June 4, 2026
|
5 min read

Updated: October 26, 2023

Blazingly fast way to build, track and deploy your models!
We are back with another episode of True ML Talks. In this, we again dive deep into MLOps and LLMs Applications at GitLab and we are speaking with Monmayuri Ray.
Monmayuri leads the AI research vertical at GitLab with a lot of focus on the LLMs over the last one year. And prior to that, she was an engineering manager in the ModelOps Division at GitLab. She also worked with other companies like Microsoft, eBay.
📌
Our conversations with Monmayuri will cover below aspects:
- ML and LLM use cases at GitLab
- GitLab's ML infrastructure evolution to support large language models (LLMs)
- GitLab's Journey with LLMs: From Open Source to Fine-Tuning
- Training Large Language Models at GitLab
- Triton vs. PyTorch, Ensembled GPUs, and Dynamic Batching for LLM Inference
- Challenges and Research in Evaluating LLMs at GitLab
- GitLab's LLM Architecture and the Future of LLMs
Machine learning (ML) is transforming the software development lifecycle, and GitLab is at the forefront of this innovation. GitLab is using ML to empower developers throughout their journey, from creating issues to merging requests to deploying apps.
One of the most exciting use cases for ML at GitLab is large language models (LLMs). GitLab is using LLMs and GenAI to develop new features for its products, such as code completion and issue summarization.
GitLab has been at the forefront of using large language models (LLMs) to empower developers. As a result, GitLab has had to evolve its ML infrastructure to support these complex models.
To address the challenges mentioned above, GitLab has made a number of changes to its ML infrastructure. These changes can be categorized into the following areas:
GitLab has been at the forefront of using large language models (LLMs) to empower developers. In the early days, GitLab started by using open source LLMs, such as Salesforce code gen. However, as the landscape has changed and LLMs have become more powerful, GitLab has shifted to fine-tuning its own LLMs for specific use cases, such as code generation.
Fine-tuning LLMs requires a significant investment in infrastructure, as these models are very large and complex. GitLab has had to develop new training and deployment pipelines for LLMs, as well as new ways to manage its ML infrastructure in a distributed environment.
One of the key challenges that GitLab has faced in fine-tuning LLMs is finding the right balance between cost and latency. LLMs can be very expensive to train and deploy, and they can also be slow to generate results. GitLab has had to experiment with different cluster sizes, GPU configurations, and batching techniques to find the right balance for its needs.
Another challenge that GitLab has faced is ensuring that its LLMs are accurate and reliable. LLMs can be trained on massive datasets of text and code, but these datasets can also contain errors and biases. GitLab has had to develop new techniques to evaluate and debias its LLMs.
Despite the challenges, GitLab has made significant progress in using LLMs to empower developers. GitLab is now able to train and deploy LLMs at scale, and it is using these models to develop new features and products that will make the software development process more efficient and enjoyable.
Training large language models (LLMs) is a challenging task that requires a significant investment in infrastructure and resources. GitLab has been at the forefront of using LLMs to empower developers, and the company has learned a lot along the way.
Here are some insights and lessons learned from GitLab's experience training LLMs:
In addition to the above insights, GitLab has also learned a number of valuable lessons about the importance of having a good understanding of the base model and the training data. For example, GitLab has found that it is important to know the construct of the base model and how to curate the training data to optimize for the desired use case.
GitLab uses Triton for LLM inference because it is better suited for scaling to the high volume of requests that GitLab receives. Triton is also easier to wrap and scale than other model servers, such as PyTorch servers.
GitLab has not yet experimented with Hugging Face's TGI or VLLM model servers, as these were still in the early stages of development when GitLab first deployed its LLM inference pipeline.
When it comes to dynamic batching, GitLab's strategy is to optimize for the specific use case, load, query level, volume, and number of GPUs available. For example, if GitLab has 500 GPUs for a 7B model, it can use a different batching strategy than if it only has a few GPUs for a smaller model.
GitLab also uses an ensemble of GPUs to handle requests. This means that GitLab uses a mix of different types of GPUs, including high-performance GPUs and lower-performance GPUs. GitLab load balances requests across the ensemble of GPUs to optimize for performance and cost.
Here are some tips for designing an architecture to ensemble GPUs and optimize load balancing:
Here are some specific examples of how GitLab has optimized its architecture for ensembled GPUs and dynamic batching:
By following these tips, you can design an architecture that can efficiently handle large volumes of LLM inference requests.
We have tried streaming as well, and I think we are looking into streamings for our third parties as well - Monmayuri
Evaluating the performance of large language models (LLMs) is a challenging task. GitLab has been working on this problem and has faced several challenges, including:
GitLab is addressing these challenges by:
GitLab's goal is to develop a scalable and data-driven approach to evaluating LLMs. This approach will help GitLab to ensure that its LLMs are performing well in production and meeting the needs of its users.
GitLab is also conducting research on new ways to evaluate LLMs. Some of the research directions that GitLab is exploring include:
GitLab's research on evaluating LLMs is ongoing. GitLab is committed to developing new and innovative ways to evaluate LLMs so that it can ensure that its LLMs are meeting the needs of its users.
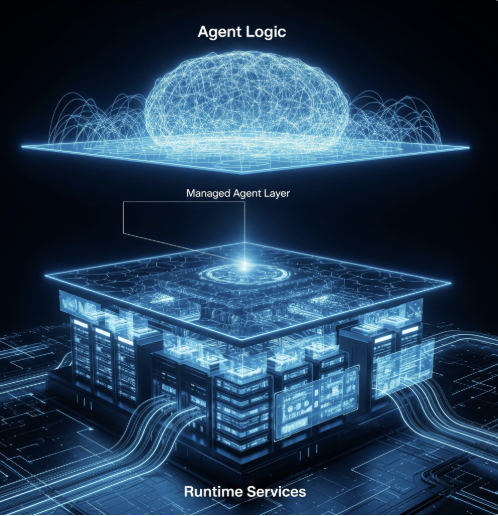
GitLab's LLM architecture is a comprehensive approach to training, evaluating, and deploying LLMs. The architecture is designed to be flexible and scalable, so that GitLab can easily adopt new technologies and meet the needs of its users.

The architecture consists of several key components:
GitLab's LLM architecture is a powerful tool that enables GitLab to train, evaluate, and deploy LLMs at scale. The architecture is designed to be flexible and scalable, so that GitLab can easily adopt new technologies and meet the needs of its users.
LLMs are still a relatively new technology, but they have the potential to revolutionize many industries. GitLab believes that LLMs will have a significant impact on the software development industry.
GitLab is already using LLMs to improve its products and services. For example, GitLab is using LLMs to generate code suggestions, explain vulnerabilities, and improve the user experience of its products.
GitLab believes that other organizations should also invest in LLMs. LLMs have the potential to improve productivity, efficiency, and quality in many industries.
GitLab recommends that organizations invest in the following areas to stay ahead of the curve in the LLM space:
By investing in these areas, organizations can stay ahead of the curve in the LLM space and reap the benefits of this powerful technology.
Keep watching the TrueML youtube series and reading the TrueML blog series.
TrueFoundry is a ML Deployment PaaS over Kubernetes to speed up developer workflows while allowing them full flexibility in testing and deploying models while ensuring full security and control for the Infra team. Through our platform, we enable Machine learning Teams to deploy and monitor models in 15 minutes with 100% reliability, scalability, and the ability to roll back in seconds - allowing them to save cost and release Models to production faster, enabling real business value realisation.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.





.webp)

.webp)
.webp)
.webp)




.webp)
.webp)