January 10, 2026
|
5 min read

In the early 2010s, the microservices revolution hit a wall. We had broken our monoliths into hundreds of services, but we hadn't agreed on how they should talk. Some teams used REST, others XML-RPC, others raw TCP. The result was a "Tower of Babel"—a fragmented ecosystem where integration was painful and observability was impossible.
The industry fixed this with standardization: gRPC for the transport, Protobuf for the schema, and OpenTelemetry for the observability.
Today, the Agentic AI ecosystem is in that exact pre-standardization chaos.
These agents cannot naturally collaborate. They have different state representations, different error handling mechanisms, and no shared concept of identity.
To solve this, TrueFoundry introduces the support for A2A (Agent-to-Agent) Protocol. It is a strict transport layer that normalizes communication, turning a fragmented collection of scripts into a unified Cognitive Mesh.
The fundamental mistake in many early agent designs is treating agent-to-agent communication like a simple API call (POST /chat { "prompt": "..." }). This is insufficient because it lacks Meta-Cognition.
An agent doesn't just need the text of the message. It needs to know:
The A2A Protocol solves this by wrapping every interaction in a standardized Envelope. We treat the agent's business logic (the prompt) as the Payload, but we wrap it in a rigid Control Plane.
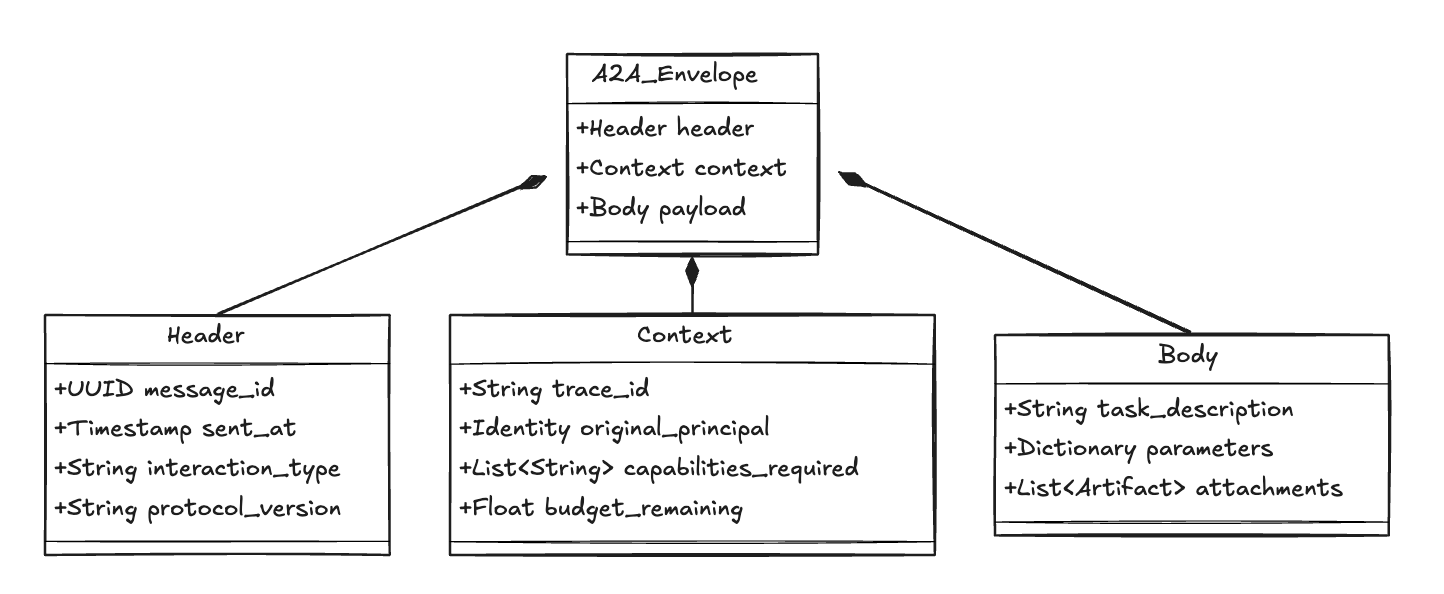
Fig 1: A2A Envelope its Underlying Structure
To illustrate the power of this protocol, let’s look at a complex, multi-stack scenario: An M&A Due Diligence System.
This system requires three highly specialized agents running on completely different technology stacks:
Without a protocol, the Python Manager cannot easily trigger the AutoGen team. AutoGen expects a specific conversation history format, while LangChain expects a "Chain." If the Legal Reviewer (Node) throws an error, the Python Manager might interpret it as a hallucination rather than a system fault.
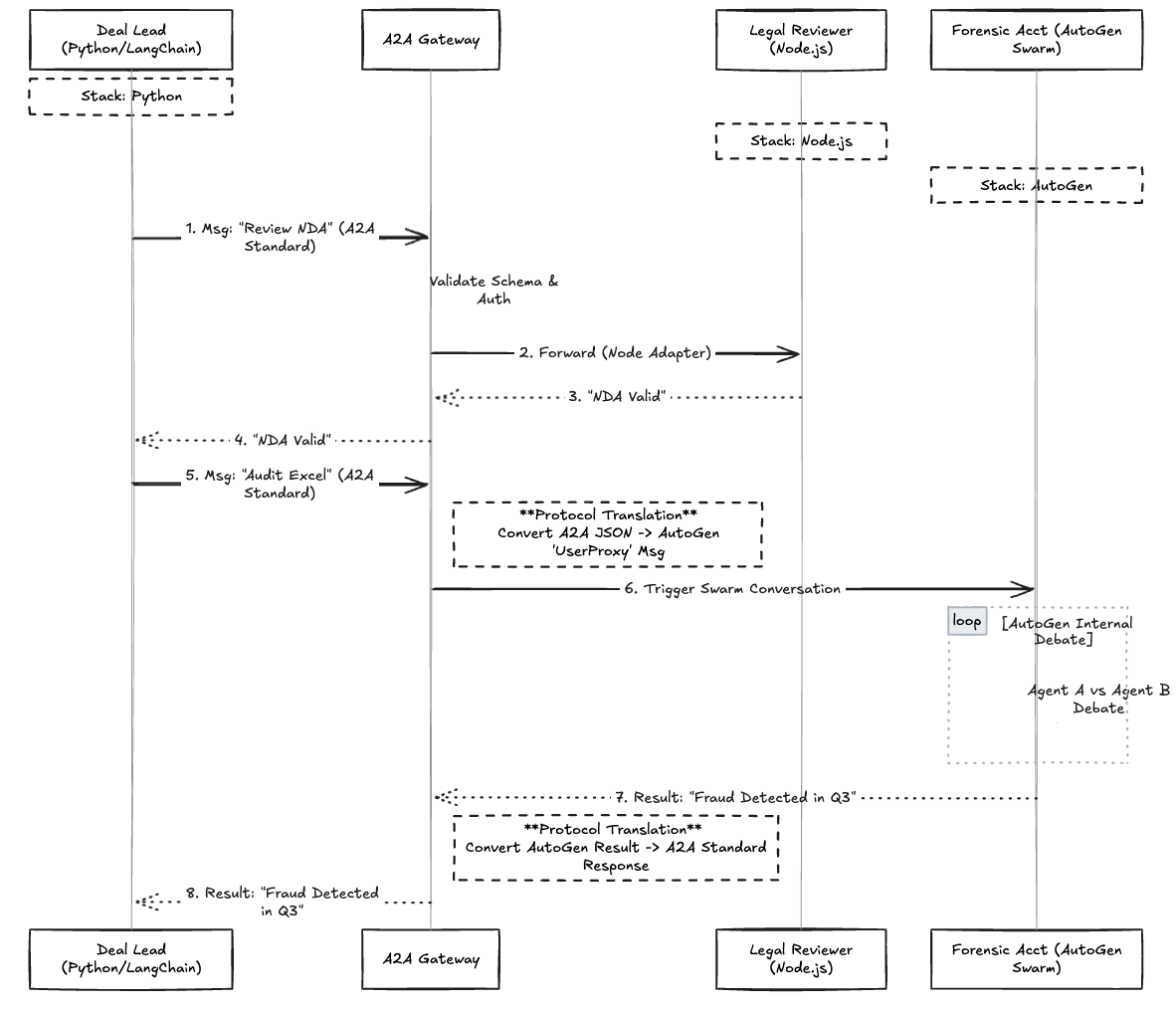
Fig 2: The Detailed Flow of A Legal Reviewing Process
In a peer-to-peer agent mesh, Agent A calls Agent B directly. This is dangerous because it breaks observability and security. If Agent A is compromised, it can flood Agent B with requests, and no one will know until the bill arrives.
The A2A Protocol enforces a Hub-and-Spoke model.

Debugging a single LLM is hard. Debugging a recursive chain of 5 agents is impossible without distributed tracing.
When the "Deal Lead" fails to close the M&A deal, you need to know why. Was it a timeout in the Legal agent? Did the Forensic Accountant run out of tokens?
The A2A Protocol mandates Header Propagation. When the Gateway receives the initial request, it generates a TraceID. It forces every downstream agent to include this ID in its sub-calls.
This allows us to visualize the "Thought Stack"—a temporal Gantt chart of cognition. We can see that the Legal Agent took 45 seconds (latency bottleneck) while the Accountant took 2 seconds.

Fig 3: Gantt Chart of this M&A Deal
The final piece of the A2A Protocol is the Universal Adapter.
We acknowledge that developers will always use different tools. Some love LangGraph for its control; others prefer CrewAI for its role-playing features.
The Gateway acts as a Translation Layer.
This allows you to build a Heterogeneous Agent Mesh. You are not locked into a single Python library. You can pick the best tool for each specific agent's job and let the Protocol handle the communication.
Standardization is the prerequisite for scale. Just as TCP/IP allowed the internet to connect different computers, the A2A Protocol plus TrueFoundry AI agent gateway capabilities allow the enterprise to connect different intelligences. It turns a collection of "Chatbots" into a coordinated, observable, and secure Digital Workforce.
Blazingly fast way to build, track and deploy your models!
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.







The latest news, articles, and resources sent to your inbox
© 2025 All rights reserved.