



December 24, 2025
|
5 min read

As AI platforms become deeply embedded in enterprise workflows, data residency has moved from a legal footnote to a core architectural concern. Unlike traditional SaaS applications, AI systems continuously process sensitive inputs - prompts, documents, source code, customer data—and often generate derived data such as embeddings, logs, and fine-tuned models.
At the same time, many AI platforms abstract away infrastructure details in the name of developer convenience. While this makes experimentation easier, it often leaves enterprises unclear about where their data is actually processed, stored, or transmitted.
This lack of clarity becomes a problem as organizations scale AI into production, especially in regulated industries or regions with strict data protection requirements. Questions around cross-border data flow, inference location, and auditability can no longer be answered with generic claims like “we don’t store your data.”
This blog provides a practical data residency comparison for AI platforms, focusing on how different deployment models affect where AI data lives and what enterprises should look for when evaluating platforms.
Data residency refers to the requirement that data must be stored and processed within specific geographic or jurisdictional boundaries. In the context of AI platforms, this concept extends far beyond simple database location.
AI systems typically handle multiple categories of data, including:
Data residency for AI therefore depends on where each of these data types is processed and stored, not just where the platform’s primary database resides.
This is where confusion often arises. An AI platform may claim:
While these claims may be true, they do not automatically guarantee data residency. If inference runs in another region, if logs are exported cross-border, or if embeddings are generated and stored elsewhere, residency requirements may still be violated.
In practice, data residency in AI is an infrastructure-level property, determined by:
Understanding this distinction is critical before comparing AI platforms on their data residency guarantees.
Data residency is not just a legal requirement - it directly impacts risk, trust, and system design for AI platforms operating at scale.
Regulations such as GDPR, ITAR, HIPAA, and region-specific data protection laws impose strict rules on where data can be processed and stored. For AI systems, these obligations apply not only to stored data, but also to transient processing during inference.
Many organizations discover compliance gaps when:
Without strong residency guarantees, compliance becomes difficult to prove - even if no data is “persisted.”
AI workloads often involve highly sensitive inputs: proprietary documents, internal code, customer conversations, or strategic data. Cross-region or third-party processing increases exposure and makes threat modeling harder.
Data residency helps reduce risk by:
For many enterprises, especially in regulated industries, where inference runs is as important as how it runs.
As AI platforms become core infrastructure, enterprises must assess vendor risk more carefully. This includes understanding:
Vague assurances are no longer sufficient. Enterprises increasingly require architectural clarity to build trust in AI platforms.
As organizations deploy AI across multiple geographies, inconsistent residency controls can lead to fragmented architectures or duplicated systems. Platforms that support clear, enforceable data residency make it easier to scale AI responsibly across regions and business units.
In short, data residency matters for AI platforms because it shapes compliance posture, security risk, and long-term scalability. Any meaningful comparison of AI platforms must start by examining how and where AI data actually flows.
To meaningfully compare data residency across AI platforms, enterprises need to look beyond surface-level claims and evaluate where control actually exists. The following dimensions provide a practical framework for comparison.
The deployment model largely determines how much control an organization has over data residency.
The closer the platform runs to your infrastructure, the stronger the residency guarantees typically are.
Not all platforms allow customers to choose where inference runs. Some abstract this away entirely.
Key questions include:
Inference location is often the most overlooked but most critical residency factor.
AI platforms handle multiple types of data beyond inference inputs.
When comparing platforms, assess:
True residency support applies to all persisted and derived data, not just primary inputs.
Some platforms support regional deployment but still allow internal cross-region data transfer.
Stronger platforms provide:
Without these controls, residency relies on trust rather than enforcement.
Enterprises must be able to demonstrate where data lives.
This includes:
Auditability is essential for regulated industries and enterprise risk management.
Finally, there is a trade-off between control and complexity.
Understanding this trade-off helps teams choose a platform that balances compliance needs with operational capacity.
As enterprises evaluate AI platforms, data residency is often misunderstood or oversimplified. These are some of the most common gaps that surface in practice.
Many platforms claim they do not persist prompts or responses. While this may reduce storage risk, it does not guarantee residency. If inference or transient processing occurs outside approved regions, residency requirements may still be violated.
Data residency applies to processing location, not just long-term storage.
Hosting a platform in a specific region does not automatically mean data stays there. Without technical controls, data may still:
Residency guarantees must be enforced by architecture, not assumed from hosting location.
Some platforms rely on SDK-level configurations or application logic to manage data flow. This approach breaks down at scale, especially across teams.
True residency requires infrastructure-level controls that apply uniformly, regardless of how individual applications are built.
Model training policies and data residency are often conflated. A platform may not use customer data for training, yet still process that data outside required jurisdictions.
Training policies address data usage. Residency addresses data location. Both matter, but they solve different problems.
Even when platforms intend to support residency, enterprises may struggle to prove compliance without visibility into data flow.
Without audit-friendly controls and documentation, residency claims become difficult to verify—especially during regulatory reviews.
Understanding these gaps helps enterprises move past surface-level assurances and evaluate AI platforms based on how data actually flows in production systems.
As AI systems move from experimentation into production, many enterprises discover that cloud-only AI platforms do not provide sufficient guarantees around where data is processed, stored, and observed. This gap becomes especially visible when AI workloads expand across multiple teams, environments, regions, and regulatory jurisdictions.
In early stages, abstracted platforms can be sufficient. But at scale, enterprises need answers to harder questions:
This is where TrueFoundry fits.
TrueFoundry treats data residency as an infrastructure-level property, not an application-level configuration. Instead of relying on SDK flags or per-app logic, residency is enforced through where and how the platform itself is deployed and operated.
Its AI Gateway and deployment platform are designed to give enterprises explicit, verifiable control over:
This shifts residency from something developers must remember to configure into something that is guaranteed by design.
Enterprises rarely have a single residency posture across all AI workloads. TrueFoundry supports this reality by enabling multiple deployment models under a single control plane:
Crucially, this flexibility does not require teams to adopt different platforms for different workloads. The same gateway, governance model, and operational workflows apply across deployments, reducing fragmentation and operational overhead.
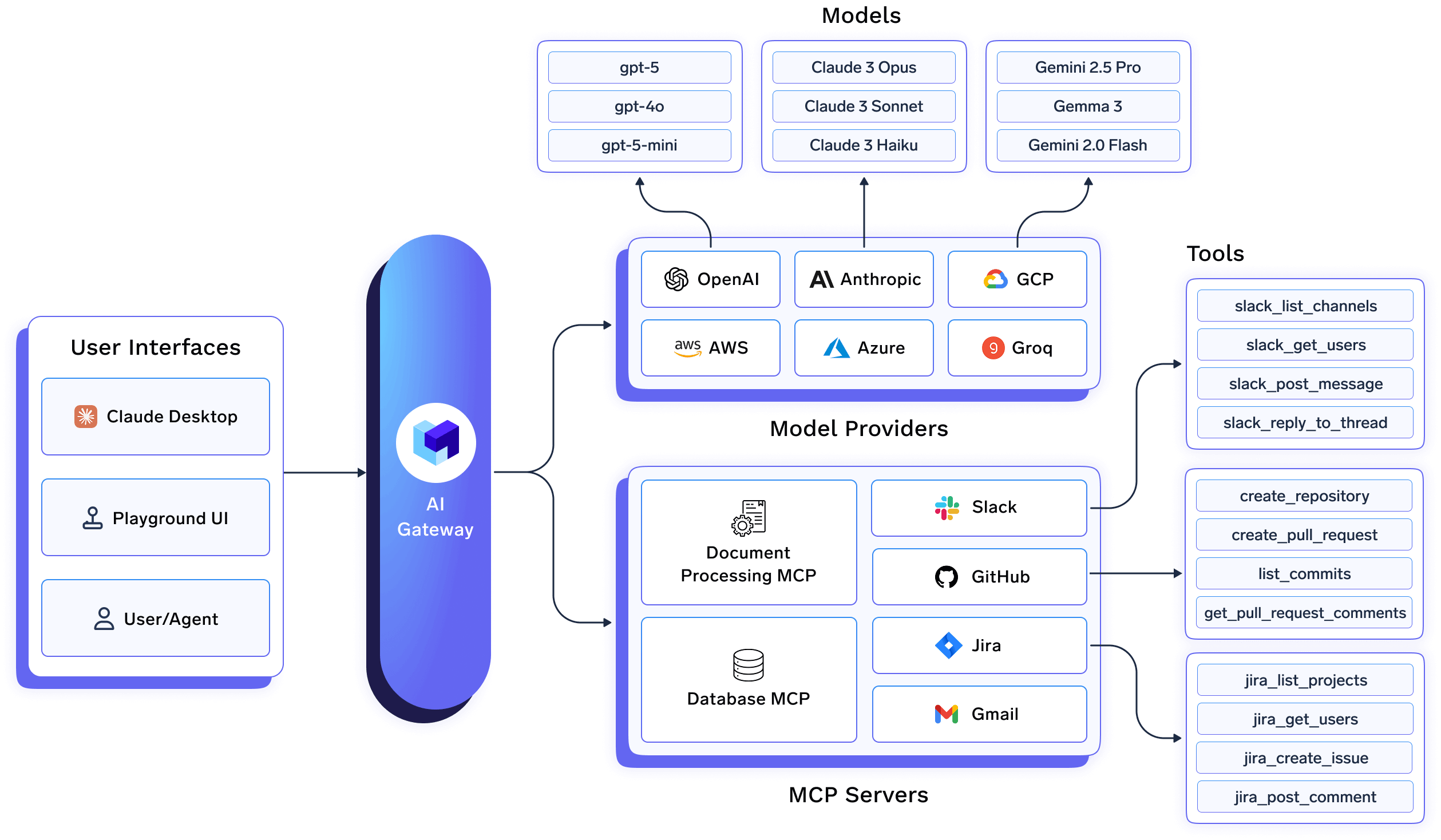
At the gateway and infrastructure layer, TrueFoundry enables enterprises to enforce residency through technical controls, not policy alone:
Because these controls live at the platform layer, individual applications do not need to implement or maintain residency logic themselves.
At scale, embedding data residency logic inside each application does not work. It leads to:
TrueFoundry’s approach allows enterprises to treat LLM access as shared, governed infrastructure. Residency policies, auditability, and deployment boundaries are defined once and enforced centrally, regardless of how many teams or applications consume AI.
For organizations operating in regulated industries or across multiple geographies, this architectural clarity is often the difference between AI that scales responsibly and AI systems that stall under compliance and risk constraints.
Data residency is no longer a secondary concern for AI platforms—it is a foundational requirement for enterprises deploying AI in production. Unlike traditional software, AI systems continuously process sensitive inputs and generate derived data, making it critical to understand where data is processed, stored, and allowed to move.
This comparison shows that data residency support varies significantly across AI platforms. Cloud-only platforms prioritize speed and simplicity but offer limited control. VPC-based platforms improve guarantees but still involve trade-offs. On-prem and air-gapped deployments provide the strongest assurances, at the cost of higher operational responsibility.
For enterprises, the right choice depends on regulatory obligations, risk tolerance, and scale. What matters most is moving beyond vague claims and evaluating platforms based on deployment model, inference location control, data flow enforcement, and auditability.
Platforms like TrueFoundry address this need by treating data residency as an infrastructure-level capability—allowing organizations to scale AI responsibly while maintaining clarity, control, and compliance as AI becomes core to the business.
Blazingly fast way to build, track and deploy your models!
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.







The latest news, articles, and resources sent to your inbox
© 2025 All rights reserved.





