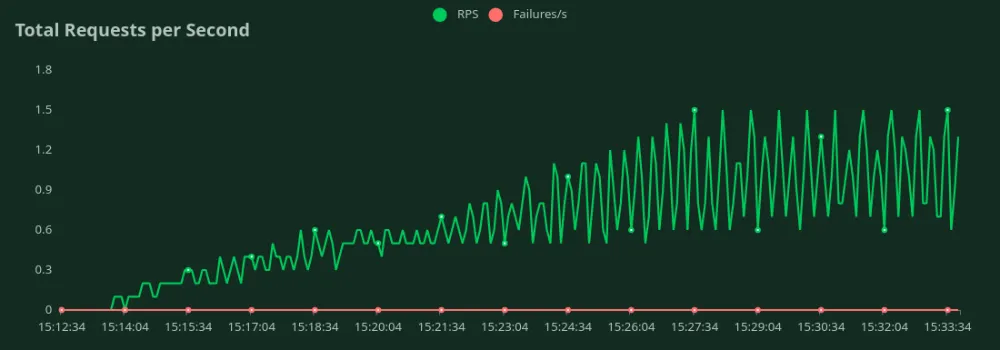
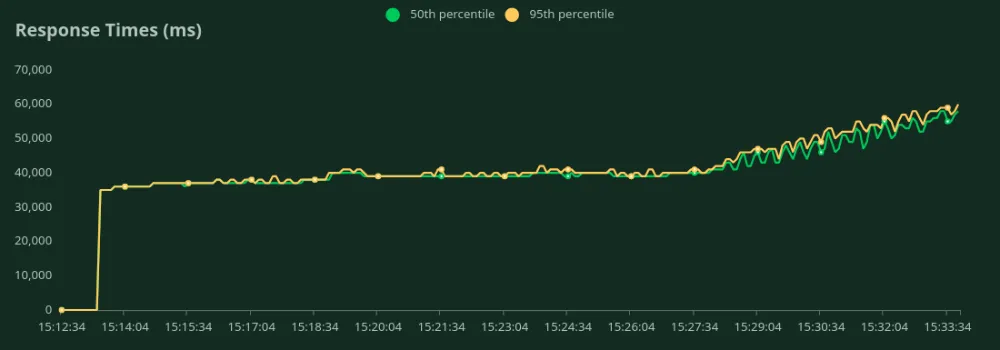
We can observe in the above graphs that the Best Response Time (at 1 user) is 33 seconds. We can increase the number of users to throw more traffic at the model - we can see the throughput increasing till 0.8 RPS without a significant drop in latency. Beyond 0.8 RPS, the latency increases drastically which means requests are being queued up.
Hopefully, this will be useful for you to decide if LLama2-70B will suit your use case and the costs you can expect to incur while hosting LLama2-70B.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.







.webp)














.webp)
.webp)
.webp)
.webp)
.webp)

.webp)