@task decorator as other workflow tasks, but pass task_config=PySparkTaskConfig(...) so the task is executed as a Spark job. The task gets a SparkSession from the execution context (e.g. flytekit.current_context().spark_session), which you use for all Spark operations.
Install the TrueFoundry workflow SDK with Spark support. This adds the workflow and spark extras so you can use PySparkTaskConfig and run Spark tasks.
PySparkTaskConfig
Spark version and optional build options (e.g.
spark_version, pip_packages, requirements_path).Driver resources (e.g.
resources).Executor config with
instances: SparkExecutorFixedInstances (e.g. count=2) or SparkExecutorDynamicScaling (e.g. min=1, max=10), and optional resources for executors.Extra Spark config (e.g.
{"spark.sql.shuffle.partitions": "200"}).Environment variables (plain or secret refs).
mounts
Volume mounts for the task.
Kubernetes service account name to use. The service account should have the required permissions (e.g. AWS S3 read/write).
TaskPySparkBuild (for image)
Spark version (default
"3.5.2"). Should match the Spark version installed in the image.FQN of the container registry. If you can’t find your registry here, add it through the Integrations page.
Path to
requirements.txt relative to the path to build context.Pip package requirements (e.g.
["fastapi>=0.90,<1.0", "uvicorn"]).Debian packages to install via
apt-get (e.g. ["git", "ffmpeg", "htop"]).Getting the session from the execution context
The Spark task plugin creates a SparkSession before your task runs. Inside the task, get the session from the Flyte execution context:spark_session for all Spark operations in the task.
Example
Usetruefoundry[workflow,spark] in all task images in this file (including non-Spark tasks in the example below). When Flyte loads the module for any task, it imports the whole file, so PySparkTaskConfig and Spark tasks must be importable; the [workflow,spark] extra pulls in pyspark. Non-Spark tasks still need it in their image so the module loads correctly.
flytekit.current_context().spark_session.
Viewing Spark UI
From the workflow run you can open the Spark UI to monitor your Spark job. The workflow UI shows a button to open the Spark UI:
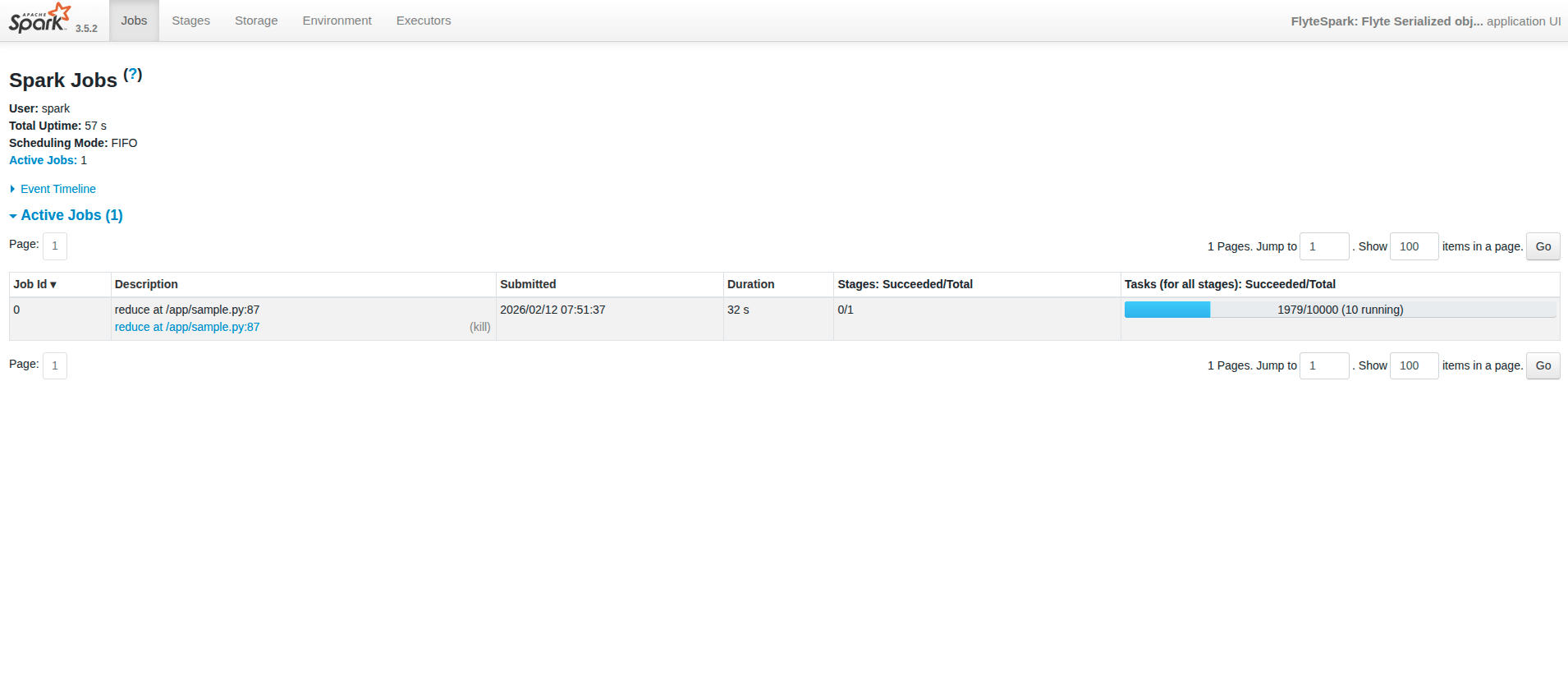
- Spark UI may take up to ~1 minute to become live while the Spark UI page is setting up.
- Once a job is done, the history server is enabled, so you can view past jobs.
- If the UI shows “not found”, try opening it again by clicking the Spark UI button from the workflow UI.
Checklist
- Use
@task(task_config=PySparkTaskConfig(...))withimage,driver_config, andexecutor_config. imageisTaskPySparkBuild(includesspark_version).driver_config=SparkDriverConfig;executor_config=SparkExecutorConfig(withinstances= fixed or dynamic).- Task code gets the SparkSession via
flytekit.current_context().spark_session. - Register the task in a
@workflowand call it like any other task (e.g.my_spark_task(partitions=4)).