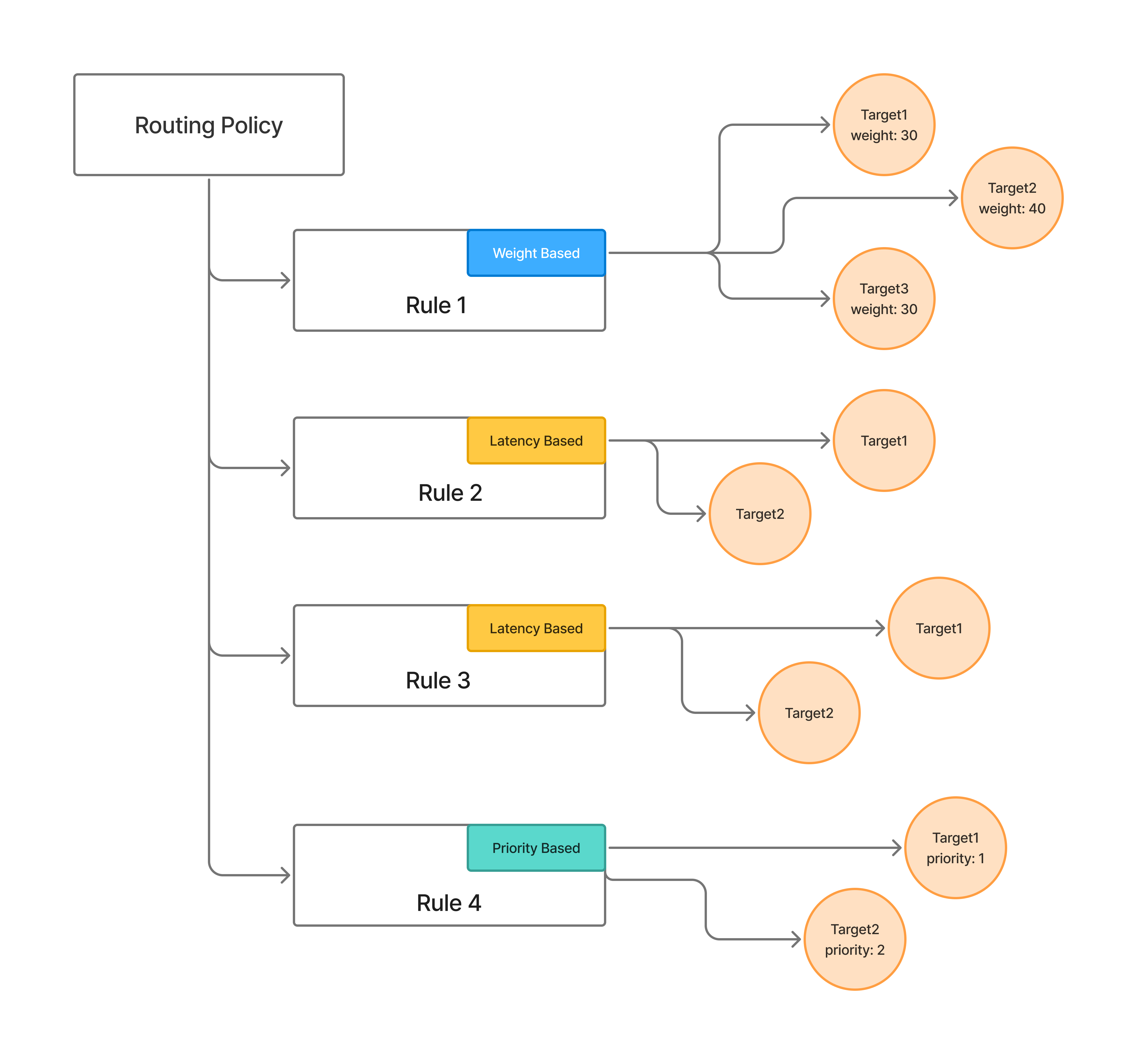
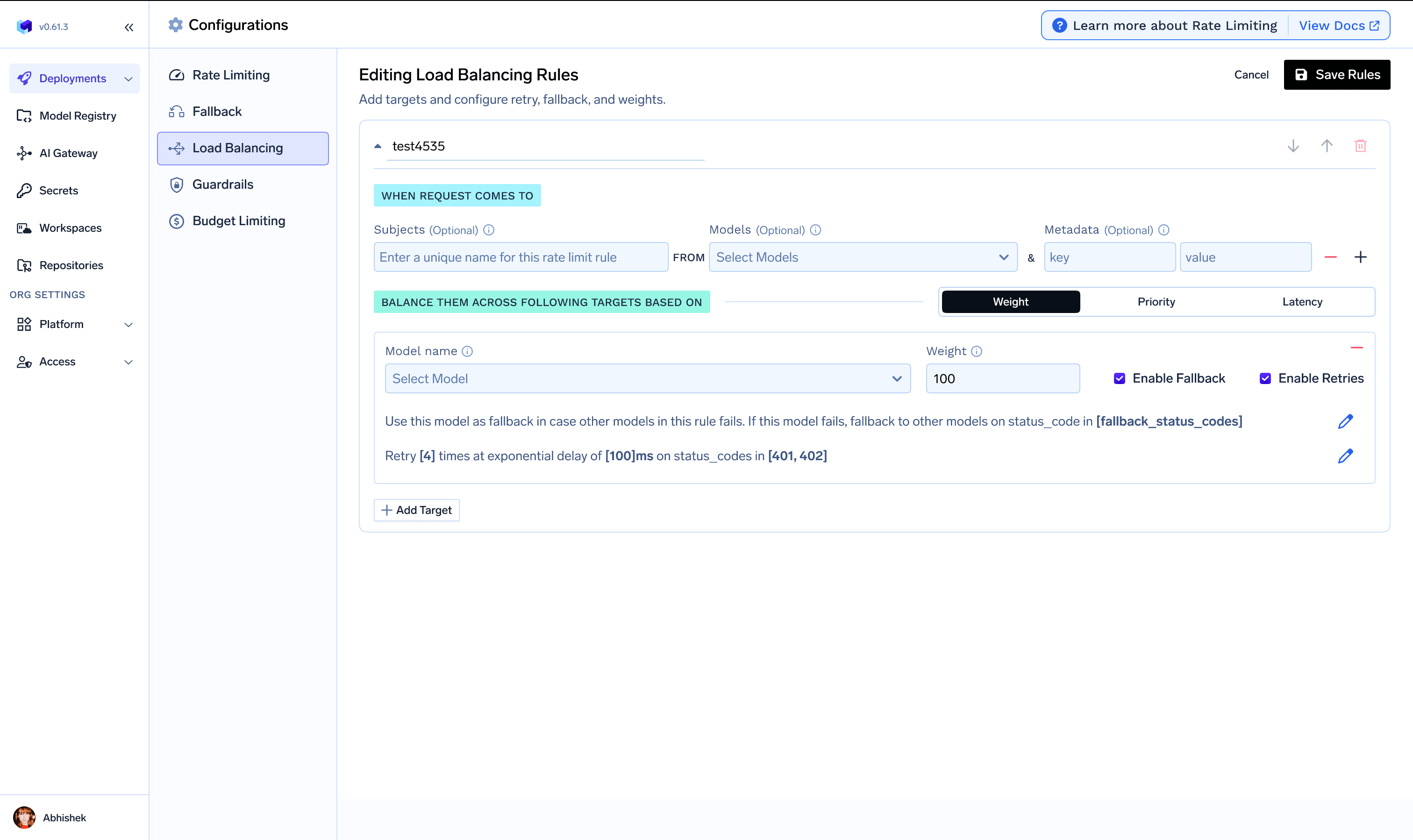
Configuration structure
Key fields
when — Defines which requests a rule applies to. The subjects, models, and metadata fields are combined with AND logic. If a request doesn’t match one rule’s when block, the next rule is evaluated.
subjects— Filter by user, team, or virtual account (for exampleuser:john-doe,team:engineering,virtualaccount:acct_123).models— Rule matches if the request model name is in this list.metadata— Rule matches if the request’sX-TFY-METADATAheader contains these key-value pairs.
type — The routing strategy for this rule:
weight-based-routing— Distribute traffic by assigned weights that sum to 100.latency-based-routing— Automatically route to the target with the lowest recent latency (time per output token).priority-based-routing— Route to the highest priority (lowest number) healthy target, falling back to the next on failure.
load_balance_targets — The list of models eligible for routing in this rule. Per-target options:
- Retry configuration —
attempts,delay, andon_status_codesfor retries on the same target. - Fallback configuration —
fallback_status_codesto trigger trying another target, andfallback_candidateto control whether a target can receive fallback traffic. - Override parameters — Per-target request parameters like
temperature,max_tokens, orprompt_version_fqnfor model-specific prompts.
For Anthropic streaming requests, fallback can trigger on
overloaded_error before output starts. The gateway waits for the first non-empty stream chunk; if an overloaded_error is returned before that first chunk, it falls back to the next eligible target. See Anthropic Stream Overload Fallback for implementation details.prompt_version_fqn override does not work with agents (when using MCP/tools). It is supported for standard chat completion requests.Common configurations
Priority chain — fail over on rate limit
Priority chain — fail over on rate limit
Canary rollout with weight-based routing
Canary rollout with weight-based routing
On-prem primary with cloud fallback
On-prem primary with cloud fallback
Latency-based routing with retries
Latency-based routing with retries
Environment-based routing using metadata
Environment-based routing using metadata
Different prompt versions per provider
Different prompt versions per provider
Subject and region-based routing
Subject and region-based routing
Where to configure
The configuration is managed under AI Gateway → Configs → Routing Config in the UI. You can also store the YAML in your Git repository and apply it with thetfy apply command to enforce a PR review process.
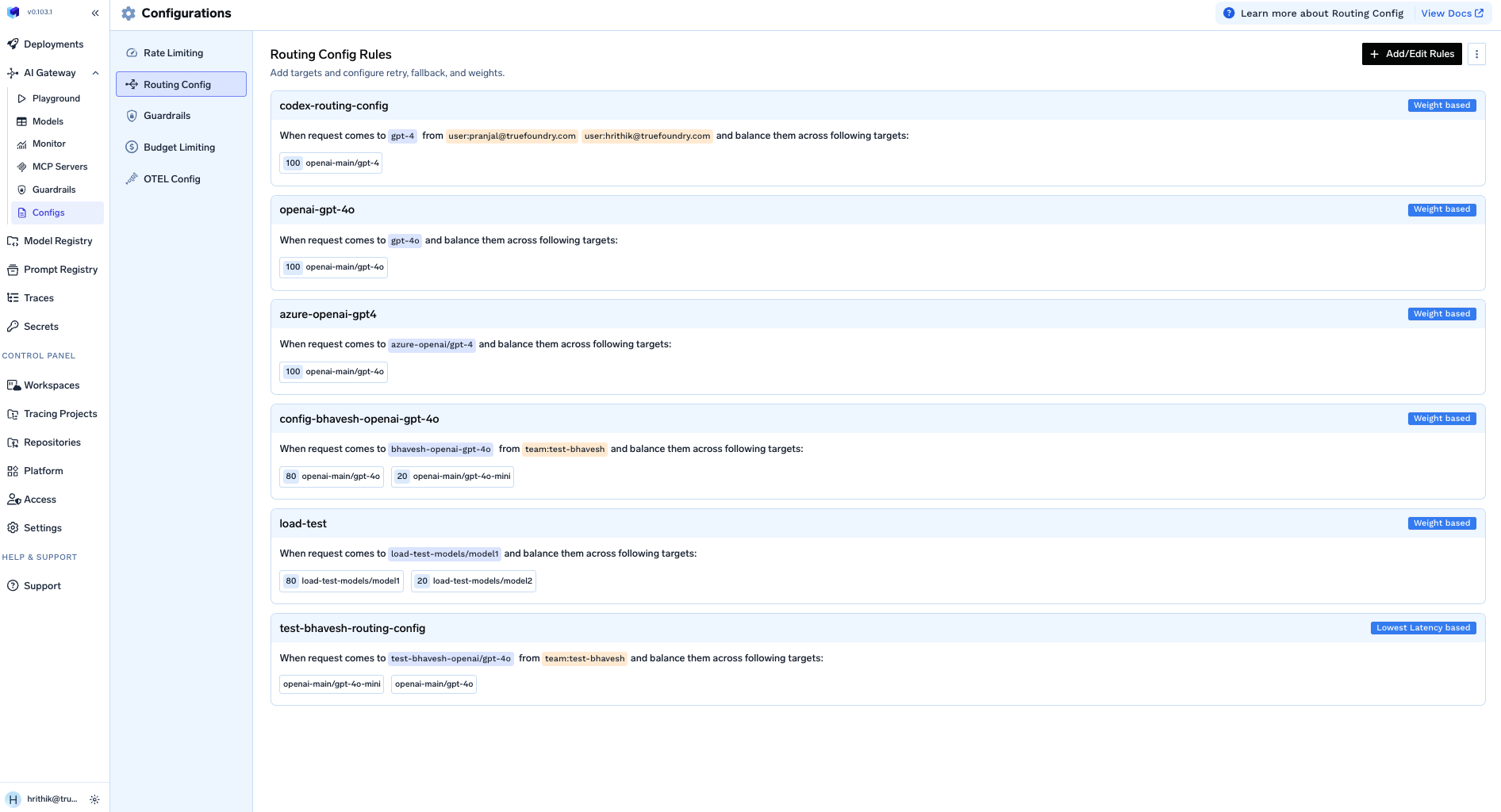
Migrating to virtual models
To move from global routing config to virtual models:- Identify each distinct
modelyour apps send that is backed by rules here. - Create a virtual model with the same targets, strategy, weights/priorities, retries, fallbacks, and
override_params. - Point clients at the virtual model using its full path or a slug.
- Remove or narrow rules here once traffic uses the virtual model.
metadata or subjects, use different virtual model names per team or environment (for example booking-app/gpt-prod vs booking-app/gpt-dev).
See Virtual Models for the full guide.